
Katib
Hyperparameter Tunning(Katib)
Kubeflow에서는 Katib를 다음과 같이 설명하고 있습니다.
The Katib project is inspired by Google vizier. Katib is a scalable and flexible hyperparameter tuning framework and is tightly integrated with Kubernetes. It does not depend on any specific deep learning framework (such as TensorFlow, MXNet, or PyTorch).
위의서의 설명을 종합하면 다음과 같은 큰 2가지 장점이 존재합니다.
- 다양한 Framework에서 작동할 수 있다.
- 유연한 Hyperparameter Tuning이 가능하다.
위의 장점 중 2번째 유연한 Hyperparameter Tuning이라는 것은 결국에 Code를 수정할 필요없이 그저 Katib를 실행시킬 .yaml File만 고치면 된다는 이야기입니다.
좀 더 자세한 사항은 설치부터 실제 구동을 살펴보면서 알아보자.
Katib 에제 실행
Katib를 실행하기 위해서는 먼저 PV를 만들어서 하나의 Pod이 돌아갈때 PVC와 연동시키는 작업이 필요하다.
다음과 같이 PV.yaml을 작성하고 적용시키자.
apiVersion: v1
kind: PersistentVolume
metadata:
name: katib-mysql
labels:
type: local
app: katib
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /data/katib
평소에 적용시키던 PV와 별로 다른점이 없다.
다음으로 Katib를 통하여 Hyperparameter를 Tunning하기 위한 .yaml File을 살펴보자.
apiVersion: "kubeflow.org/v1alpha3"
kind: Experiment
metadata:
namespace: kubeflow
name: tfjob-example
spec:
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
objective:
type: maximize
goal: 0.99
objectiveMetricName: accuracy_1
algorithm:
algorithmName: random
metricsCollectorSpec:
source:
fileSystemPath:
path: /train
kind: Directory
collector:
kind: TensorFlowEvent
parameters:
- name: --learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.05"
- name: --batch_size
parameterType: int
feasibleSpace:
min: "100"
max: "200"
trialTemplate:
goTemplate:
rawTemplate: |-
apiVersion: "kubeflow.org/v1"
kind: TFJob
metadata:
name:
namespace:
spec:
tfReplicaSpecs:
Worker:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
imagePullPolicy: Always
command:
- "python"
- "/var/tf_mnist/mnist_with_summaries.py"
- "--log_dir=/train/metrics"
- "="
위에서 중요한 Parameter를 살펴보자.
- trial: spec에서 trial의 숫자를 지정한다. 병렬로 수행할 trial개수와 최대 trial, 최대 실패 trial을 적어준다. 이러한 trial은 실제 Python Code를 수행하는 Thread에대한 제약조건이라고 생각하면 이해하기 쉽다.
- objective: 결과적으로 우리가 얻고자 하는 Parameter의 정의이다. 최대 0.99의 정확도를 요구하고 있다.
- algorithm: Hpyerparameter Tunning을 위한 Algorithm이다. 다양한 방식이 있지만, Random을 많이 사용되고 그 이유는 다른 방식은 적용시키기 위한 조건 충족이 어렵기 때문이다. (대중적으로 모든 사람들이 사용하기 편한 Hpyerparameter Tunning 이 정립되지 않았다.)
- parameters: Hyperparameter Tunning을 할 Parameter의 모음이다. min과 max를 설정할 수 있다.
- containers: 실질적으로 Image를 올리고 Code를 수행할 제약사항에 대하여 연결한다.
.yaml File을 kubectl로 apply시키면 다음과 같은 결과를 얻게 된다.
experiment 확인

trial 확인
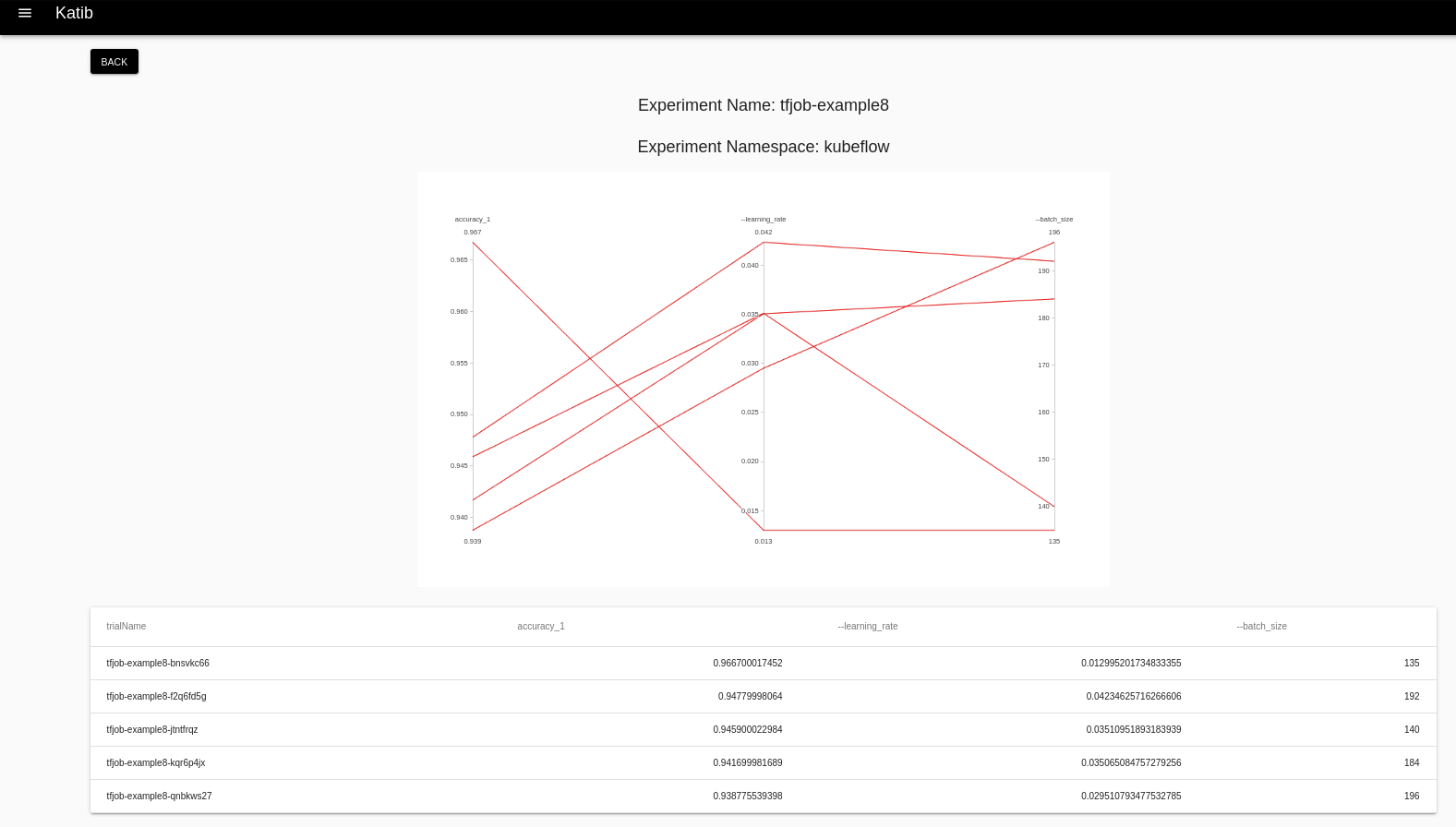
최종적인 결과는 Kubeflow UI에 접속하여 확인할 수 있다.
Katib 실제 적용
Katib를 사용하기 위하여 다음과 같은 과정을 거친다.
Python File 작성
먼저 적용시키고자 하는 Python File을 작성한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import numpy as np
from tensorflow.keras.datasets.cifar10 import load_data
import os
import sys
import tensorflow as tf
parser = argparse.ArgumentParser()
parser.add_argument('--num_epoch', type=int, default=1000, help='Number of steps to run trainer.')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Initial learning rate')
FLAGS, unparsed = parser.parse_known_args()
num_epoch = FLAGS.num_epoch
learning_rate = FLAGS.learning_rate
def next_batch(num, data, labels):
idx = np.arange(0, len(data))
np.random.shuffle(idx)
idx = idx[:num]
data_shuffle = [data[i] for i in idx]
labels_shuffle = [labels[i] for i in idx]
return np.asarray(data_shuffle), np.asarray(labels_shuffle)
def build_CNN_Classifier(x):
x_image = x
W_conv1 = tf.Variable(tf.truncated_normal(shape=[5,5,3,64],stddev=5e-2))
b_conv1 = tf.Variable(tf.constant(0.1, shape=[64]))
h_conv1 = tf.nn.relu(tf.nn.conv2d(x_image, W_conv1, strides=[1,1,1,1],padding='SAME')+b_conv1)
h_pool1 = tf.nn.max_pool(h_conv1,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
W_conv2 = tf.Variable(tf.truncated_normal(shape=[5,5,64,64],stddev=5e-2))
b_conv2 = tf.Variable(tf.constant(0.1, shape=[64]))
h_conv2 = tf.nn.relu(tf.nn.conv2d(h_pool1, W_conv2,strides=[1,1,1,1],padding='SAME')+b_conv2)
h_pool2 = tf.nn.max_pool(h_conv2,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
W_conv3 = tf.Variable(tf.truncated_normal(shape=[3,3,64,128],stddev=5e-2))
b_conv3 = tf.Variable(tf.constant(0.1, shape=[128]))
h_conv3 = tf.nn.relu(tf.nn.conv2d(h_pool2, W_conv3,strides=[1,1,1,1],padding='SAME')+b_conv3)
W_conv4 = tf.Variable(tf.truncated_normal(shape=[3,3,128,128],stddev=5e-2))
b_conv4 = tf.Variable(tf.constant(0.1, shape=[128]))
h_conv4 = tf.nn.relu(tf.nn.conv2d(h_conv3, W_conv4,strides=[1,1,1,1],padding='SAME')+b_conv4)
W_conv5 = tf.Variable(tf.truncated_normal(shape=[3,3,128,128],stddev=5e-2))
b_conv5 = tf.Variable(tf.constant(0.1, shape=[128]))
h_conv5 = tf.nn.relu(tf.nn.conv2d(h_conv4, W_conv5,strides=[1,1,1,1],padding='SAME')+b_conv5)
W_fc1 = tf.Variable(tf.truncated_normal(shape=[8*8*128, 384],stddev=5e-2))
b_fc1 = tf.Variable(tf.constant(0.1,shape=[384]))
h_conv5_flat = tf.reshape(h_conv5,[-1,8*8*128])
h_fc1 = tf.nn.relu(tf.matmul(h_conv5_flat,W_fc1)+b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = tf.Variable(tf.truncated_normal(shape=[384, 10],stddev=5e-2))
b_fc2 = tf.Variable(tf.constant(0.1,shape=[10]))
logits = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
y_pred = tf.nn.softmax(logits)
return y_pred, logits
x = tf.placeholder(tf.float32, shape = [None, 32, 32, 3])
y = tf.placeholder(tf.float32, shape = [None, 10])
keep_prob = tf.placeholder(tf.float32)
(x_train, y_train), (x_test, y_test) = load_data()
y_train_one_hot = tf.squeeze(tf.one_hot(y_train,10),axis=1)
y_test_one_hot = tf.squeeze(tf.one_hot(y_test,10),axis=1)
y_pred, logits = build_CNN_Classifier(x)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=logits))
train_step = tf.train.RMSPropOptimizer(learning_rate).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y_pred,1),tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
tf.summary.scalar('accuracy', accuracy)
tf.summary.scalar('test_input', 1)
merged = tf.summary.merge_all()
with tf.Session() as sess:
train_writer = tf.summary.FileWriter('/train', sess.graph)
sess.run(tf.global_variables_initializer())
for i in range(num_epoch):
batch = next_batch(128, x_train, y_train_one_hot.eval())
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y: batch[1], keep_prob: 1.0})
loss_print = loss.eval(feed_dict={x: batch[0], y: batch[1], keep_prob: 1.0})
print('Epoch: %d, Accuracy: %f, Loss: %f'%(i, train_accuracy, loss_print))
summary,_ = sess.run([merged,train_step], feed_dict={x: batch[0], y:batch[1], keep_prob:0.8})
train_writer.add_summary(summary, i)
train_writer.close()
test_accuracy = 0.0
for i in range(10):
test_batch = next_batch(1000,x_test,y_test_one_hot.eval())
test_accuracy = test_accuracy + accuracy.eval(feed_dict={x: test_batch[0], y:test_batch[1], keep_prob: 1.0})
test_accuracy = test_accuracy/10
print('Test Accuracy: %f'%(test_accuracy))
여기서 주의하여야하는 점이 몇가지 있다.
- Tuning하고자 하는 Hyperparameter는 parser를 통하여 받는다. 나중에 .yaml File작성시 paser로 받아들이는 값을 변화시켜 Trainning이 진행되기 때문이다.
- 목표하고자 하는 값을 반드시
tf.summary.scalar('accuracy', accuracy)로서 받아야 한다. 나중에 .yaml File에 작성하여 이름을 맞춰서 접근한다. - 한글은 사용하지 말자 Issue를 직접작성하고 답변을 들었으나 한들을 사용하게 되면 Pod 내부에서 Python을 실행시킬때 Error가 발생하여 Pod이 실행되지 않는다.
Dockerfile 작성, Image Build, Image push
Docker File 작성
FROM tensorflow/tensorflow:1.14.0
ADD . /var/tf_cnn
ENTRYPOINT ["python", "/var/tf_cnn/cnn-example.py"]
Image Build
docker build -f Dockerfile -t wjddyd66/cnn-example:15.0 ./
Image Push
docker push wjddyd66/cnn-example:15.0
tfjob .yaml File적용
먼저 위의 과정에 맞는 .yaml File의 내용은 다음과 같다.
apiVersion: "kubeflow.org/v1alpha3"
kind: Experiment
metadata:
namespace: kubeflow
name: cnn-example-accuracy2
spec:
parallelTrialCount: 3
maxTrialCount: 12
maxFailedTrialCount: 3
objective:
type: maximize
goal: 1
objectiveMetricName: accuracy
algorithm:
algorithmName: random
metricsCollectorSpec:
source:
fileSystemPath:
path: /train
kind: Directory
collector:
kind: TensorFlowEvent
parameters:
- name: --learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.05"
- name: --num_epoch
parameterType: int
feasibleSpace:
min: "100"
max: "1000"
trialTemplate:
goTemplate:
rawTemplate: |-
apiVersion: "kubeflow.org/v1"
kind: TFJob
metadata:
name:
namespace:
spec:
tfReplicaSpecs:
Worker:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: tensorflow
image: wjddyd66/cnn-example:15.0
imagePullPolicy: Always
command:
- "python"
- "/var/tf_cnn/cnn-example.py"
실제 주의하여서 작성해야 하는 부분에 대해서 알아보자.
- objective: 실질적으로 HyperparameterTunning을 그만두는 조건을 적어두는 곳 이다. Object값을 maximize할지 minimize할 지 정할수 있고 목표 값을 설정할 수 있다. 또한 objectiveMetricName이 위에서 PythonFile에서 언급하였던
tf.summary.scalar('accuracy', accuracy)와 Mapping한다. - metricsCollectorSpec: 실질적으로 Python File에서 LogFile의 위치와 collector의 종류를 적어주어야 한다.(Pytorch등 다른 Framework는 Collector를 변경하여야 한다.)
- parameter: Tunning하기 위한 Parameter를 적어둔다. PythonFile에서 parser = argparse.ArgumentParser()에서 지정한 Parameter와 Mapping하여야 한다.
위의 3가지만 조심하면 나머지는 직관적으로 알기 쉽게 작성할 수 있다.
위에서 작성한 .yaml File의 내용대로 HyperParameter를 Tunning하여 Object의 goal값에 도달할때까지 Trainning을 진행한다. 아래 결과를 살펴보게 되면 Accuracy가 1에 도달하지 못하므로 Trial개수 최대값인 12번이 실행된 것을 알 수 있다.
$ kubectl get trials -n kubeflow
NAME TYPE STATUS AGE
cnn-example-accuracy2-49v7nkrm Succeeded True 14m
cnn-example-accuracy2-4kpwrq8c Succeeded True 37m
cnn-example-accuracy2-4ml8g7bp Succeeded True 19m
cnn-example-accuracy2-5j9krjzb Succeeded True 29m
cnn-example-accuracy2-5kd6vtwc Succeeded True 31m
cnn-example-accuracy2-7cw78nrf Succeeded True 23m
cnn-example-accuracy2-7jrznr4n Succeeded True 23m
cnn-example-accuracy2-grvjzdjh Succeeded True 31m
cnn-example-accuracy2-l2wql9bz Succeeded True 37m
cnn-example-accuracy2-m4qtkddl Succeeded True 21m
cnn-example-accuracy2-n8wlfc4n Succeeded True 33m
cnn-example-accuracy2-s2p87kps Succeeded True 37m
UI 확인 결과
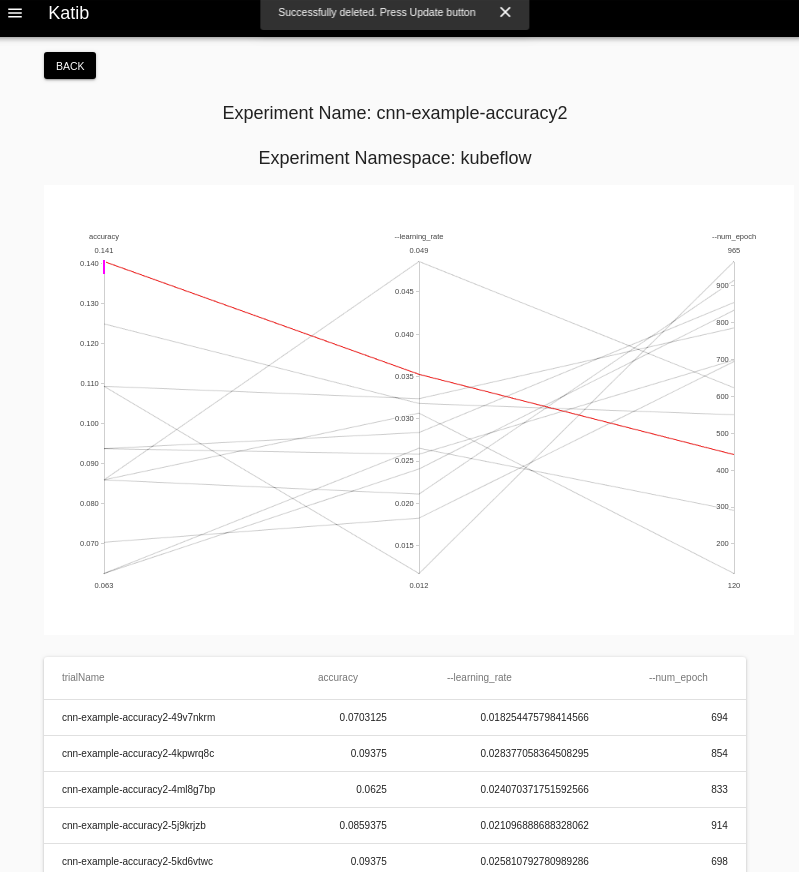
참고 사항
Experiment가 생성되고 Trials가 생성되어 실질적인 Hyperparameter Tunning을 위한 Python File을 실행하고 결과를 서로 통신한다.
결과적으로 Trials가 생성되는지 확인하고 생성이 안되면 다음과 같은 명령어로 인하여 Trial들의 각각의 상태를 확인할 수 있다.
kubectl logs -n [Pod name] -c tensorflow
참조:Kubeflow-Katib
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment