
P5
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
Abstract
For a long time, different recommendation tasks typically require designing task-specific architectures and training objectives. As a result, it is hard to transfer the learned knowledge and representa- tions from one task to another, thus restricting the generalization ability of existing recommendation approaches, e.g., a sequential recommendation model can hardly be applied or transferred to a review generation method. To deal with such issues, considering that language can describe almost anything and language grounding is a powerful medium to represent various problems or tasks, we present a flexible and unified text-to-text paradigm called “Pretrain, Personalized Prompt, and Predict Paradigm” (P5) for recommendation, which unifies various recommendation tasks in a shared framework. In P5, all data such as user-item interactions, user descriptions, item metadata, and user reviews are converted to a common format — natural language sequences. The rich information from natural language assists P5 to capture deeper semantics for personalization and recommendation. Specifically, P5 learns different tasks with the same language modeling objective during pretraining. Thus, it serves as the foundation model for various downstream recommendation tasks, allows easy integration with other modalities, and enables instruction-based recommendation based on prompts. P5 advances recommender systems from shallow model to deep model to large model, and will revolutionize the technical form of recommender systems towards universal recom- mendation engine. With adaptive personalized prompt for different users, P5 is able to make predictions in a zero-shot or few-shot manner and largely reduces the necessity for extensive fine-tuning. On several recommendation benchmarks, we conduct experiments to show the effectiveness of P5. To help advance future research on Recommendation as Language Processing (RLP), Personalized Foundation Models (PFM), and Universal Recommendation Engine (URE), we release the source code, dataset, prompts, and pretrained P5 model at https://github.com/jeykigung/P5. Meanwhile, P5 is also hosted on Hugging Face at https://huggingface.co/makitanikaze/P5.
이전 까지의, LLM을 활용한 Recommendation은 하나의 Task밖에 수행하지 못하였다. 즉, Prediction을 할 것이냐, 혹은 Regression, Explanation등 다양한 Task에서 수행하지 못하였다. 이러한 방식은 추천 접근 방식의 일반화 능력을 제한하였다. 해당 논문의 저자들은 T5 Model을 Base로서 P5 Model을 제안한다. 제안하는 P5 Model은 개인화 추천 뿐만 아니라 다른 task와도 쉽게 조합 가능합니다. 또한, 이러한 여러 Task를 통합하여 수행하면, 기존에는 확인하지 못하였던, 정보까지 활용하게 되어 추천의 성능을 높일 수 있다.
Model Architecture
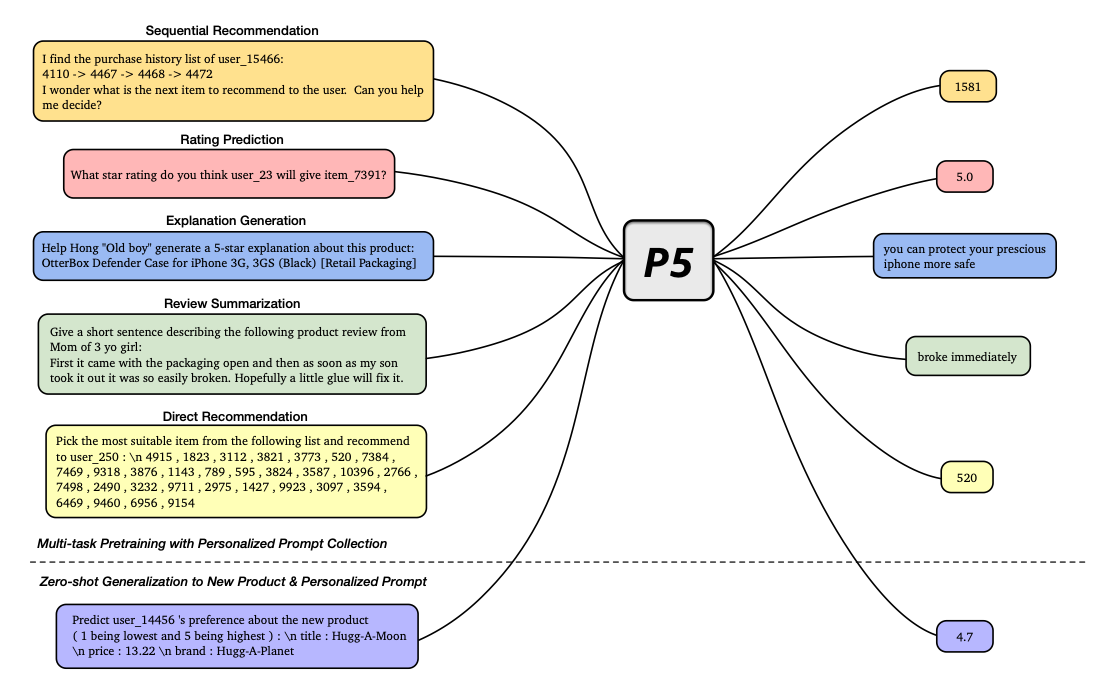
해당 Model은 Backbone을 T5로 사용하여, 추천 Model로서 학습하는 방법이다. 학습 방법은 위와 같다. 그 전에 T5의 장점을 리마인드하면 아래와 같다.
T5 장점
- Input과 Output이 Text로 들어가는 seq-to-seq의 Transformer 구조 이다. 따라서, Input과 Target이 모두 Text이다.
- 따라서 Dataset을 Text로 구성하면, 여러 Task에서 동일한 Model로서 학습할 수 있다.
- 이러한 여러 Task에서 Training하는 것은 Zero-shot에서 다른 LLM Model들에 비하여 좋은 Performance를 보여준다.
위와 같은 동일한 구조의 P5는 아래와 같이 데이터 셋을 구성하였다.
- Sequential Recommendation: User가 구매하였던 history를 input으로 받아 다음 Target을 예측한다.
- Rating Prediction: User가 Item에 대하여 rating이 몇점인지 예측한다.
- Explanation Generation: Review내용을 왜 구매했는지 Explanation Generation에 사용한다
- Review Summarization: 특정 Keyword로서 내용 요약하도록 학습한다.
- 실제 User와 Item Candidate(19개의 Random + 1개의 Positive)를 보고 바로 추천하도록 학습한다.
조금 더 자세한 Dataset 구성은 아래 Figure와 같다.
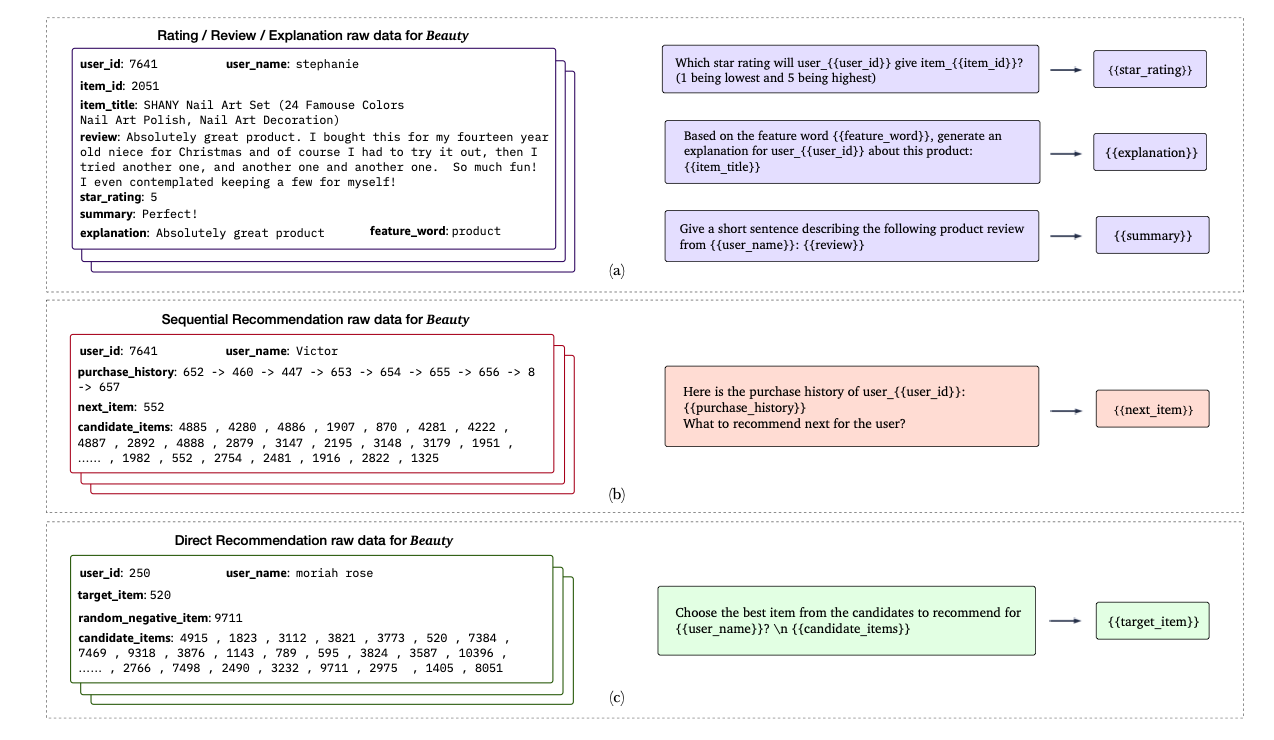
P5 Architecture
기존 T5에 비하여 P5에서 주요한 점은 크게 2가지 이다.
- Token을 새롭게 만들었다. 예를 들어, item_7391 은 기존의 T5 Tokenizer를 사용하면 -> [item, _, 73, 91] 로서 4개의 Toekn으로 구분된다. 이러한 방법은 personalized information을 해친다 판단하여, item과 user의 각각의 toekn을 모두 추가하여 사용하였다.
- Gird Search 가 아닌 Beam Search로서 Output을 Inference하였다.
Appendix: Grid Search vs Beam Search
해당 Section은 Software Blog을 참조하였습니다.
Grid Search
기존의 Transformer에서 Output을 뽑기 위한 Inference는 Grid Search로서 이루워 졌다. Grid Search는 아래 Figure와 같이 Inferencer가 진행됩니다.
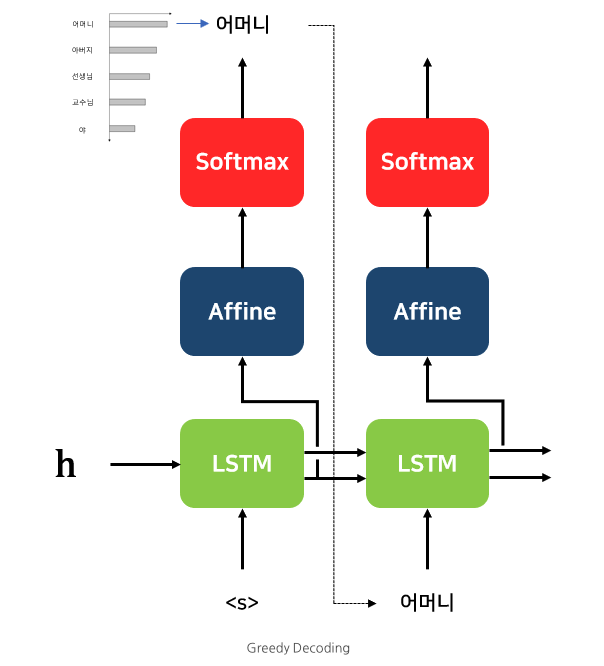
위의 과정을 살펴보면, 단순히 t 시점에서 가장 높은 확률을 가진 Token을 선택하고, 다음 입력으로 사용하는 방법 입니다. 최종 정확도 관점에서는 좋지 못한 방법이다.
특정 시점 t에서의 확률 분포 상에서 상위 1등과 2등의 확률 차이가 작든 크든, Greedy Decoding 방식은 무조건 가장 큰 놈에게만 관심이 있을 뿐이다. (1등과 2등의 차이가 정말 미묘하다면, 2등이 정답일 경우도 고려해주어야 할 것이다)
이러한 예측에서 한 번이라도 틀린 예측이 나오게 된다면, 이전 예측이 중요한 디코딩 방식에서는 치명적인 문제가 된다.
Beam Search
위의 Grid Search의 어느정도 단점을 해결한 방법이 Beam Search방법 입니다. 해당 방법은, 아래 Figure와 같습니다.
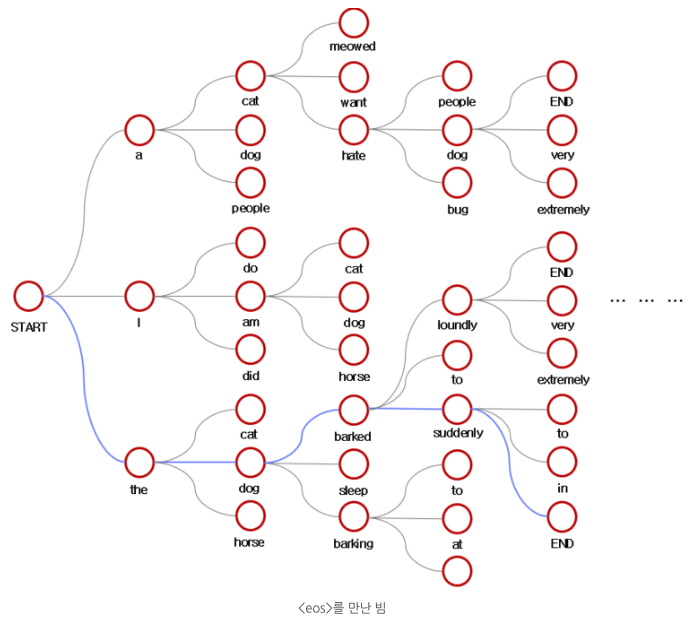
해당 방법은 K개의 Token을 찾은뒤, 해당 누적확률이 높은 K개의 선택지를
Future Work: 아직, Recommend System에서 Decoder의 Output을 Beam Search하는 방법은 잘 모르겠습니다. Explain Generation이나 Review Summarization Task에서는 사용 가능하나, Sequential Recommendation, Rating Prediction, Direct Recommendation에서는 바로 적용하기 어려울 것 같습니다. 해당 부분에 대해서는 코드를 살펴보아야 할 것 같습니다.
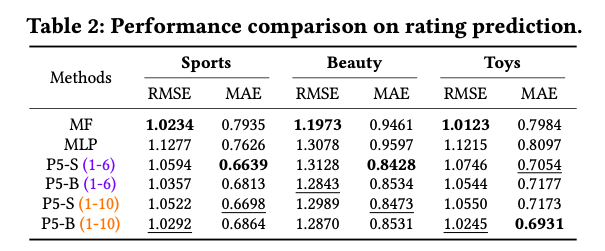
Experiment Result
수행한 많은 Task와 zero-shot에서의 성능을 비교하였지만, 간략하게 하나의 Task인 rating prediction에 대한 결과를 살펴보면, 아래와 같다.
Amazon Dataset
Yelp Dataset

- p5-S: T5-small을 backbone으로 사용한 P5 model 입니다.
- p5-B: T5-base을 backbone으로 사용한 P5 model 입니다.
위의 결과를 살펴보게 되면, MF와 MLP보다는 성능이 낮지만, Amazon에서는 어느정도 성능이 나오는 것을 알 수 있다. 또한, Amazon에서는 Model Size가 크면 클 수록 성능이 좋았지만, Yelp에서는 Model 크기와 성능이 차이가 없는 것을 알 수 있다.
Question
- MF와 MLP가 어떠한 Feature를 사용했는지 알 수 없습니다. Code와 Setting이 적혀있지 않아, 단순히 User-id, Item-id로서 평가한 성능일 수 있습니다.
- Time-complexity에 대해 적혀있지 않습니다. NVIDIA RTX A5000 GPUs를 4대 사용하였습니다. 10 epochs만큼 훈련하였다고 하는데, 정확히 얼마나 걸렸는지는 적혀있지 않습니다.
- Fair Competition은 아닌 것 같습니다. 모든 Code를 살펴보지 못하였지만, 현재 P5 Model은 5개의 Task에 대하여 모두 훈련한 뒤에 Prediction을 진행합니다. 즉, MF나 MLP보다 많은 Feature와 정보를 사용하였습니다.
Question
해당 논문을 살펴보면, 정말 많은 prompt로서 학습한 것을 알 수 있다. 아쉬운 점은 prompt의 평균으로서 Model Performance를 비교하지 않았다는 것 이다. 즉, 같은 Task여도 Prompt에 따라서 성능이 많이 좌우되는 것 같다. 이러한 Variance에 대한 실험 설계나 평과 결과가 없다는 것은, 실제 구현하였을 때, 성능 차이가 많이 날 수도 있다는 것 이다.
Leave a comment