
KoNLPy
KoNLPy
NLP (Natural Language Processing, 자연어처리)는 텍스트에서 의미있는 정보를 분석, 추출하고 이해하는 일련의 기술집합입니다.
KoNLPy는 여러분이 한국어 텍스트를 이용하여 기초적인 NLP 작업을 수행하는데 도움을 드릴 것입니다.
형태소 분석 및 품사 태깅
형태소 분석 이란 형태소를 비롯하여, 어근, 접두사/접미사, 품사(POS, part-of-speech) 등 다양한 언어적 속성의 구조를 파악하는 것입니다.
품사 태깅 은 형태소의 뜻과 문맥을 고려하여 그것에 마크업을 하는 일입니다.
다음은 형태소 분석 중에서 Kkma를 사용했을 경우이다.
1
2
3
4
kkma = Kkma()
pprint(kkma.sentences("여러분, 안녕! 반갑습니다."))
print(kkma.nouns("여러분, 안녕! 반갑습니다."))
print(kkma.pos("여러분, 안녕! 반갑습니다."))
['여러분, 안녕! 반갑습니다.']
['여러분', '안녕']
[('여러분', 'NP'), (',', 'SP'), ('안녕', 'NNG'), ('!', 'SF'), ('반갑', 'VV'), ('습니다', 'EFN'), ('.', 'SF')]
KoNLPy에는 Kkma외에 Okt, Komoran, Hannanum등이 존재 한다.
아래는 Okt를 사용했을 경우의 예시이다.
1
2
3
4
from konlpy.tag import Okt
okt = Okt()
print(okt.nouns("여러분, 안녕! 반갑습니다."))
print(okt.pos("여러분, 안녕! 반갑습니다."))
['여러분', '안녕']
[('여러분', 'Noun'), (',', 'Punctuation'), ('안녕', 'Noun'), ('!', 'Punctuation'), ('반갑습니다', 'Adjective'), ('.', 'Punctuation')]
형태소 분석에서 형태소만을 추출하는 함수가 있다.
- nouns(): 명사만을 추출하는 함수
- morphs(): 모든 품사를 추출하는 함수
- pos(): 단어 하나하나 품사를 명시해주는 함수
1
2
3
4
5
6
7
twitter = Okt()
wordlist = twitter.nouns("멋진 봄은 엄청 무더운 여름과 한들한들 시원한 바람이 부는 가을의 중간 계절이다")
print(wordlist)
wordlist2 = twitter.morphs("멋진 봄은 엄청 무더운 여름과 한들한들 시원한 바람이 부는 가을의 중간 계절이다")
print(wordlist2)
wordlist3 = twitter.pos("멋진 봄은 엄청 무더운 여름과 한들한들 시원한 바람이 부는 가을의 중간 계절이다")
print(wordlist3)
['봄', '여름', '바람', '가을', '중간', '계절']
['멋진', '봄', '은', '엄청', '무더운', '여름', '과', '한들한들', '시원한', '바람', '이', '부는', '가을', '의', '중간', '계절', '이다']
[('멋진', 'Adjective'), ('봄', 'Noun'), ('은', 'Josa'), ('엄청', 'Adverb'), ('무더운', 'Adjective'), ('여름', 'Noun'), ('과', 'Josa'), ('한들한들', 'Adverb'), ('시원한', 'Adjective'), ('바람', 'Noun'), ('이', 'Josa'), ('부는', 'Verb'), ('가을', 'Noun'), ('의', 'Josa'), ('중간', 'Noun'), ('계절', 'Noun'), ('이다', 'Josa')]
다음 예제는 웹스크래핑 후 형태소를 분석하는 예제이다.
웹스크래핑을한 URL:위키백과
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import urllib.request
from bs4 import BeautifulSoup
from konlpy.tag import *
from urllib import parse
kkma = Kkma()
twitter = Okt()
hana = Hannanum()
sdata = parse.quote("이순신")
url = "https://ko.wikipedia.org/wiki/" + sdata
page = urllib.request.urlopen(url)
soup = BeautifulSoup(page.read(), "html.parser")
#print(soup)
wordlist = []
for item in soup.select("#mw-content-text > div > p"):
if item.string != None:
print(item.string)
ss = item.string
wordlist +=twitter.nouns(ss)
print(wordlist)
print("단어 수: "+str(len(wordlist)))
당시 조산만호 이순신은 북방 여진족의 약탈 및 침략을 예상하고 수비를 강화하기 위하여 여러차례 북병사
....
'이순신', '대한', '평가', '이순신', '일기', '시조', '한시', '등', '여러', '편의', '작품']
단어 수: 253
위의 결과의 단어 발생 횟수를 확인하는 예제이다.
1
2
3
4
5
6
7
8
word_dict = {}
for i in wordlist:
if i in word_dict:
word_dict[i] += 1
else:
word_dict[i] = 1
print(word_dict)
{'당시': 3, '조산': 1, '만호': 1, '이순신': 16, '북방': 1, '여진족': 1, '약탈': 1, '및': 2, '침략': 1, '예상': 1, '수비': 1, '위': 1, '차례': 1, '북':
...
'완전무결': 1, '성자': 1, '영웅': 1, '천관우': 1, '등': 2, '일기': 1, '시조': 1, '한시': 1, '여러': 1, '편의': 1, '작품': 1}
중복 단어를 제거하는 코드이다.
1
2
setdata = set(wordlist)
print("발견 된 명사의 갯수(중복제거): " + str(len(setdata)))
발견 된 명사의 갯수(중복제거): 180
위의 결과를 DataFrame으로서 바꾸는 예제이다.
1
2
3
4
5
6
7
8
9
10
11
print("DataFrame으로 읽어들이기")
from pandas import Series, DataFrame
li_data = Series(wordlist)
print(li_data)
seri_data = Series(word_dict)
print(seri_data)
print(seri_data.value_counts()[:5])
print()
df = DataFrame(wordlist)
print(type(df))
DataFrame으로 읽어들이기
0 당시
1 조산
2 만호
3 이순신
4 북방
...
248 한시
249 등
250 여러
251 편의
252 작품
Length: 253, dtype: object
당시 3
조산 1
만호 1
이순신 16
북방 1
..
시조 1
한시 1
여러 1
편의 1
작품 1
Length: 180, dtype: int64
1 143
2 25
3 6
6 2
5 2
dtype: int64
<class 'pandas.core.frame.DataFrame'>
위의 결과를 Plot을 활용하여 시각화하여 보여주는 예제이다.
1
2
3
4
5
6
7
8
import matplotlib.pyplot as plt
plt.rc("font", family="malgun gothic") #한글깨짐 방지
plt.plot(seri_data.value_counts()[:5])
plt.xlabel("횟수 종류")
plt.ylabel("종류별 발생 수")
plt.title("단어 건수")
plt.legend("횟수")
plt.show() #최종적으로 plot을 보이게 하는 명령
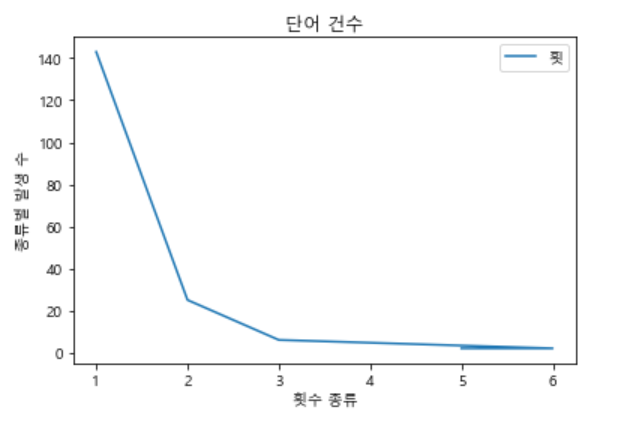
참조: 원본코드
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment