
CNN (2) CNN종류
ImageNet
이미지넷(ImageNet)은 1000개가 넘는 카테고리로 분류된 100만개의 이미지를 인식하여 그 정확도를 겨루는 대표적인 시각지능 대회이다.
아래 그림을 보게 되면 지난 ImageNet대회에서 우승한 Model의 오차율에 대하여 나타내고 있다.

이러한 대회에서 우승을 차지한 몇가지의 대표적인 CNN의 모델에 대해서 알아보자.
Alexnet
AlexNet은 2개의 GPU로 병렬연산을 수행하기 위하여 병렬적인 구조로 설계되었다는 점이 큰 특징이다. 구조는 아래 그림과 같다.

그림에서의 위쪽부분은 1번째 GPU에서 수행하는 연산, 아래쪽 부분은 2번째 GPU에서 수행하는 연산을 의미한다.
AlexNet은 5개의 Convolution Layer와 3개의 Full-Connected Layer로 구성되어있다.
또한 3번째 Convolution Layer는 전 단계의 두 채널의 Feature Map과 모두 연결되어 있다.
각각의 층 이름과 파라미터, 출력 결과를 표 형태로 나타내면 다음과 같다.
| Input Layer | 없음 | 출력 결과 |
| CONV1 |
|
277 X 277 X 3 |
| MAX_POOL1 |
|
55 X 55 X 96 |
| CONV2 |
|
27 X 27 X 96 |
| MAX_POOL2 |
|
27 X 27 X 256 |
| CONV3 |
|
13 X 13 X 256 |
| CONV4 |
|
13 X 13 X 384 |
| CONV5 |
|
13 X 13 X 384 |
| MAX POOL3 |
|
6 X 6 X 256 |
| FC6 |
|
4096 |
| FC7 |
|
4096 |
| FC8 |
|
4096 |
VGG
VGGNet은 2014년 준우승을 차지한 Model이다. 구조는 아래 그림과 같다.
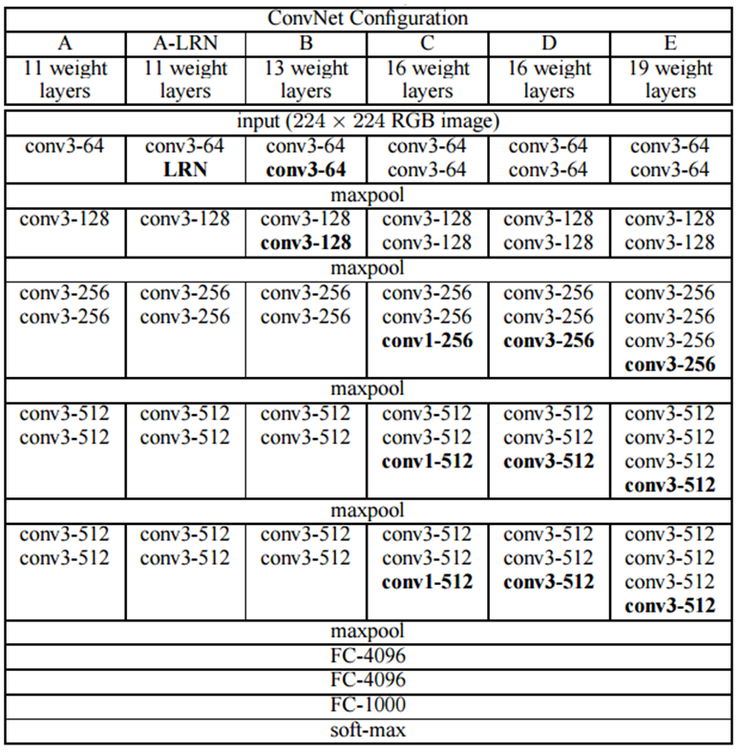
VGG를 살펴보게 되면 특이한 점이 있다.
VGG는1 x 1 Convolution을 사용하여 크기가 개별 픽셀 하나이므로 특징 추출효과는 거의 없다고 할 수 있다.
하지만 ReLU활성 함수를 적용하므로 Non-Linearity가 추가되어 모델의 표현력이 더욱 강해진 것이 특징이다.
또한 DeepNeuralNetwork를 구성하기 위하여 vainshing/ exploding gradient를 해결하기 위하여 11 layer의 비교적 간단한 구조를 학습한 뒤, 학습결과를 초기화 한 뒤 더 깊은 Layer를 쌓아 Model을 학습시킨 것으로 DeepNeuralNetwork를 구성하게 되었다.
우승을 차지하지 못하였지만 간단한 구조로서 우승을 차지한 GoogleNet보다 많이 사용된다.
GoogleNet
GoogleNet은 2014년 우승을 차지한 Model이다. 구조는 아래 그림과 같다.

위에서 빨간색 동그라미가 쳐져있는 부분은 Inception 모듈을 사용한 곳이다.
Inception 모듈
CNN의 망이 깊어짐에 따라 위에서 언급하였듯이 vainshing/ exploding gradient문제가 발생할 수 있다. 이러한 문제를 해결하기 위하여 Dropout을 사용하게 되지만 이러한 Dropout은 Netowrk처럼 sparse하는 구조를 만들 수 있다는 단점이 생기게 된다.
이러한 sparse한 구조가 아닌 Dense한 구조로서 연산을 빨리하기 위해 만들어진 Network Model이 Inception 모듈이다.
Inception 모듈의 구조는 아래와 같다.

Inception 모듈에서는 feature를 효율적으로 추출하기 위해 1x1, 3x3, 5x5의 Convolution 연산을 각각 수행합니다. 3x3의 Max pooling 또한 수행하는데, 입력과 출력의 H, W가 같아야하므로 Pooling 연산에서는 드물게 Padding을 추가해줍니다. 결과적으로 feature 추출 등의 과정은 최대한 sparse함을 유지하고자 했고, 행렬 연산 자체는 이들을 합쳐 최대한 dense하게 만들고자 했습니다. 그러나 위에서 언급했듯 이렇게 되면 연산량이 너무 많아지게 됩니다.
이러한 연상량이 많아지게 되는 문제점을 해결하기 위한 구조가 아래이다.

이렇게 말이죠. 이전의 입력을 1x1 Conv에 넣어 channel을 줄였다가, 3x3나 5x5 Conv를 거치게해 다시 확장하는 느낌입니다. 이렇게 되면 필요한 연산의 양이 확 줄어들게 됩니다. 또 Pooling의 경우 1x1 Conv를 뒤에 붙였는데요, 이는 Pooling연산의 결과 채널의 수가 이전의 입력과 동일하므로 이를 줄여주기 위함입니다. 이렇게 sparse하게 각 연산을 거친 다음, dense한 output을 만들어내는데요, H와 W는 모두 동일하다는 것에 주의해야합니다. 즉 Concat연산을 channel에 적용한다고 보시면 될 것 같습니다.
이전 CNN의 구조를 보게되면 Image에 1 x 1 Kernel을 적용시키므로 인하여 Channel의 수를 1개로 줄인 뒤 Convolution 연산을 하므로 많은 연산이 줄어든다는 것을 알 수 있다.
ResNet
ResNet은 2015년 우승을 차지한 Model이다. 구조는 아래 그림과 같다.
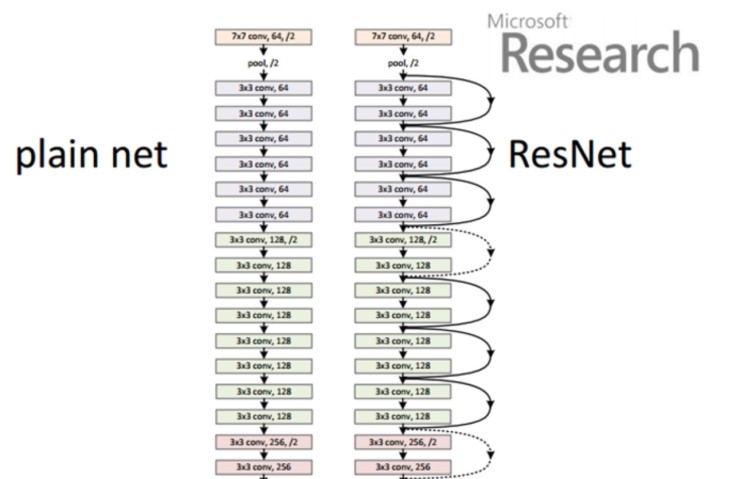
ResNet은 층의 깊이를 152층으로 획기적으로 늘린 모델이다.
이러한 층의 깊이를 늘릴수 있었던 원동력은 Residual Block이라는 모듈을 통해서 이다.
Residual Block의 구조는 아래와 같다.

위의 그림에서 구조는 LSTM과 비슷하다.
즉 Optimizer가 10만큼 학습을 진행해야 했던 상황에서 7만큼을 Skip Connection으로 미리 넘겨주어서 3만큼만 학습해도 되도록 만들어 주는 것 이다.
따라서 층의 깊이가 깊어져 학습해야 하는 파라미터의 수가 늘어나더라도 Optimizer가 최적의 파라미터를 찾아내 CNN의 성능을 더욱 향상시킬 수 있었다.
참조:bskyvision 블로그
참조:kangbk0120 블로그
참조:Laon People 블로그
참조:ratsgo’s 블로그
참조:밑바닥 부터 시작하는 딥러닝
참조:텐서플로로 배우는 딥러닝
문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment