
T5
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (T5)
Abstract
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts all text-based language problems into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled data sets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our data set, pre-trained models, and code.
T5 이전의 LLM의 모델의 과정은 아래와 같다.
Transformer -> GPT1 -> Bert -> GPT2
해당 과정에서 모두 주요하게 생각하는 것은 많은 Unlabeled Dataset (Corpus Dataset)으로 Pretraining을 진행한 후에 FineTuning or Transfer Learning으로서 Task-Specific Model을 만드는 것이다. 해당 논문에서는 이러한 LLM Model들이 공통적으로 수행하는 Pretraining 방법을 실험으로 비교하고, 새로운 Pretraining 방법을 제시한다. 이러한 실험은 C4 Dataset (Colossal Clean Crawled Corpus)으로서 비교하게 된다.
T5 Model
T5 (Text-to-Text Transfer Transformer) Model은 Transformer와 유사한 Architecture를 가지고 있다. 또한, 특징적으로 크게 바뀐 부분은 아래와 같다.
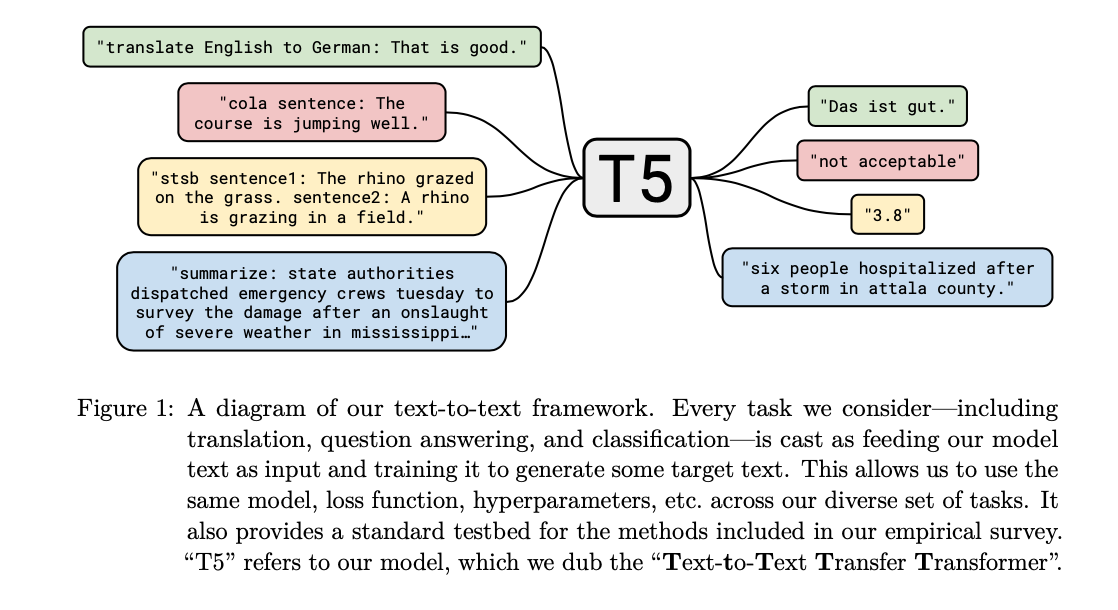
T5 Model의 핵심은 위의 Figure와 같이 모든 Task에 같은 Model구조를 사용한다는 것 이다. 이를 위해 Input과 Output을 모두 Text로 변환하는 것을 볼 수 있다.
위의 Figure를 보게 되면, translate, cola sentence, stsb sentense, summarize등 다양한 Task의 Data로서 학습하는 것을 살펴볼 수 있다.
또한, 이를 위하여 GPT에서 Fine Tuning과 같이 Model Architecture에 Linear Layer를 추가적으로 사용하는 것이 아닌 Seq-to-Seq기반의 Transformer Model의 Output으로 해당 Task의 Label을 Text로 변환하고 학습하는 것을 알 수 있다.
T5 Model에서 Transformer에서 바꾼 부분은 아래와 같다.
Positional Encoding: 기존에는 Sin, Cos Function으로서 Positional Encoding을 진행하였다. 하지만, Bert 기반의 Model로서 bidirectional에 대한 Position Information을 넣어주기 위하여 아래와 같이 수정하였다.

그림 출처: jeonsworld Blog
위의 결과를 보게 되면, 해당 되는 Token기준으로 가까운 Position일 수록 작은 값을 가지는 것을 알 수 있다.
Setup
해당 논문의 저자들은, FineTuning 방법을 비교하기 위하여 아래와 같은 setting에서 experiment를 수행하였다.
Dataset - C4 Dataset

그림 출처: analytics-vidhya
해당 논문의 저자들은 PreTraining할 Dataset으로 UnLabeled Dataset을 선택하였다. Common Crawl Dataset을 활용하였으며, Dataset을 Filtering하기 위하여 아래와 같이 Filtering 작업을 수행하였다.
- 종단 구두점( 반점, 느낌표, 물음표, 종료 인용부호)로 끝나는 라인만 유지한다.
- 5문장 이하의 페이지는 버리고, 최소 3글자 이상을 가진 라인만 유지한다.
- “List of Dirty, Naughty, Obscene or Otherwise Bad Words”에 속한 단어(더러운, 무례한, 음란한, 비속어)가 있는 페이지는 제거한다.
- 스크랩된 페이지의 대다수는 자바스크립트(Javascript)가 활성화 되어야 한다는 경고문을 포함한다. 따라서 자바스크립트 단어를 포함한 모든 라인을 제거한다.
- 일부 페이지는 “lorem ipsum”(내용보다 디자인 요소를 강조하기 위해 사용되는 텍스트) 플레이스홀더를 포함한다. 따라서 “lorem ipsum”구가 있는 모든 페이지를 제거한다.
- 일부 페이지에는 코드가 포함되어 있다. “{” 문구가 대다수의 프로그래밍 언어(웹에서 많이 사용되는 자바스크립트와 같이)에서 출몰하고 자연 텍스트에서는 나타나지 않기 때문에, “{” 를 포함한 모든 페이지를 제거한다.
- 데이터셋 중복을 제거하기 위해, 데이터셋에서 두 번 이상 나타난 3문장 스팬은 하나만 남기고 모두 제거한다.
또한, DownStream에서 수행할 Task의 대부분이 영어 텍스트 이기 때문에, 다른 언어는 Filtering하였다고 하고 있다.
Input and Output Format
해당 논문의 main contribution은 동일한 architecture로서 여러 task를 동시에 학습하는 finetuning방식을 제안하는 것 이다. 이에 따라 Dataset을 “text-to-text” 형식으로 수정하여야 한다. 해당 dataset변환은 아래와 같이 수정하였다.
- Translate: 영어 문장을 독일어로 변역하기 위해서 다음과 같이 prefix를 추가하였다. “translate English to German : That is good”
- Text Classification: 텍스트 분류를 위해서는 단순히 목표하는 라벨에 대응되는 하나의 단어를 예측한다.
이 외에 다양한 Task에 대한 데이터셋 변경은 위의 Figure에 나와있다.
Experiments
Training
LLM을 Training하기 위해서는 많은 Resource가 드는 것으로 알고 있지만, 실제 어느정도로 필요한지 확인하자. 해당 논문에서 사용하는 각 모델은 Finetuning전에 pre-training과정에서 C4데이터 셋을 활용하였고, \(2^{19}=524288\)스탭동안 합습되었다. max_seq_len-512, batch_size=128로 설정하였다. 이러한 세팅은 대략 \(2^{34} \approx 34B\)로서 BERT(2.2T), RoBERTa보다 훨씩 적은 수 이다.
또한, 사전학습 하는 동안, learning rate은 \(1/\sqrt{\text{max}(n,k)}\)이다. n은 iteration이며, k는 warm-up steps로서 \(10^4\)로서 고정되었다. \(10^4\)이후에는 계속해서 감소되면서 학습된다.
T5 Model은 FineTuning과정에서는 \(2^{18} = 262144\)스탭만큼 학습된다. learning rate의 경우에는 0.001로서 고정된다.
Unsupervised Objective

Pretraining에 사용된 dataset은 위와 같이 특정 단어를 masking하여 학습을 진행하였으며, mask는 특수한 token으로 대체되었다. 이러한 dataset은 라벨을 요구하지 않으면서, 모델에게 downstream task에 유용한 일반화 가능한 지식을 알려줄 수 있다.
위와 같은 결과를 살펴보면 아래와 같다.
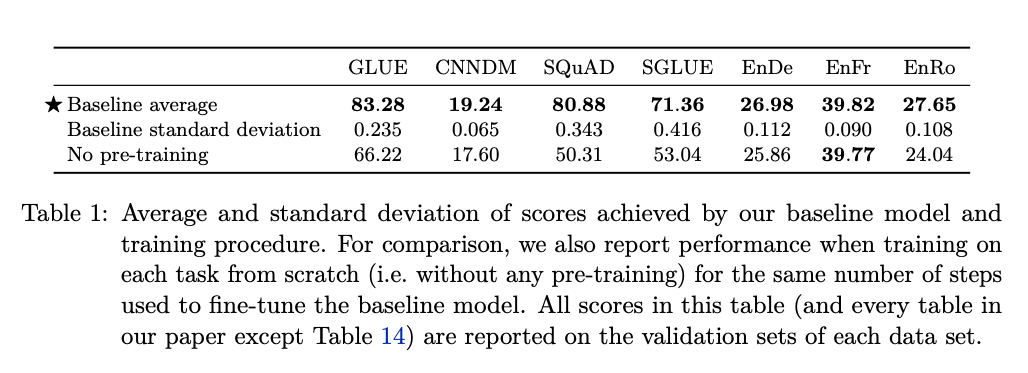
해당 결과를 살펴보면, 각 task에서 pre-training을 진행하지 않는 경우에는 model의 performance가 전반적으로 많이 낮은 것을 알 수 있다.
Architecture
해당 논문은 1. Encoder-decoder, 2. Language model, 3.Prefix LM으로서 3가지 Model의 성능을 비교 하였다. 먼저, Model을 보기전에 해당 Model에 적용하기 위한 Attention의 방법을 살펴보면 아래와 같다.
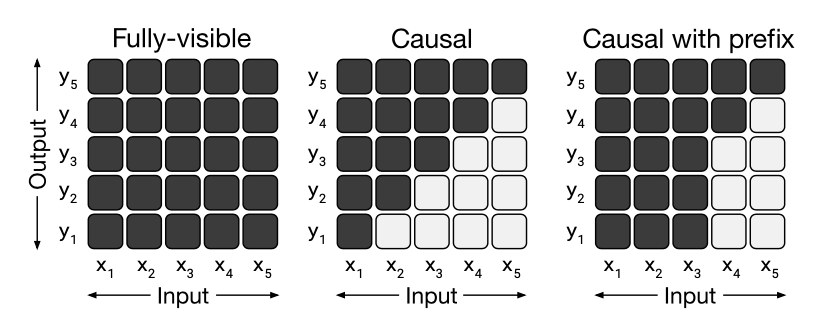
- 왼쪽은 Encoder-decoder를 위한 Attention Mask로서 모든, Input과 Output간의 관계를 살펴볼 수 있는 것을 알 수 있다.
- 가운데는 Language-Model (=GPT)의 구조로서, 다음 Sequence를 보지 못하는 형태인 것을 알 수 있다.
- 오른쪽은 Prefix LM으로서 특정 Sequence까지는 살펴보고, 나머지는 순차적으로 보는 형태를 취하게 된다.
위와 같은 Attention기법을 사용하여 만든 Model은 아래와 같다.
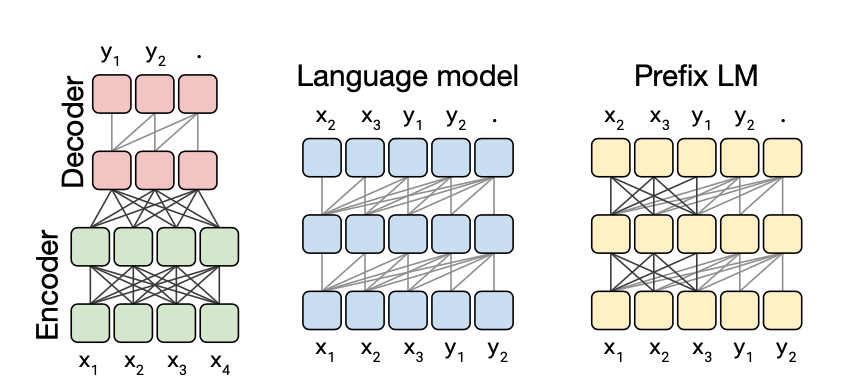
Result of pre-trained model
이러한 Unsupervised Objective, Architecture을 비교한 결과는 아래와 같다.
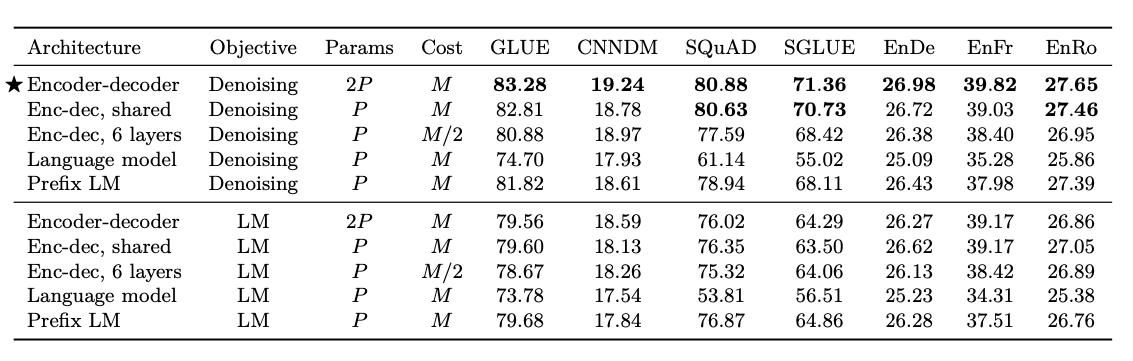
위의 결과를 살펴보면, 아래와 같은 결과를 얻을 수 있다.
1. Encoder-Decoder기반의 model은 Parameters가 2배이지만, 성능이 좋은 것을 알 수 있다.
2. Unsupervised Objective로서는 Denoising이 전반적으로 성능이 좋다. 즉, 몇몇 단어를 masking하여서 학습하는 것이 일반적인 문장의 내용을 잘 representation할 수 있다.
3. Encoder-Decoder와 성능은 유지하면서, parameter의 개수를 줄이는 방법은, encoder와 decoder의 parameter를 공유하는 방법이다.
해당 논문에서는 Encoder-Decoder기반이면서, Denoising Unsupervised Objective로서 학습된 Pre-Trained된 Model로서 DownStream을 진행하였다.
Unsupervised Objectives
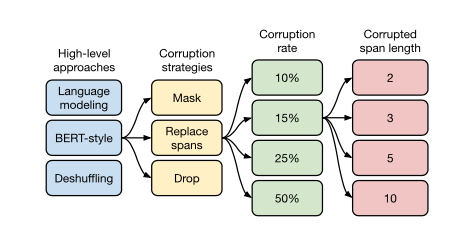
논문 저자들은 위와 같이 총 4개의 큰 Unsupervised Objectives을 모두 실험하였고, 최적의 조합을 찾는 과정을 모두 실험하였다.
High-level approaches & Corruption strategies
먼저, Dataset을 어떻게 구성할지에 대한 내용이다. 논문에서 Inputs과 Targets는 모두 아래와 같이 구성하였다.

위와같은 다양한 방식의 high-level approaches결과는 아래와 같다.
- Prefix language modeling: GPT와 같은 Standard Language modeling
- Bert-style: masked language modeling
- Deshuffling: sequence를 입력으로 받아 순서를 shuffling한 후 원래 sequence target으로 복구 하는 방식
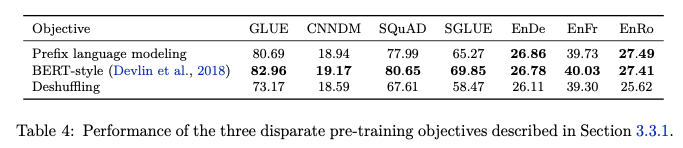
위에서 Bert-Style이 가장 좋은 방법인 것을 알았다. 해당 논문 저자들은 Bert-style을 조금더 구체적으로 나누어서 성능을 확인하였다.
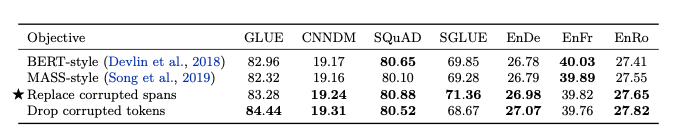
BERT는 Token단위로 Masking을 하는데 비하여 해당 논문은 span을 Masking하는 방식을 체택했다. 이러한 Mask Token은 Sentinel i토큰으로 Masking되고, 정답부분은 원래 Token이 들어가는 형태이다.
Corruption rate
두번째로는, 얼만큼을 Corruption할지 살펴본 결과이다.
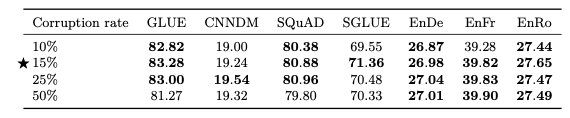
위의 결과와 같이 15%를 설정하였다.
Corrupted span length
마지막으로는, 몇개의 연속되는 Corruption할지 살펴본 결과이다.
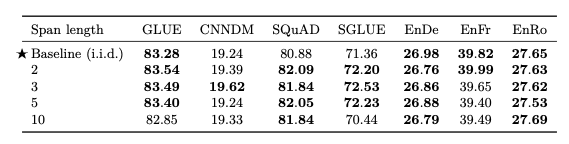
위의 결과는 Span의 길이가 너무 길지 않으면 (10) 성능이 비슷한 것을 알 수 있다. 해당 논문의 저자들은 span의 길이를 3으로서 사용하였다고 한다.
Pre-training Data set
Quality
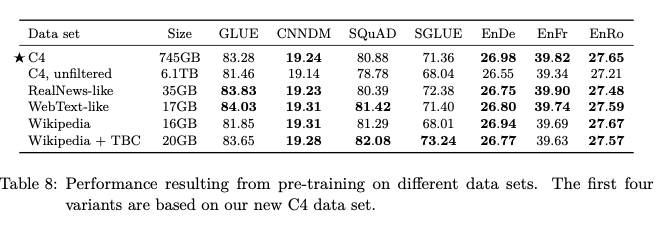
위의 결과는 여러 Dataset으로 Pretraing한 결과를 보여주고 있다. 주요한 점은, C4, unfiltered보다 C4로 Pre-Train한 것이 성능이 좋은 것을 알 수 있다. 이는 데이터셋의 크기 뿐만 아니라 품질또한 매우 중요하다는 것을 시사한다.
Datasetsize
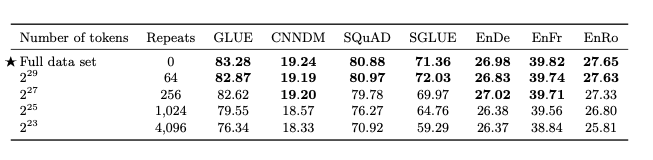
위의 실험은 데이터셋을 고정하고, 특정 횟수만큼 반복하여 Dataset의 크기를 맞춘 뒤 실험을 진행한 결과이다. 해당 결과를 살펴보게 되면, Full data set의 성능이 더 좋은 것을 확인할 수 있다. 즉, Dataset의 Quality뿐만 아니라, Dataset의 크기 또한 주요한 것을 알 수 있다.
Multi-task learning
기존에 Text-to-Test에서 multi-task learning은 어떤 테스크의 데이터를 얼마나 가져와서 학습하는지 비율을 찾는 것이 매우 중요하다. 따라서, 논문 저자들은 아래와 같은 공식으로 Dataset의 비율을 뽑고 학습을 진행하였다.
$$r_m = \text{min}(e_m, K) / \sum \text{min} (e_n, K)$$
- $n \in {1, \ldots, N }$: Number of tasks
- $K$: Artifical dataset set size limit
해당 결과는 아래와 같다.
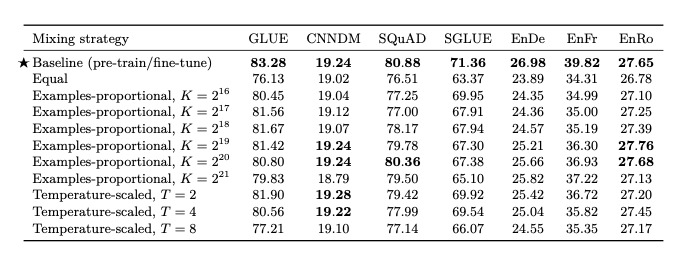
해당 결과, multi-task learning의 결과는 기존의 pre-training -> fine tuning보다 성능이 낮은 것을 알 수 있다.
Appendix: T에 대해서는 아래와 같이 언급하고 있습니다. 즉, T가 1에 가까워 질수록 Task의 비율이 비슷해 지고, 이에 따라 Performance가 향상된다는 것을 알 수 있습니다.
To implement temperature scaling with temperature T, we raise each task’s mixing rate rm to the power of 1⁄T and renormalize the rates so that they sum to 1. When T = 1, this approach is equivalent to examples-proportional mixing and as T increases the proportions become closer to equal mixing.
Multi-task learning + Fine Tuning
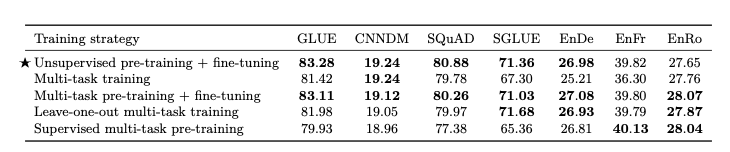
위의 Figure결과를 살펴보게 되면, Multi-task pre-training + fine-tuning의 방식으로 기존의 Unsupervised pre-training + fine-tuning보다 성능이 비슷하거나 좋은 것을 알 수 있다.
결국 Multi-task learning을 하더라도 finetuning을 해줄 때 더 성능이 좋은 것을 알 수 있다. 하지만, Multi-task learning을 하고 finetuning하는 것에 대하여 가능성을 확인할 수 있고, 이에 대하여 학습을 진행하고 성능을 평가하였다.
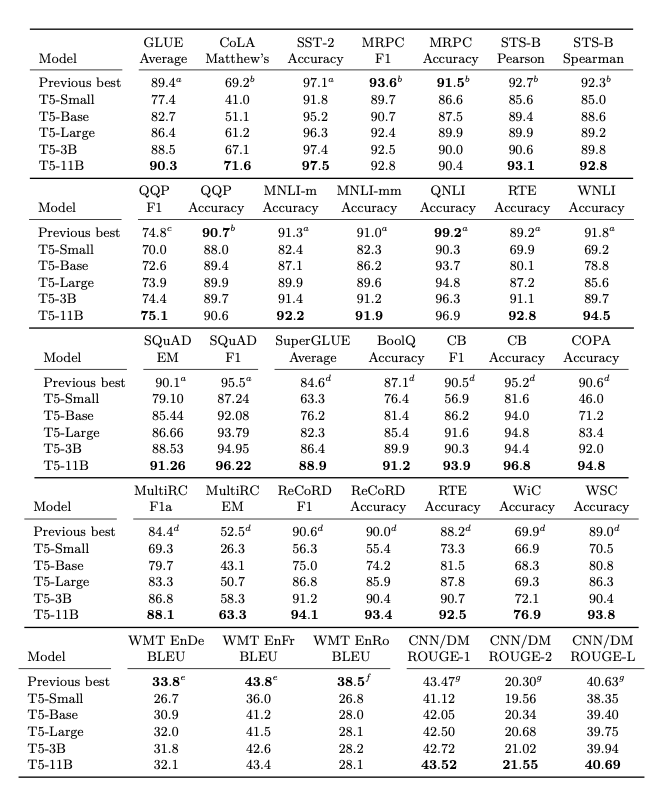
Putting It All Together
최종적인 결과이다. 위에서 찾은 모든 방법들을 조합하여서 Model Task를 수행하였으며, 많은 Task에서 SOTA의 성능을 보이는 것을 확인하였다. (실제 논문에서는 위의 실험 뿐만 아니라, 더 많은 환경에서 실험을 수행하였으며, 최종적인 선택은 논문을 참조하여야 한다.)
Leave a comment