
Kubeflow
Kubeflow의 필요성
먼저 Kubeflow라는 것이 뭔지에 대해 알아보기 전에 Kubeflow가 왜 필요한지에 대해서 먼저 알아보자
먼저 하나의 Model을 만들어서 Service까지 배포하는 과정에 대해서 생각해보자.
위와 같은 과정은 아래의 과정을 거쳐야 한다.
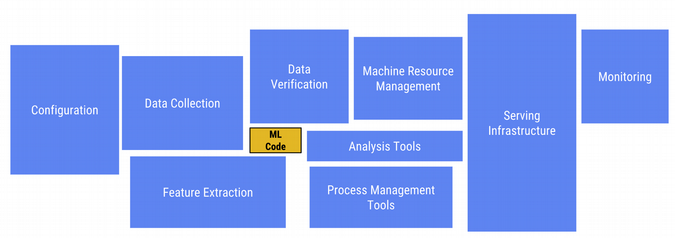
사진 출처: opensource
실질적으로 Model을 개발하고 Serving을 하는데에 관하여 다음과 같은 과정을 거치게 된다.
위와같은 수 많은 작업들(데이터 수집, 데이터 오류검사 등)로 인하여 Modeling에 집중할 수 없다는 것이 현실이다.
실제로 대부분의 개발자분들은 Model을 Serving하기전에 대부분 데이터 수집, 검증 및 가공, Serving Infrastucture에서 많은 시간을 소모하는 것을 겪었다.
때문에 이러한 Machine Learning의 PipeLine을 관리하고 적용시키는 툴의 존재는 매우 필요한 상황이였다.
Kubeflow
Kubeflow는 Kubernetes + mlflow로서 Kubernetes기반으로 Machine Learning의 Flow를 쉽게 도와주는 도구 정도로 생각하면 된다.
즉, Kubeflow로 인하여 개발자는 데이터 분석과 모델 개발에 집중할 수 있고 나머지는 Kubeflow의 도움을 받아 쉽게 진행할 수 있게 하는 것 이다.
이러한 Kubeflow의 구성요소는 다음과 같다.
Kubeflow 구성요소
Jupyter Notebook

Kubeflow는 Jupyter Notebook을 IDE로서 사용할 수 있다.
이러한 Notebook은 Kustomize를 통하여 개인의 취향대로 Customize가 가능하다.
Jupyter Nobebook은 Workspace를 생성할때 GPU지원 여부나 Tensorflow 버전등을 손쉽게 선택이 가능하다.
TensorFlow model training

Kubeflow는 Model Training Job Operator를 제공한다.
이러한 과정은 TFJob을 통하여 이루워진다.
TFJob이란 Kubernetes가 Tensorflow Trainning과정에서 어떻게 Model을 Trainning시킬 것인가에 대하여 미리 .yaml File로서 작성하고 적용시킬 수 있다.
Model serving

Kubeflow는 Model serving을 다양한 형태로 지원해준다.
예를들어 Tensorflow로서 Coding하고 하나의 Model을 Trainning하여 최종결과물을 얻었어도 Jetson Nano Board에서 Test할 수 없었다.
Jetson Nano Board에 올리기위하여 NVDIA TensorRT로서 Serving하였어야 하는데 이러한 번거로운 과정을 Kubeflow에서는 손쉽게 처리 가능하다.
Pipelines

Kubeflow는 Pipelines를 지원한다.
실질적인 하나의 Model을 만든다는것은 Model.py로서 하나를 만든다고 끝나는 것이 아니다.
예를들어 Data를 얼만큼 가져올 것인지에 대한 .py File을 작성할 것이고 이러한 Trainning과정에서 Validation은 어떻게 할 것인가 또 최종적인 결과는 어떻게 출력할 것인가에 대한 Coding을 .py File로서 하나하나 작성할 것이다.
Kubeflow는 이러한 서로 다른 과정을 UI로서 연결하여 작동하는 Pipeline을 제공한다.
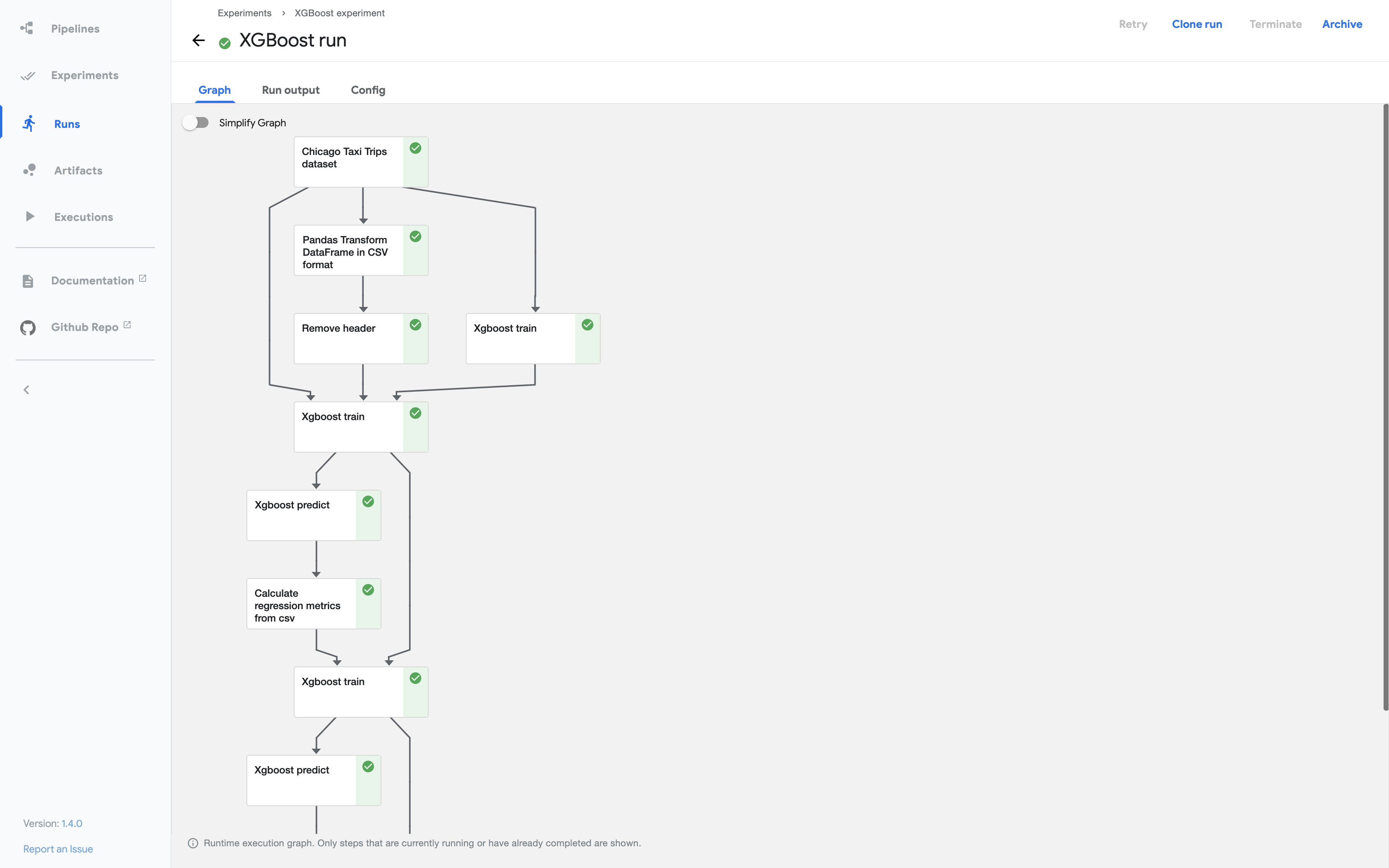
Multi-framework

Kubeflow는 Tensorflow뿐만아니라 PyTorch, MXNey, Chainer등 다양한 Framework를 지원한다.
참조:KubeFlow
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment