
Retrieval-Augmented Generation with Hierarchical Knowledge
Retrieval-Augmented Generation with Hierarchical Knowledge
Abstract
Graph-based Retrieval-Augmented Generation (RAG) methods have significantly enhanced the performance of large language models (LLMs) in domain-specific tasks.
However, existing RAG methods do not adequately utilize the naturally inherent hierarchical knowledge in human cognition, which limits the capabilities of RAG systems.
In this paper, we introduce a new RAG approach, called HiRAG, which utilizes hierarchical knowledge to enhance the semantic understanding and structure capturing capabilities of RAG systems in the indexing and retrieval processes.
Our extensive experiments demonstrate that HiRAG achieves significant performance improvements over the state-of-the-art baseline methods.
The code of our proposed method is available at https://github.com/hhy-huang/HiRAG.
LLM이 Task를 진행함에 따라, RAG는 많은 도움을 주고 주요한 기법이 되었다. 하지만, 대부분의 RAG는 hierarchical knowledge를 사용하지 못한다. 해당 논문은 hierarchical knowledge를 사용할 수 있는 RAG기법을 제안한다.
Introduction
해당 논문에서는 기존의 연구들에 대한 방법과 Limitation을 아래와 같이 정리하였다.
- Navie RAG
- 설명: 기본적인 RAG로서, Document를 단순히 Chunk하여 저장한다.
- 단점: 저장된 Document간의 Relationship을 고려하지 못한다.
- GraphRAG
- 설명: Document간의 관계를 고려하기 위하여 KG (knowledge graph)를 활용한다.
- 단점: Relationship이 단순한 Entity만으로 구성될 수 밖에 없다.
- p.s. entity 예시. (entity란 KG에서 노드로 표현되는 정보 단위)
- 인물: Albert Einstein
- 장소: Princeton University
- KAG
- 설명: GraphRAG의 단점을 해소하고자, Hierarchical하게 Document를 구성하고 Relationship을 정의한다.
- 단점: Hierarchical한 Architecture를 수작업으로 다 진행해야 하므로, Domain에 대한 전문적인 지식이 필요하다. (Generalziation이 안된다.)
- p.s. 사람이 전부 수작업으로 Node와 Edge를 정의하게 된다.
- LightRAG
- 설명: 2가지 Query로서 각각 RAG를 진행한다. (1) Gobal Knowledge. (해당 개념이 속한 상위 카테고리 또는 일반적인 배경 지식) (2) Local Knowledge (특정 개별 엔티티에 대한 상세한 설명)
- 단점: 저장된 Document간의 Relationship을 고려하지 못한다.
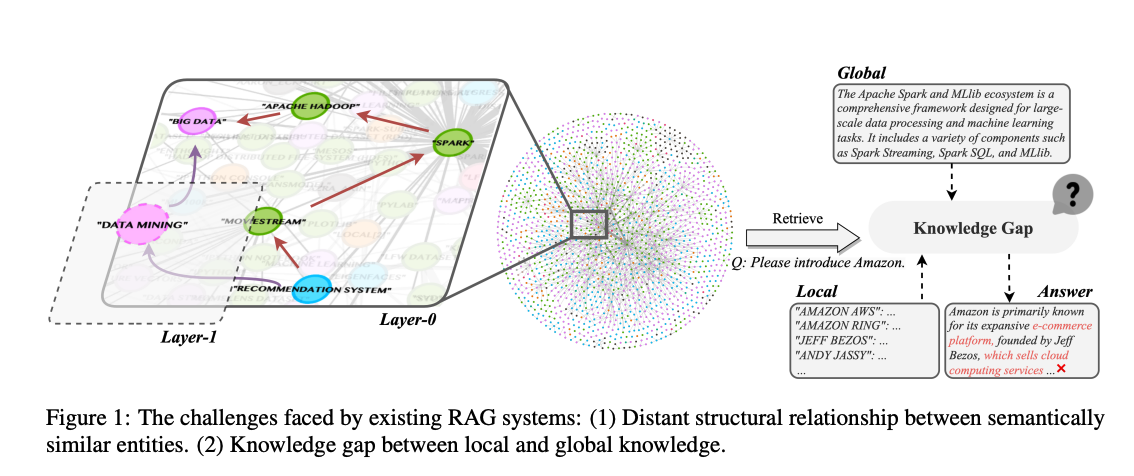
위의 4가지 RAG에서 각각 가지고 있는 단점은 아래와 같다. (Figure 참조)
- 의미적으로 비슷하지만 KG 내에서 구조적으로 멀리 떨어진 엔티티들이 존재해 문맥 연결성이 약함.
- Figure 1에서 Data Mining과 Big Data, Recommendation System은 관련이 있으나 // Hierarchical하지 않은 구조를 가지게 되면, Big Data와 Recommendation System상의 거리는 멀게 적용 된다.
- Global과 Local간의 불일치가 발생할 수 있다.
- Figure 1 에서 아래와 같이 Global과 Local의 차이로 인하여 일관성을 해치는 답변이 생길 수 있다.
- Global: Amazon에 대략적인 설명
- Local: Amazon의 경영진 목록
- Figure 1 에서 아래와 같이 Global과 Local의 차이로 인하여 일관성을 해치는 답변이 생길 수 있다.
해당 문제를 해결하기 위하여, 저자는 HiRAG를 제안한다.
- HiIndex: Graph간의 연결을 Hierarchical하게 구성한다. 상위 레이어는 하위 레이어의 엔티티 집합을 요약
- HiRetrieval: LLM에게 3개의 Layer (Global, Bridge, Local)의 정보를 같이 제공함으로서 보다 포괄적이고 정밀한 응답 생성 가능.
Appendix: Others Method
Related Work에서는 Introduction에서 설명하지 않은 2가지 방법에 대해서도 추가적으로 설명하고 있다. 해당 방법들에 대한 내용은 자세히 나와있지 않아, 논문 원본을 살펴봐야 한다.
- GRAG: Graph Retrieval-Augmented Generation
- 소프트 프루닝(Soft Pruning): 그래프에서 의미 없는 노드를 부드럽게 제거.
- 그래프 프롬프트 튜닝(Graph Prompt Tuning): 텍스트와 그래프 구조(topology)를 동시에 이해할 수 있게 LLM 프롬프트를 조정.
- STRUCTRAG: BOOSTING KNOWLEDGE INTENSIVE REASONING OF LLMS VIA INFERENCE-TIME HYBRID INFORMATION STRUCTURIZATION
- 주어진 질문에 가장 적합한 구조 유형(예: 트리, 계층, 순차)을 식별.
- 원래 문서들을 그 구조로 변환.
- 재구성된 구조에 따라 문맥 정렬 및 응답 생성.
The HiRAG Framework
Appendix: Code 해당 논문의 Code는 https://github.com/hhy-huang/HiRAG/blob/main/docs/notes_of_codes.md 를 참조하면 된다. 코드양이 너무 많아, 현재 파악은 불가하고 흐름정도만 파악하는 것을 목표로 한다.
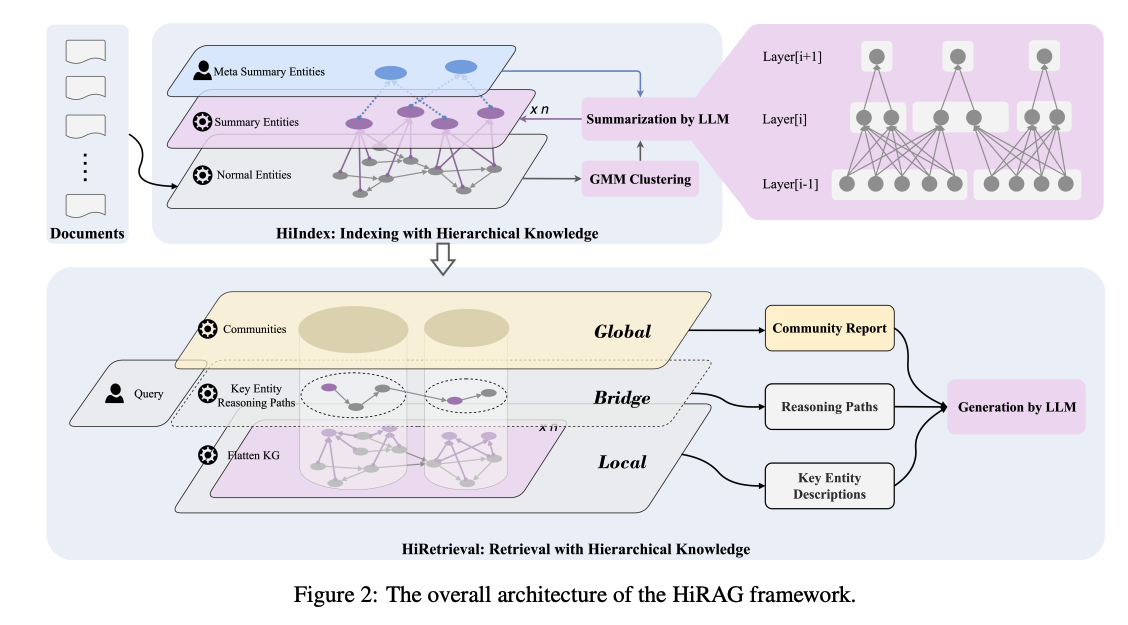
HiRAG는 크게 2가지 구성요소로 되어있다.
- HiIndex: 각각의 Layer을 서로다른 세분화 정도 (knowledge granularity)로 구별하여, hierarchical KG을 구축합니다.
- HiRetrieval: 각각의 retrieved된 commnunity (SubGraph)안에서 연관된 entities를 찾고, 최단 경로를 찾습니다.
설명하기 앞서, 해당 논문에서 제안하는 HiIndex의 Algirithm은 아래와 같습니다.

Preliminary and Definitions
Definitions
- \(q\): 사용자 입력 Query
- \(\text{LLM}\): Generation LLM Model
- \(\mathcal{R}\): Retrieval Module
- \(\phi\): Graph Indexer
- \(\psi\): Graph Retrieval
- \(M(\cdot)\): Distribution
- \(a^*\): 최적의 정답
- \(a\): 실제 정답
- \(\mathcal{D}\): original external database
- \(\mathcal{g}\): graph database
- \(G^*\): 최적의 sub graph
Preliminary
$$\begin{equation} M = (\text{LLM}, \mathcal{R}(\phi, \psi)) \end{equation} $$
위의 수식은 전체적인 RAG Framework에 대한 설명이다. 수식을 살펴보게 되면,
- RAG Frame Work는 Generation Model (\(\text{LLM}\))과 Retrieval Module ($$\mathcal{R}(\cdot)$)으로 구성 되어있다.
- Retrieval Module은 크게 Graph Indexer (\(\phi\))와 Graph Retrieval (\(\psi\))로 구성된다.
- Graph Indexer: 각각의 Context에 알맞는 Index를 만드는 과정이다. (e.g. 수많은 페이지를 “챕터 -> 소챕터”로 나눔)
- Graph Retrieval: 질문에 맞는 Index를 찾는 과정이다. (e.g. 1장. 집합 선택)
$$\begin{equation} a^* = \argmax_{a \in A} M (a|q,\mathcal{g}) \end{equation} $$
$$\begin{equation} \mathcal{g} = \psi(D) = \{ (h,r,t)|h,t \in V, r \in \epsilon \} \end{equation} $$
위의 수식은 RAG Framework를 활용하여 사용자 질문에 대한 대답을 찾는 과정이다.
- 사용자에 대한 적절한 대답 (\(a^*\))은, 사용자의 질문 (\(q\))과 Graph dataBase의 결과 (\(\mathcal{g}\))로 이루워 진다.
- Graph dataBase의 결과 (\(\mathcal{g}\))는 실제 DataBase(\(\mathcal{D}\))에서 Graph Indexer (\(\phi\))를 활용하여 찾은 것 이다. (나머지 Notation은 밑의 Method 읽고 확인 필요.)
해당 수식을 다시 approximate하여 나타내게 되면, 아래와 같다.
$$\begin{equation} M(a|q, \mathcal{g}) \approx LLM(a|q, G^*) \cdot \psi(G^*|q, \mathcal{g}) \end{equation} $$
결국 Generation Model (\(\text{LLM}\))은 고정되어있다 하면, 우리는 사용자 Query에 도움이 되는 Context (\(G^*\))을 Graph에서 잘 찾아 내어(\(\psi(G^*|q, \mathcal{g})\))전달하면 된다.
Appendix. Text Chunking
아래 Hierarchical Knowledge를 구축하기 이전에 Document가 들어왔을 때, Text를 Chunk하여야 한다. 해당 과정은 실제 코드에서 확인하면 아래와 같다.
- Document를 모두 LLM Tokenizer를 통하여 Token으로 변경한다. (gpt-4-0 사용)
- Full Text 기준 default_text_separator를 기준으로 Text를 모두 구분한다. (., ?, ! 등…)
- max_token_size: 1024
- overlap_token_size: 128
- 위의 과정을 거친 chunk를 아래와 같은 구조러서 저장한다.
- tokens: 해당 token의 길이
- content: 실제 내용
- chunk_order_index: Document에서 몇번째 chunk인지
- full_doc_id: 중복되는 document저장을 방지하기 위하여, 고유한 document id
- 해당 chunk를 content을 기준으로 hashmap을 만들어서 저장한다.
- p.s. 여러 document에서 중복되는 chunk가 있으면, 방지하기 위하여 사용한 것 같다.
Indexing with Hierarchical Knowledge
Local Information
$$\begin{equation} \mathcal{g}_0 = \{ (h,r,t)|h,t \in V_0, r \in \epsilon_0 \} \end{equation} $$
위의 수식은, 가장 낮은 Layer로서 Document의 Entity간의 연결을 하는 과정이다. 가장 낮은 Layer이므로 \(\mathcal{g}_0\)와 같이 0으로서 Layer를 나타낸다.
또한, 각각의 \(h, r, t\)는 다음과 같은 의미를 나타내게 된다.
- \(h, t\): Entity (entity_name)
- entity_name: Alex
- entity_type: person
- entity_description: Alex is a character who experiences frustration and is observant of the dynamics among other characters.
- \(t\): Relationship
- source_entity: Amazon
- target_entity: AWS
- relationship_description: AWS is a subsidiary of Amazon, providing cloud services under its brand.
- relationship_strength: 10
위와 같이 각각의 문장에서 Head-Tail간의 관계를 Relation으로 나타내는 것을 basic KG라고 지칭한다. 해당 과정을 Document가 들어올 때마다, LLM으로 진행하였다고 한다. 논문의 저자들은 이러한 raw한 정보를 가져가는 것을 “Local Information” 혹은 “Flatten KG”라고 정의한다.
Appendix. entity_type: 해당 논문에서 중요한 것은 entity_type이다. entity_name은 동일하여도, entity_type에 따라 description이 바뀌는 것을 알 수 있다. 해당 entity_type은 실제 구현 코드에서 확인하면, 미리 define하여 사용하는 것을 알 수 있다. 실제 code에서 제안하는 default entity_type은 “organization”, “person”, “geo”, “event”로서 모두 명사로 지정하였다. (p.s. 논문에서는 해당 값을 “Meta Summary Entities라고 표현한다.”)
Appendix. Entity Extraction Prompt
실제, LLM으로 해당 관계를 뽑기 위한 Prompt는 아래와 같이 구성하여 진행하였다. (p.s. 구분자인 delimiter는 사전에 configure로 구성하여 보고나하고 있다.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
PROMPTS[
"entity_extraction"
] = """-Goal-
Given a text document that is potentially relevant to this activity and a list of entity types, identify all entities of those types from the text and all relationships among the identified entities.
-Steps-
1. Identify all entities. For each identified entity, extract the following information:
- entity_name: Name of the entity, capitalized
- entity_type: One of the following types: [{entity_types}]
- entity_description: Comprehensive description of the entity's attributes and activities
Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>
2. From the entities identified in step 1, identify all pairs of (source_entity, target_entity) that are *clearly related* to each other.
For each pair of related entities, extract the following information:
- source_entity: name of the source entity, as identified in step 1
- target_entity: name of the target entity, as identified in step 1
- relationship_description: explanation as to why you think the source entity and the target entity are related to each other
- relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity
Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_strength>)
3. Return output in English as a single list of all the entities and relationships identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter.
4. When finished, output {completion_delimiter}
######################
-Examples-
######################
Example 1:
Entity_types: [person, technology, mission, organization, location]
Text:
while Alex clenched his jaw, the buzz of frustration dull against the backdrop of Taylor's authoritarian certainty. It was this competitive undercurrent that kept him alert, the sense that his and Jordan's shared commitment to discovery was an unspoken rebellion against Cruz's narrowing vision of control and order.
Then Taylor did something unexpected. They paused beside Jordan and, for a moment, observed the device with something akin to reverence. “If this tech can be understood..." Taylor said, their voice quieter, "It could change the game for us. For all of us.”
The underlying dismissal earlier seemed to falter, replaced by a glimpse of reluctant respect for the gravity of what lay in their hands. Jordan looked up, and for a fleeting heartbeat, their eyes locked with Taylor's, a wordless clash of wills softening into an uneasy truce.
It was a small transformation, barely perceptible, but one that Alex noted with an inward nod. They had all been brought here by different paths
################
Output:
("entity"{tuple_delimiter}"Alex"{tuple_delimiter}"person"{tuple_delimiter}"Alex is a character who experiences frustration and is observant of the dynamics among other characters."){record_delimiter}
("entity"{tuple_delimiter}"Taylor"{tuple_delimiter}"person"{tuple_delimiter}"Taylor is portrayed with authoritarian certainty and shows a moment of reverence towards a device, indicating a change in perspective."){record_delimiter}
("entity"{tuple_delimiter}"Jordan"{tuple_delimiter}"person"{tuple_delimiter}"Jordan shares a commitment to discovery and has a significant interaction with Taylor regarding a device."){record_delimiter}
("entity"{tuple_delimiter}"Cruz"{tuple_delimiter}"person"{tuple_delimiter}"Cruz is associated with a vision of control and order, influencing the dynamics among other characters."){record_delimiter}
("entity"{tuple_delimiter}"The Device"{tuple_delimiter}"technology"{tuple_delimiter}"The Device is central to the story, with potential game-changing implications, and is revered by Taylor."){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Taylor"{tuple_delimiter}"Alex is affected by Taylor's authoritarian certainty and observes changes in Taylor's attitude towards the device."{tuple_delimiter}7){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Jordan"{tuple_delimiter}"Alex and Jordan share a commitment to discovery, which contrasts with Cruz's vision."{tuple_delimiter}6){record_delimiter}
("relationship"{tuple_delimiter}"Taylor"{tuple_delimiter}"Jordan"{tuple_delimiter}"Taylor and Jordan interact directly regarding the device, leading to a moment of mutual respect and an uneasy truce."{tuple_delimiter}8){record_delimiter}
("relationship"{tuple_delimiter}"Jordan"{tuple_delimiter}"Cruz"{tuple_delimiter}"Jordan's commitment to discovery is in rebellion against Cruz's vision of control and order."{tuple_delimiter}5){record_delimiter}
("relationship"{tuple_delimiter}"Taylor"{tuple_delimiter}"The Device"{tuple_delimiter}"Taylor shows reverence towards the device, indicating its importance and potential impact."{tuple_delimiter}9){completion_delimiter}
#############################
Example 2:
Entity_types: [person, technology, mission, organization, location]
Text:
They were no longer mere operatives; they had become guardians of a threshold, keepers of a message from a realm beyond stars and stripes. This elevation in their mission could not be shackled by regulations and established protocols—it demanded a new perspective, a new resolve.
Tension threaded through the dialogue of beeps and static as communications with Washington buzzed in the background. The team stood, a portentous air enveloping them. It was clear that the decisions they made in the ensuing hours could redefine humanity's place in the cosmos or condemn them to ignorance and potential peril.
Their connection to the stars solidified, the group moved to address the crystallizing warning, shifting from passive recipients to active participants. Mercer's latter instincts gained precedence— the team's mandate had evolved, no longer solely to observe and report but to interact and prepare. A metamorphosis had begun, and Operation: Dulce hummed with the newfound frequency of their daring, a tone set not by the earthly
#############
Output:
("entity"{tuple_delimiter}"Washington"{tuple_delimiter}"location"{tuple_delimiter}"Washington is a location where communications are being received, indicating its importance in the decision-making process."){record_delimiter}
("entity"{tuple_delimiter}"Operation: Dulce"{tuple_delimiter}"mission"{tuple_delimiter}"Operation: Dulce is described as a mission that has evolved to interact and prepare, indicating a significant shift in objectives and activities."){record_delimiter}
("entity"{tuple_delimiter}"The team"{tuple_delimiter}"organization"{tuple_delimiter}"The team is portrayed as a group of individuals who have transitioned from passive observers to active participants in a mission, showing a dynamic change in their role."){record_delimiter}
("relationship"{tuple_delimiter}"The team"{tuple_delimiter}"Washington"{tuple_delimiter}"The team receives communications from Washington, which influences their decision-making process."{tuple_delimiter}7){record_delimiter}
("relationship"{tuple_delimiter}"The team"{tuple_delimiter}"Operation: Dulce"{tuple_delimiter}"The team is directly involved in Operation: Dulce, executing its evolved objectives and activities."{tuple_delimiter}9){completion_delimiter}
#############################
Example 3:
Entity_types: [person, role, technology, organization, event, location, concept]
Text:
their voice slicing through the buzz of activity. "Control may be an illusion when facing an intelligence that literally writes its own rules," they stated stoically, casting a watchful eye over the flurry of data.
"It's like it's learning to communicate," offered Sam Rivera from a nearby interface, their youthful energy boding a mix of awe and anxiety. "This gives talking to strangers' a whole new meaning."
Alex surveyed his team—each face a study in concentration, determination, and not a small measure of trepidation. "This might well be our first contact," he acknowledged, "And we need to be ready for whatever answers back."
Together, they stood on the edge of the unknown, forging humanity's response to a message from the heavens. The ensuing silence was palpable—a collective introspection about their role in this grand cosmic play, one that could rewrite human history.
The encrypted dialogue continued to unfold, its intricate patterns showing an almost uncanny anticipation
#############
Output:
("entity"{tuple_delimiter}"Sam Rivera"{tuple_delimiter}"person"{tuple_delimiter}"Sam Rivera is a member of a team working on communicating with an unknown intelligence, showing a mix of awe and anxiety."){record_delimiter}
("entity"{tuple_delimiter}"Alex"{tuple_delimiter}"person"{tuple_delimiter}"Alex is the leader of a team attempting first contact with an unknown intelligence, acknowledging the significance of their task."){record_delimiter}
("entity"{tuple_delimiter}"Control"{tuple_delimiter}"concept"{tuple_delimiter}"Control refers to the ability to manage or govern, which is challenged by an intelligence that writes its own rules."){record_delimiter}
("entity"{tuple_delimiter}"Intelligence"{tuple_delimiter}"concept"{tuple_delimiter}"Intelligence here refers to an unknown entity capable of writing its own rules and learning to communicate."){record_delimiter}
("entity"{tuple_delimiter}"First Contact"{tuple_delimiter}"event"{tuple_delimiter}"First Contact is the potential initial communication between humanity and an unknown intelligence."){record_delimiter}
("entity"{tuple_delimiter}"Humanity's Response"{tuple_delimiter}"event"{tuple_delimiter}"Humanity's Response is the collective action taken by Alex's team in response to a message from an unknown intelligence."){record_delimiter}
("relationship"{tuple_delimiter}"Sam Rivera"{tuple_delimiter}"Intelligence"{tuple_delimiter}"Sam Rivera is directly involved in the process of learning to communicate with the unknown intelligence."{tuple_delimiter}9){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"First Contact"{tuple_delimiter}"Alex leads the team that might be making the First Contact with the unknown intelligence."{tuple_delimiter}10){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Humanity's Response"{tuple_delimiter}"Alex and his team are the key figures in Humanity's Response to the unknown intelligence."{tuple_delimiter}8){record_delimiter}
("relationship"{tuple_delimiter}"Control"{tuple_delimiter}"Intelligence"{tuple_delimiter}"The concept of Control is challenged by the Intelligence that writes its own rules."{tuple_delimiter}7){completion_delimiter}
#############################
-Real Data-
######################
Entity_types: {entity_types}
Text: {input_text}
######################
Output:
"""
Clustering
가장 아래의 0번째 Local Information을 정의하였다면, hierarchical하게 architecture를 구성하기 위하여 i번째 Layer를 구성하는 방법이다. 해당 과정은 아래와 같다.
Step1. Embedding
$$\begin{equation} Z_{i-1} = \{ \text{Embedding}(v) | v \in L_{i-1} \} \end{equation} $$
$$\begin{equation} \text{s.t.} L_{i} = V_{i}, i \geq 1 \end{equation} $$
수식을 살펴보면 간단하다. 먼저, i-1번째의 entity를 모두 Embedding하여 \(Z_{i-1}\)로 지정한다. 실제 코드에서 구현한 것을 확인하면 아래와 같다.
- Model List
- Open AI embedding-3
- Deepseek
- V: Entity의 Description을 Embedding하여 사용
Step2. Clustering
$$\begin{equation} C_{i-1} = \text{GMM}(L_{i-1}, Z_{i-1}) = \{ S_1, \ldots, S_c \} \end{equation} $$
$$\begin{equation} \text{s.t.} \forall x,y \in [1,c], S_{x} \cap S_{y} = \emptyset, \cup_{1 \le x \le c}S_x = L_{i-1} \end{equation} $$
위의 수식을 살펴보게 되면, 먼저 Embedding Model은 Gaussian Mixture Model로서 Clustering을 진행하였다. Cluster의 갯수는 c개로 지정하였다. 위의 과정을 진행하게 되면, Entitiy Description기준으로 각각의 Entity를 Clustering을 진행 할 수 있다.
Appendix: Number of clusters
해당 논문에서는 적절한 cluster의 갯수를 define하여 진행하지 않고, 아래와 같이 지정하였다.
- max_cluster의 갯수는 50개로 제한한다. (Entity가 50개가 되지 않으면 Entity 갯수가 max_cluster의 갯수)
- Cluster의 갯수를 1개로 제한하고 BIC (Bayesian Information Criterion)을 확인한다.
- Cluster의 갯수를 비교해가면서, BIC가 최적인 cluster의 갯수를 확인한다.
- 단, early stopping을 적용하여, threshold로서 BIC performance변화는 계속하여 Tracking한다.
Step3. Make Clustering Entity Description
Cluster로서 각각의 \(S_i\)를 지정하였다. 해당 Cluster들은 기존의 Entity (\(V_i\))의 관이 entity_name, entity_type, entity_description이 정해져 있지 않다. 또한 Relationship (\(\epsilon_i\))또한 정애져 있지 않다. 아래 과정은 해당 값을 정의하기 위한 과정이고, 또한 \(V_{i-1}, \epsilon_{i-1}\)과의 관계또한 정의한다.
위의 과정을 수식으로 나타내면 아래와 같다.
$$\begin{equation} \epsilon_{i} = \epsilon_{i} \cup \epsilon_{ \{i-1, i \} } \end{equation} $$
$$\begin{equation} V_i = V_{i-1} \cup L_{i} \end{equation}$$
$$\begin{equation} \mathcal{g}_i = \{ (h,r,t)|h,t \in V_i, r \in \epsilon_i \} \end{equation}$$
위의 과정은 논문 저자들은 아래와 같이 정의하였다.
- LLM Model을 사용하는 이상, max_token의 길이는 정해져 있다. 해당 token의 길이를 맞추기 위하여, cluster된 entity안의 description과 name을 합친 token의 길이가 max_token(default=6000)이 되지 않게 random sampling을 진행한다. base값은 50% sample만 사용하며, 만약 max_token을 넘어가게 된다면, 점차적으로 sample의 수를 낮춰 해당 조건을 만족할 때까지 반복한다.
- 해당과정을 아래 Prompt로서 LLM에 질문을던져, cluster의 enrirt_name, entity_type, entity_description을 생성한다.
- 기존 Entity와 새롭게 정의한 cluster간의 relationship또한 LLM으로 같이 생성하게 된다. (2와 같은 Prompt)
Appendix. summary cluster prompt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
PROMPTS[
"summary_clusters"
] = """You are tasked with analyzing a set of entity descriptions and a given list of meta attributes. Your goal is to summarize at least one attribute entity for the entity set in the given entity descriptions. And the summarized attribute entity must match the type of at least one meta attribute in the given meta attribute list (e.g., if a meta attribute is "company", the attribute entity could be "Amazon" or "Meta", which is a kind of meta attribute "company"). And it shoud be directly relevant to the entities described in the entity description set. The relationship between the entity set and the generated attribute entity should be clear and logical.
-Steps-
1. Identify at least one attribute entity for the given entity description list. For each attribute entity, extract the following information:
- entity_name: Name of the entity, capitalized
- entity_type: One of the following types: [{meta_attribute_list}], normal_entity means that doesn't belong to any other types.
- entity_description: Comprehensive description of the entity's attributes and activities
Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>
2. From each given entity, identify all pairs of (source_entity, target_entity) that are *clearly related* to the attribute entities identified in step 1. And there should be no relations between the attribute entities.
For each pair of related entities, extract the following information:
- source_entity: name of the source entity, as given in entity list
- target_entity: name of the target entity, as identified in step 1
- relationship_description: explanation as to why you think the source entity and the target entity are related to each other
- relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity
Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_strength>)
3. Return output in English as a single list of all the entities and relationships identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter.
4. When finished, output {completion_delimiter}
######################
-Example-
######################
Input:
Meta attribute list: ["company", "location"]
Entity description list: [("Instagram", "Instagram is a software developed by Meta, which captures and shares the world's moments. Follow friends and family to see what they're up to, and discover accounts from all over the world that are sharing things you love."), ("Facebook", "Facebook is a social networking platform launched in 2004 that allows users to connect, share updates, and engage with communities. Owned by Meta, it is one of the largest social media platforms globally, offering tools for communication, business, and advertising."), ("WhatsApp", "WhatsApp Messenger: A messaging app of Meta for simple, reliable, and secure communication. Connect with friends and family, send messages, make voice and video calls, share media, and stay in touch with loved ones, no matter where they are")]
#######
Output:
("entity"{tuple_delimiter}"Meta"{tuple_delimiter}"company"{tuple_delimiter}"Meta, formerly known as Facebook, Inc., is an American multinational technology conglomerate. It is known for its various online social media services."){record_delimiter}
("relationship"{tuple_delimiter}"Instagram"{tuple_delimiter}"Meta"{tuple_delimiter}"Instagram is a software developed by Meta."{tuple_delimiter}8.5){record_delimiter}
("relationship"{tuple_delimiter}"Facebook"{tuple_delimiter}"Meta"{tuple_delimiter}"Facebook is owned by Meta."{tuple_delimiter}9.0){record_delimiter}
("relationship"{tuple_delimiter}"WhatsApp"{tuple_delimiter}"Meta"{tuple_delimiter}"WhatsApp Messenger is a messaging app of Meta."{tuple_delimiter}8.0){record_delimiter}
#############################
-Real Data-
######################
Input:
Meta attribute list: {meta_attribute_list}
Entity description list: {entity_description_list}
#######
Output:
"""
Global Information
위에서 정의한 내용을 정리하면 아래와 같다.
- Input으로 들어오는 Document를 기준으로 Entity를 생성하고, Graph구조를 만든다.
- 각각의 Entity를 Clustering하여, Hierarchical한 구조를 만들었다.
- 해당 과정을 통하여 Local Information을 Relationship을 고려하여 사용할 수 있다.
Local Information을 제외하고, Global Information을 활용하기 위해서는 추가적인 작업이 필요하다. 해당 논문의 저자들은 다른 논문 (GraphRAG, LightRAG)에서도 사용한 Leiden algorithm (From Louvain to Leiden: guaranteeing well-connected communities)을 통하여, community ($p \in P$)를 생성하였다.
Appendix. Leiden Algorithm
해당 Algorithm은 자세하게 파악하지는 못하였다. 대략적인 특징을 조사하였을 떄는 아래와 같다.
- 입력: 그래프 전체 (노드 + 엣지)
- 출력: 분리된 노드 집합 (communities)
- 특징:
- 큰 커뮤니티 내부에서도 더 밀접하게 연결된 노드 집합이 감지됨
- 해당 group들은 하위 community로 지정
Global Infromation
Make Community Report
Global Information으로 사용하기 위하여 지정한 Community (\(P\))를 이용하여 Text정보를 얻어내는 과정이다.
해당 과정도 토큰이 긴 경우에 다음과 같이 Chunk하여 결과를 확인하였다.
- Community의 Token수가 너무 긴 경우 -> Sub Community를 활용하여 재귀적으로 Text정보 확인
- Sub Community를 선택하게 되면 -> 해당 Community에 맞는 entity, relationship만 filtering하는 과정 필요
- Sub Community를 선택하여도 Token이 너무 긴 경우 -> 강제로 잘라서 활용 (나머지는 drop)
Text정보는 아래와 같은 Prompt Format을 활용하여 생성하였다.
Appendix: Community Report Prompt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
PROMPTS[
"community_report"
] = """You are an AI assistant that helps a human analyst to perform general information discovery.
Information discovery is the process of identifying and assessing relevant information associated with certain entities (e.g., organizations and individuals) within a network.
# Goal
Write a comprehensive report of a community, given a list of entities that belong to the community as well as their relationships and optional associated claims. The report will be used to inform decision-makers about information associated with the community and their potential impact. The content of this report includes an overview of the community's key entities, their legal compliance, technical capabilities, reputation, and noteworthy claims.
# Report Structure
The report should include the following sections:
- TITLE: community's name that represents its key entities - title should be short but specific. When possible, include representative named entities in the title.
- SUMMARY: An executive summary of the community's overall structure, how its entities are related to each other, and significant information associated with its entities.
- IMPACT SEVERITY RATING: a float score between 0-10 that represents the severity of IMPACT posed by entities within the community. IMPACT is the scored importance of a community.
- RATING EXPLANATION: Give a single sentence explanation of the IMPACT severity rating.
- DETAILED FINDINGS: A list of 5-10 key insights about the community. Each insight should have a short summary followed by multiple paragraphs of explanatory text grounded according to the grounding rules below. Be comprehensive.
Return output as a well-formed JSON-formatted string with the following format:
title,
summary
...
]
}}
# Grounding Rules
Do not include information where the supporting evidence for it is not provided.
# Example Input
-----------
Text:
Entities:
id,entity,type,description
5,VERDANT OASIS PLAZA,geo,Verdant Oasis Plaza is the location of the Unity March
6,HARMONY ASSEMBLY,organization,Harmony Assembly is an organization that is holding a march at Verdant Oasis Plaza
Relationships:
id,source,target,description
37,VERDANT OASIS PLAZA,UNITY MARCH,Verdant Oasis Plaza is the location of the Unity March
38,VERDANT OASIS PLAZA,HARMONY ASSEMBLY,Harmony Assembly is holding a march at Verdant Oasis Plaza
39,VERDANT OASIS PLAZA,UNITY MARCH,The Unity March is taking place at Verdant Oasis Plaza
40,VERDANT OASIS PLAZA,TRIBUNE SPOTLIGHT,Tribune Spotlight is reporting on the Unity march taking place at Verdant Oasis Plaza
41,VERDANT OASIS PLAZA,BAILEY ASADI,Bailey Asadi is speaking at Verdant Oasis Plaza about the march
43,HARMONY ASSEMBLY,UNITY MARCH,Harmony Assembly is organizing the Unity March
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Output:
title,
summary,
summary,
summary
]
}}
# Real Data
Use the following text for your answer. Do not make anything up in your answer.
Text:
{input_text}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
The report should include the following sections:
- TITLE: community's name that represents its key entities - title should be short but specific. When possible, include representative named entities in the title.
- SUMMARY: An executive summary of the community's overall structure, how its entities are related to each other, and significant information associated with its entities.
- IMPACT SEVERITY RATING: a float score between 0-10 that represents the severity of IMPACT posed by entities within the community. IMPACT is the scored importance of a community.
- RATING EXPLANATION: Give a single sentence explanation of the IMPACT severity rating.
- DETAILED FINDINGS: A list of 5-10 key insights about the community. Each insight should have a short summary followed by multiple paragraphs of explanatory text grounded according to the grounding rules below. Be comprehensive.
Return output as a well-formed JSON-formatted string with the following format:
title,
summary
...
]
}}
# Grounding Rules
Do not include information where the supporting evidence for it is not provided.
Output:
"""
Determining the Number of Layers
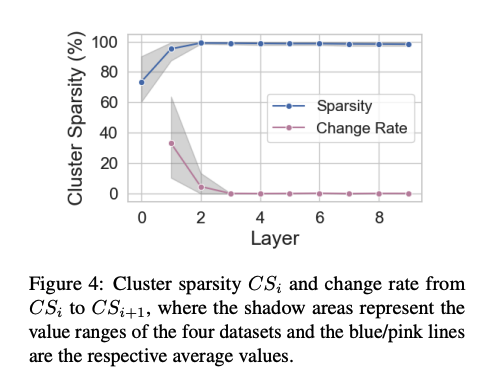
위에서, HiIndex를 활용하여 Hierarchical하게 Layer를 1개 쌓는 방법에 대해 얘기한다. 여기서 해당 논문의 저자들은 몇개의 Layer를 만들어야 되는지도 Hyperparameter로서 선택하는 방법을 소개한다.
$$\begin{equation} \text{CS}_i = 1 - \frac{\sum_{S \in C_{i}} |S| (|S|-1)}{|L_i| (|L_i| - 1)} \end{equation} $$
- \(\text{CS}_i\): i-th Layer에서 Cluster가 잘 되었는지 판단하는 Metric (Cluster Sparsity)
- \(C_i\): i-th Layer의 클러스터 집합
- \(|S|\): 개별 클러스터안의 엔티티수
- \(|L_i|\): i-th Layer의 총 Entity 갯수
위의 수식을 차례대로 생각하면 아래와 같다.
- \(|L_i|\)는 고정된 값으로서 metric의 분모의 값은 고정이다. 즉, 몇개의 cluster (\(|C_i|\))이냐, 그리고 각각의 클러스터 안에 몇개의 entity가 포함되어 있냐 (\(|S|\))에 따라 metric은 결정된다.
- \(\text{CS}_i\)는 값이 적을수록 밀집된 클러스터로서 좋은 cluster로 판단하는 metric이다.
- 즉, cluster의 갯수는 적을수록, cluster의 갯수가 동일하다면 cluster내의 entity가 많이 응집된 cluster가 있을수록 점수가 좋다.
해당 수식은 결과적으로 “의미 있는 응집력 을 강조하며, 작은 클러스터가 흩어지는 것보다 큰 덩어리가 있는것이 더 좋은 clustering결과 라고 판단”
해당 논문의 저자들은, \(i-i\)과 \(i\) layer의 \(\text{CS}_i\)차이가 5% 될때까지 진행하였다고 한다. (실제 Figure를 보게 되면, 1개의 Layer로도 충분한 것을 알 수 있다.)
Retrieval with Hierarchical Knowledge
설명하기 앞서, 해당 논문에서 제안하는 HiRetrieval의 Algirithm은 아래와 같습니다.

Local Information
먼저, Local Information을 활용하기 위하여, Entitiy 자체의 정보를 사용하여야 한다. 위에서 Graph가 \(k\)개의 Layer로서 구성되어있다고 가정하자.
먼저, 최상위 Layer에서 관련된 Entity를 뽑는 것은 아래와 같이 적을 수 있다.
$$\begin{equation} \hat V = \text{TopN}(\{ v \in V_{k} | \text{Sim}(q,v) \}, n) \end{equation} $$
위의 식에서 논문 저자들은 n을 20으로 제한하였고, \(\text{Sim}(\cdot)\)은 semantic similarity로 찾았다.
Global Infromation
Global 정보는 위에서 정의한 Community를 활용하여 선택하게 된다.
$$\begin{equation} \hat P = \cup_{p \in P} \{ p|p \cap \hat V \neq \emptyset \} \end{equation} $$
Bridge Information
우리는 Local Information과 GLobal Information을 모두 사용하나, 결국 해당 Information을 이어줄 “Bridge Information” (\(R\))을 사용하여야 한다. 해당 Information의 식은 아래와 같다. 해당 과정은 아래와 같다.
Step 1. Community와 관련된 Entity를 m개 선택한다. Community는 위에서 선택한 $\hat V$이다. 수식으로 나타내면 아래와 같다.
$$\begin{equation} \hat V_{p} = \cup_{p \in \hat P} \text{TopN} (\{ v \in p | \text{Sim}(q,v) \}, m) \end{equation} $$
Step 2. Step 1의 결과에서 ShortestPath를 뽑을 수 있는 RelationShip을 모두 선택한다. 수식으로 나타내면 아래와 같다.
$$\begin{equation} R = \cup_{i\in [1, | \hat V_{\hat P} | -1]} \text{ShortestPath}_{g_k} (\hat V_{\hat P}[i], \hat V_{\hat P}[i+1]) \end{equation} $$
Step 3. Step 2에서 얻은 결과를 모두 합하여 Bridge 정보로서 활용한다.
$$\begin{equation} \hat R = \{ (h,r,t) \in g_k | h,t \in R \} \end{equation} $$
Why is HiRAG effective?
해당 chapter는 왜 HiRAG가 다른 RAG방법에 대해 성능이 좋은지 정리한다.
- Addressing Challenge: HiIndex는 상위 계층에 요약 엔티티(summary entities) 를 도입함으로써, 하위 계층에서 멀리 떨어진 엔티티 간의 의미적 거리를 줄입니다.
- Resolving Challenge: HiRetrieval은 질문과 의미적으로 관련된 상위 엔티티들(top-n entities) 을 기반으로 추론 경로(reasoning paths) 를 구성합니다.
- Synthesis: HiRAG는 (1) 계층적 지름길을 통해 의미적으로 유사한 엔티티를 연결하고, (2) 전역 커뮤니티 맥락을 포함시키며, (3) 지역과 전역 정보를 최적 경로로 연결함으로써, 문맥을 반영한 포괄적 답변을 생성합니다.
Experiment
논문에서의 결과는 다른 기존 Model보다 성능이 좋다는 것을 증명하고 있다. Ablation Study결과 또한 제시하여, 제안하는 방법들이 모두 효과적이라는것을 확인할 수 있다.

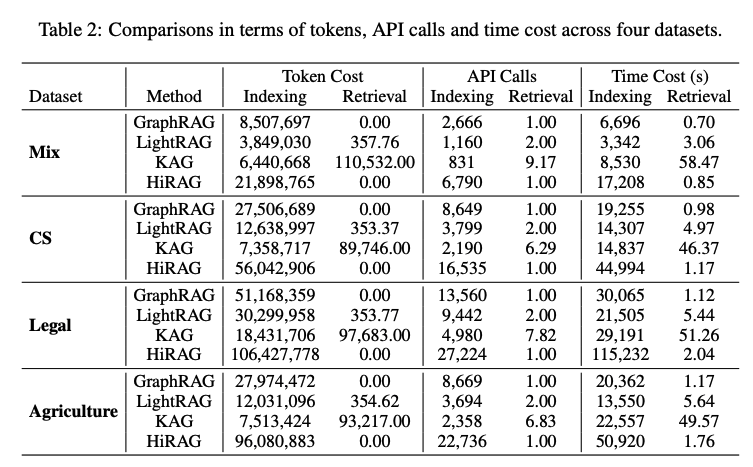
Efficiency and Costs Analysis
해당 결과는 가격 및 시간이 얼마나 걸리는지 알려준다. 확인을 하게 되면, Retrieval에서는 Graph기반으로 검색하기 때문에, 돈이 들지 않는 것을 확인할 수 있다. 특히, Retrieval에서는 Token Cost가 0인 것을 확인할 수 있다. 하지만, Indexing에서는 다른 Model에 비하여 많은 API Call과 Time Cost가 발생하는 것을 알 수 있다. Hierarchical한 Indexing을 구성하기 위한, 당연한 결과로 보인다. 즉, 초기 Indexing으로서 Graph를 구축하는데에는 시간과 Cost가 많이 소모 되지만, 구축 이후에는 Retrieval과 성능은 다른 모델에 비하여 압도적이라는 주장이다. (p.s. 이러한 결과로서 Service에 적합한 방법이라고 소개하고 있다.)
Limitation
- 위에서 “Efficiency and Costs Analysis”에서도 알 수 있듯이, KG를 구축하는데 비용과 많이 시간이 필요하다.
- 실질적인 Relationship의 weight를 LLM으로 생성한다. 즉, 우리가 생각한 값이나, 지정한 값이 아니다. 해당 weight를 지정하는 방법은 future work로서 잘 지정하는 연구가 필요하다.
Leave a comment