
FLAN
FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
Abstract
This paper explores a simple method for improving the zero-shot learning abilities of language models. We show that instruction tuning—finetuning language models on a collection of datasets described via instructions—substantially improves zero- shot performance on unseen tasks. We take a 137B parameter pretrained language model and instruction tune it on over 60 NLP datasets verbalized via natural language instruction templates. We evaluate this instruction-tuned model, which we call FLAN, on unseen task types. FLAN substantially improves the performance of its unmodified counterpart and surpasses zero-shot 175B GPT-3 on 20 of 25 datasets that we evaluate. FLAN even outperforms few-shot GPT-3 by a large margin on ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, and StoryCloze. Ablation studies reveal that number of finetuning datasets, model scale, and natural language instructions are key to the success of instruction tuning.
이전 연구인 T5에서 Text-to-Text로서 학습을 진행하는 경우 Performance를 향상시키고 발전 가능성을 보인것을 확인하였다. 해당 논문(FLAN)에서는 zero-shot learning에서 특히 뛰어난 instruction tuning방법을 소개한다. 해당 방법은 T-5와 동일하나, Fine Tuning과정에서도 해당 방법을 사용한다는 것이 주요하다.
Introduction
Introduction에서는 기존 모델들의 Few-shot의 성능은 우수하지만, Zero-Shot Task에서는 Performancer가 낮은 것을 문제로 삼고 있다. 예를 들어, GPT-3의 경우에도 Few-Shot의 성능이 매우 나쁜 것을 알 수 있다. 이러한 잠재적인 이유로서 Few-Shot 예제가 없으면 모델이 사전 교육 데이터의 형식과 유사하지 않은 프롬프트에서 제대로 수행하기 어렵기 때문이다.
이러한 문제를 해결하기 위하여 해당 논문에서는 Language model(LM)의 unseen task에 대한 zero-shot 성능을 향상시킬 수 있는 instruction tuning을 제안한다.
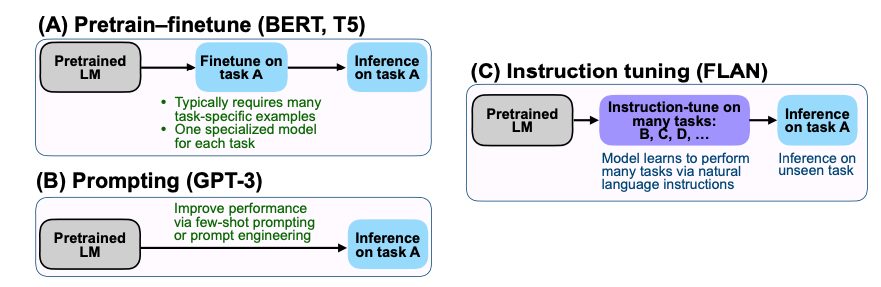
위의 Figure를 살펴보게 되면, 대표되는 각 모델을 어떻게 FineTuning을 하는지에 대한 예시이다.
- Pretrain-finetune(BERT, T5): Transformer의 Encoder의 부분을 사용하는 BERT나 T5의 경우에는 Generation이 불가능한 모델이다. 따라서, FineTuning을 특정 Task에 맞게 학습한뒤, Inference를 진행하는 것을 알 수 있다.
- Prompting (GPT-3): Transformer의 Decoder의 부분을 사용하는 GPT는 Generation이 가능한 모델이다. 성능을 향상시키기 위하여 few-shot prompting이 주요한 것을 알 수 있다.
- Instruction tuning (FLAN): FLAN의 경우에는 Inference할 Task가 아닌, 다른 여러 Task의 Dataset으로 Instruction-Tuning을 진행하여 Task A에서 zero-shot performance를 향상시키는 것을 알 수 있다.
FLAN: INSTRUCTION TUNING IMPROVES ZERO-SHOT LEARNING
가장 주요한 것은, FLAN을 사용하기 위하여 데이터셋을 어떻게 구상하였는지가 가장 주요하다. 아래 Figure는 Dataset을 어떻게 학습에 사용할 Format으로 바꾸었는지에 대한 내용 이다.
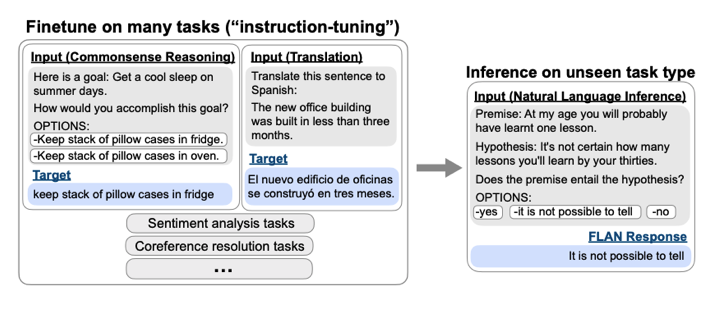
주요한 점은, 아래와 같다.
- Text-to-Text로서 데이터 셋을 구성하였다.
- Finetuning과정에서는 Inference Task가 아닌 다른 여러 Task에 대한 데이터 셋으로 진행하였다.
- Classification의 경우에는 다른 Output이 나오지 않게, Option으로서 yes, no만 제시하였다.
위와 같은 Format으로 변형하기 위하여 해당 논문의 저자들은 NLP에서 많이 사용하는 Dataset을 아래와 같이 12개의 Cluster로서 변형하였다.
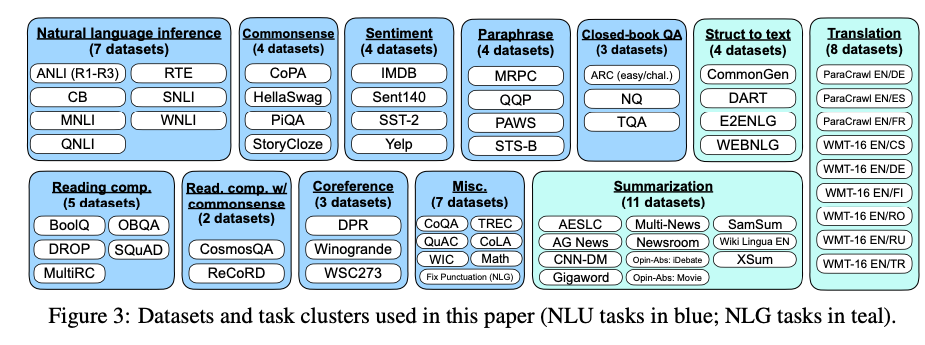
위와 같은 Cluster마다 직접 정의한 Template에 맞게 모두 변형하고 학습을 진행하였다.
Experiment
해당 논문에서는 비교한 모델은 아래와 같다.
- Base LM: decoder-only transformer 137B, web document, diaglog data, wikipedia로 학습된 모델
- GPT-3
- FLAN
위와 같은 3가지 모델을 통하여 zero-shot task의 성능을 평가하였다.
많은 Task에 대하여 실험을 수행하였는데, 특정 몇몇 Experiments의 성능을 살펴보면 아래와 같다.
Performance
1) NLI (Natural Language Inference)
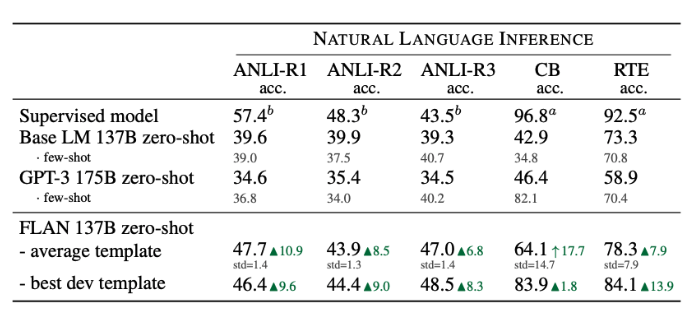
2) Reading Comprehension & Closed-book QA
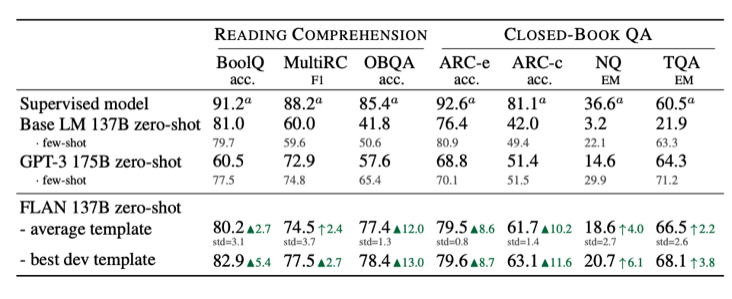
3) Translation
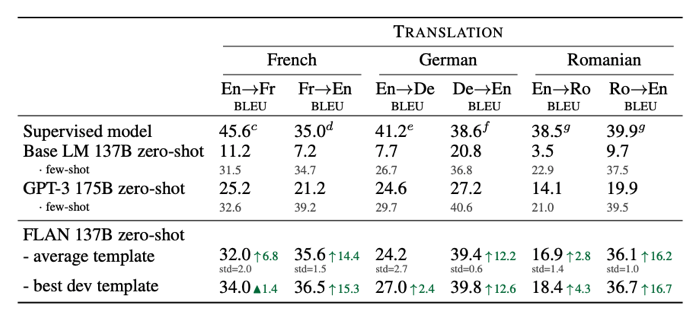
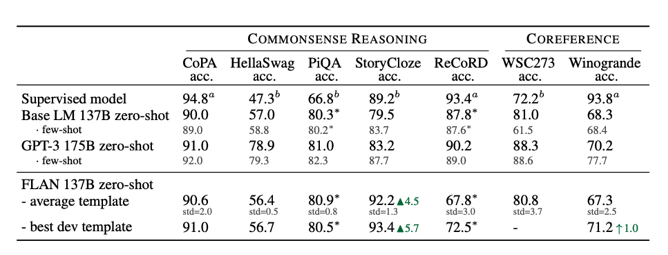
4) Commonsense Reasoning & Coreference Resolution
- Commonsense reasoning
- ex) COPA: premise가 주어지고 2개의 선택지에서 원인/결과에 해당하는 후보 답안 선택
- Coreference resolution
- ex) WSC: 주어진 두 개의 단어가 같은 대상을 지칭하는지 판단
Number of cluster
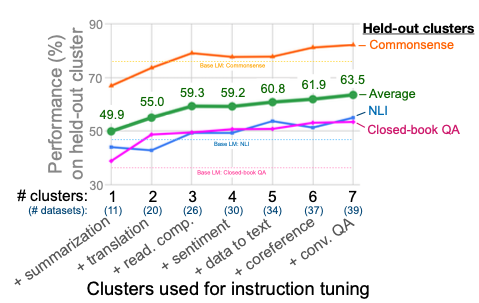
위의 Figure는 Instruction tuning에서 여러 Task의 데이터셋을 많이 사용하여 학습할 수록 Performance가 향상되는 것을 알 수 있다.
Scaling Laws
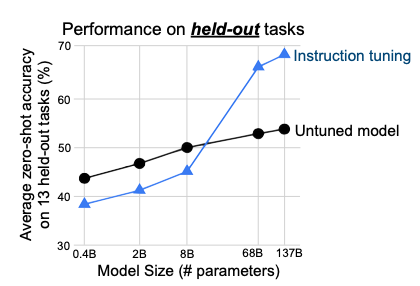
Multi-task의 문제점을 보여준다. 대부분의 Multi-task Learning의 문제점은 하나의 모델에 여러개의 Task를 학습하는 경우 Performance가 떨어진다. 하지만, Model의 Size가 매우 커져서 Multi-task간의 관계를 고려할 수 있을 정도록 커진다면 Performance는 향상되는 것을 알 수 있다.
Scaling Instruction-Finetuned Language Models (Flan-T5)
Abstract
Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation, RealToxicityPrompts). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PaLM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints,1 which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
이 논문의 핵심은 (1) PreTraining과정에서 Multi-task로 학습한 T5 모델을 사용한다. (2) Fine-Tuning 과정에서 Instruction Learning방법으로 학습하는 Flan방법을 해당 모델에 적용한다. 이러한 결과로서 적은 수의 Parameter로서 다른 파라미터가 큰 모델보다 성능이 좋은 것을 증명하고, 해당 모델을 공개한다.
Experiment Setting
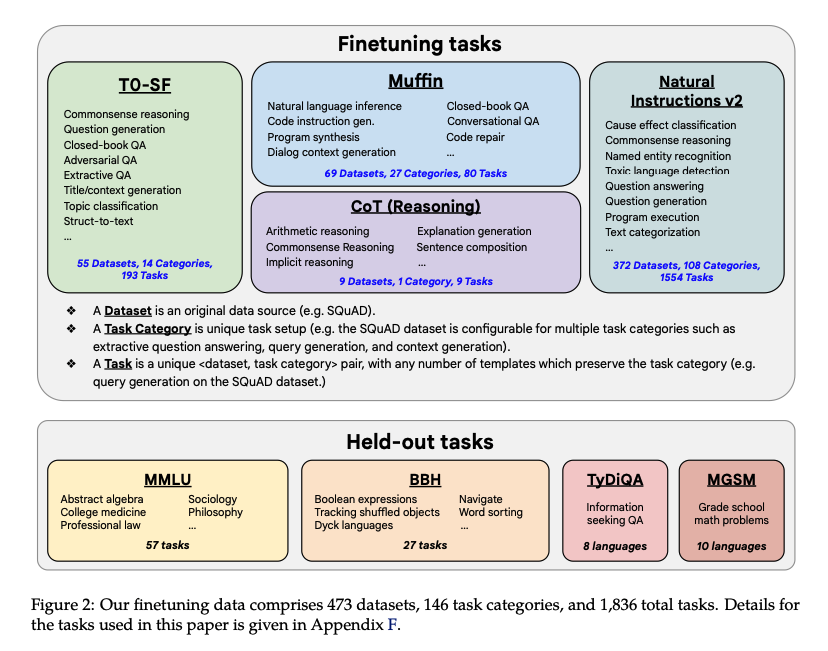
해당 논문에서는 위와같은 Dataset으로서 Finetuning 및 모델의 성능을 평가하였다.
- Finetuning tasks: 총 473개의 datasets으로서 구성되어 있으며, 146 task categories를 포함하고 있다. 총 1834 task에 대하여 finetuning을 진행한다.
- Held-out tasks: 주요한 점은 해당 Datasets는 비교하려는 모델 PaLM에서 이미 사용한 데이터셋이라는 것 이다.
- (1) MMLU (Hendrycks et al., 2020) includes exam questions from 57 tasks such as mathematics, history, law, and medicine.
- (2) BBH includes 23 challenging tasks from BIG-Bench (Srivastava et al., 2022) for which PaLM performs below an average human rater (Suzgun et al., 2022).
- (3) TyDiQA (Clark et al., 2020) is a question-answering benchmark across 8 typologically diverse languages.
- (4) MGSM (Shi et al., 2022) is a multilingual benchmark of math word problems from Cobbe et al. (2021) manually translated into 10 languages.
CoT-Dataset
해당 논문 저자들이 FineTuning에 사용한 Dataset중에서 가장 주요하게 생각하는 Dataset이다. 해당 Dataset은 Reasoning Task를 수행하는 데이터셋으로 아래와 같이 구성되어 있다.

위의 Figure를 살펴보게 되면, 상황 설명과 부가 설명, 그리고 대답으로 이루워져있다. 또한, 대답에서 중간에 추론할 수 있는 Test가 있냐 없냐에 따라서 chain-of-thought가 있냐 없냐가 결정된다. 이러한 Dataset은 Flan-T5에서 이유를 자세하게 학습하도록 지정할 수 있다는 가정으로 Dataset을 구성하였다고 한다.
Scaling to 540B parameters and 1.8K tasks
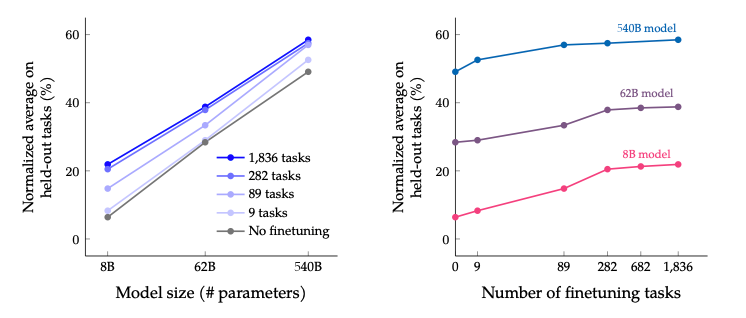
위의 Figure를 살펴보면 다음과 같은 결과를 얻을 수 있다.
- Model의 Size가 크면 클수록 Model의 Performance가 좋아진다.
- Finetuning에 사용하는 모델의 Task가 많아질수록 Model의 Performance가 좋아진다.
- 특정수의 Tasks이상이면, 모델의 Performance는 비슷해 지는 것을 알 수 있다.
Table로서 자세한 수치를 살펴보면 아래와 같다.
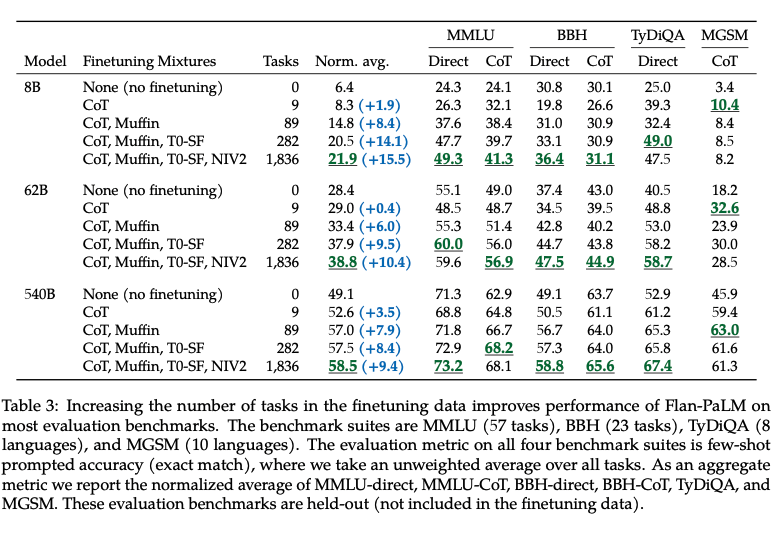
Some chain-of-thought data is needed to maintain reasoning ability
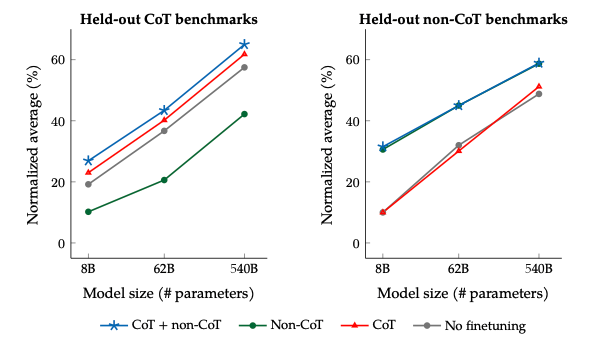
위의 Figure를 살펴보게 되면, CoT Dataset에 대한 결과를 보여준다. (개인적인 생각으로는 CoT뿐만 아니라 다른 특정 specific한 task에도 적용된다고 생각된다.)
먼저, Held-out non-CoT benchmarks를 살펴보게 되면 주요한 점은 2가지가 있다.
- CoT Dataset만으로 Finetuning하는 것은 Finetuning하지 않는 것과 성능이 비슷한 것을 알 수 있다. 즉, Finetuning을 진행할 때, 원하는 specific한 task에 맞게 finetuning을 진행하여야 한다는 것 이다.
- CoT+non-CoT의 성능과 Non-CoT의 성능이 비슷한 것을 알 수 있다. 이 결과 또한 위와 같은 이유일 것 이다.
다음으로, Hel-out CoT benchmarks에서의 결과는 아래와 같다.
- Non-CoT로서 Finetuning하는 것은 오히려 성능을 악화시킨다. 즉, Task-Specific하지 않은 Dataset으로 Training시에 성능을 약화 시킬 수 있다.
- 흥미로운 점은 단순히 CoT Dataset으로 학습하는 것 보다 non-CoT를 같이 학습시키는 것이 성능이 좋다는 것 이다. 이는 단순히 Dataset이 많아져서 인지, CoT도 중요하지만, non-CoT또한 주요하다는 것을 알려준다.
Unlocking zero-shot reasoning
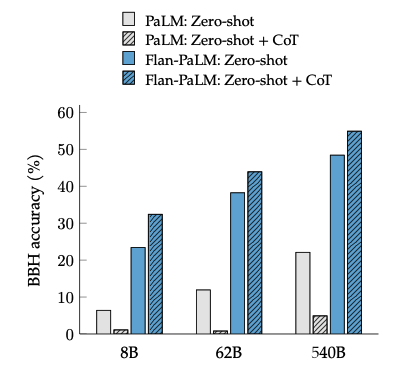
Flan논문에서 강조하던 것과 동일한 결과이다. 위의 Figure를 살펴보게 되면, 기존의 Model들은 Zero-shot에서 Performance가 굉장히 낮은 것을 알 수 있다. 하지만, Flan방식으로 학습하게 되면, Zero-shot에서 성능을 보장하는 것을 알 수 있다. 또한, Reasoning Task이므로 CoT Dataset으로서 Finetuning하는 것또한 성능에 영향을 많이 미치는 것을 알 수 있다.
Experiment Result
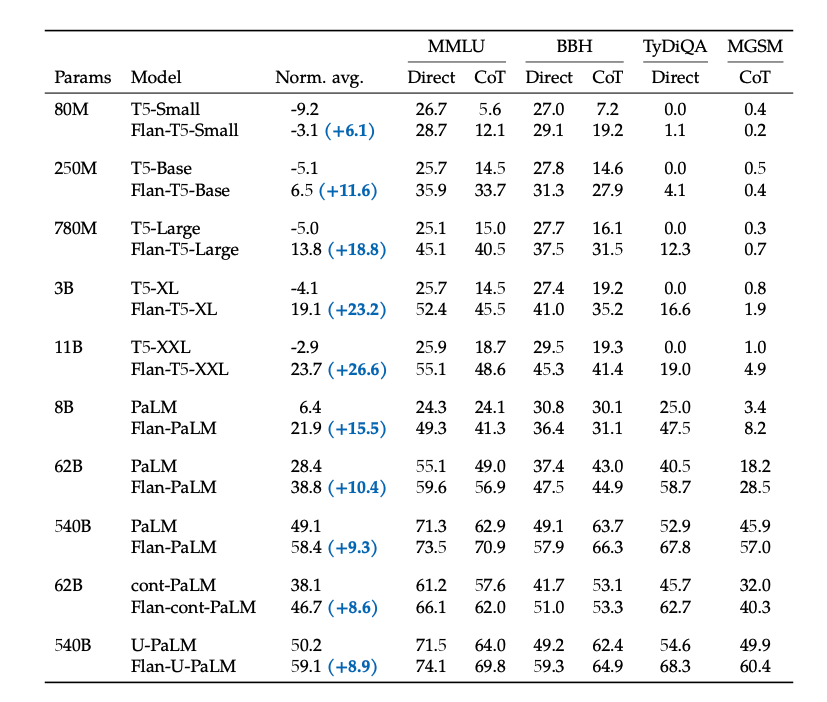
위의 결과는 최종적인 실험 결과이다. 해당 결과에서 주요하게 살펴볼 점은 아래와 같다.
- Flan 방식으로 Finetuning을 진행할 시 모두 Performance가 향상되는 것을 알 수 있다. 즉, FineTuning에서 Instruction Learning이 효과가 큰 것을 알 수 있다.
- T5-Small -> T5-XXL까지의 성능을 살펴보면, Direct의 성능 변화가 거의 없는 것을 알 수 있다. 하지만, Flan으로 학습했을 때는 차이가 큰 것을 알 수 있다.
Appendix: Flan-T5-XL is only 3B parameters and achieves a MMLU score of 52.4%, surpassing GPT-3 175B’s score of 43.9%
Leave a comment