
A PREVIEW OF XIYAN-SQL: A MULTI-GENERATOR ENSEMBLE FRAMEWORK FOR TEXT-TO-SQL
A PREVIEW OF XIYAN-SQL: A MULTI-GENERATOR ENSEMBLE FRAMEWORK FOR TEXT-TO-SQL
Abstract
To tackle the challenges of large language model performance in natural language to SQL tasks, we introduce XiYan-SQL, an innovative framework that employs a multi-generator ensemble strategy to improve candidate generation.
We introduce M-Schema, a semi-structured schema representation method designed to enhance the understanding of database structures. To enhance the quality and diversity of generated candidate SQL queries, XiYan-SQL integrates the significant potential of in-context learning (ICL) with the precise control of supervised fine-tuning.
On one hand, we propose a series of training strategies to fine-tune models to generate high-quality candidates with diverse preferences.
On the other hand, we implement the ICL approach with an example selection method based on named entity recognition to prevent overemphasis on entities. The refiner optimizes each candidate by correcting logical or syntactical errors.
To address the challenge of identifying the best candidate, we fine-tune a selection model to distinguish nuances of candidate SQL queries.
The experimental results on multiple dialect datasets demonstrate the robustness of XiYan-SQL in addressing challenges across different scenarios.
Overall, our proposed XiYan-SQL achieves the state-of-the-art execution accuracy of 75.63% on Bird benchmark, 89.65% on the Spider test set, 69.86% on SQL-Eval, 41.20% on NL2GQL.
The proposed framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods.
해당 논문에서, 제안하는 중요한 부분은 4가지 이다.
- Data Base의 구조를 이해할 수 있는 M-Schema를 제안한다.
- 정확한 Query생성을 위하여 (Text, Query)쌍으로 Supervised Learning을 진행한다.
- Logical 혹은 Syntactical Error가 있는지 Refiner로 찾는다.
- Overfitting을 방지하기 위하여, 최종적으로 여러 Queries를 통하여 최종적인 Query를 선택한다.
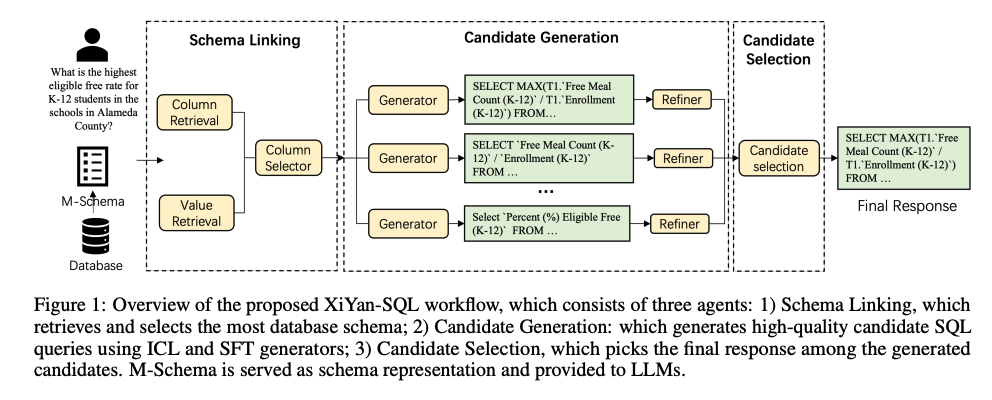
Introduction
해당 주제가 왜 중요한지에 대하여, 저자와 동일한 생각을 가지고 있다.
- 비전문가와 전문가 모두가 광범위한 DB에서 귀중한 인사이트를 추출하는 데 큰 도움이 된다.
- Text2SQL에는 주고 크게 2가지 방법이 있지만, 각각의 방법은 Limitation이 분명하다. -> 해당 저자는 2가지 방법을 모두 사용하는 방법을 제안한다.
- Supervised Fine-Tuning (SFT)
- Parameter가 작은 Model로서 Tuning하는 방법으로서 정확하고 통제된 SQL쿼리 생성이 가능하다.
- 복잡한 논리 추론이 어렵고, Genralization하기 힘들다
- 아래와 같이 2단계로 학습하여, Query Generation으로서 활용 가능
- 기초 능력 활성화: 정확한 (Text, Query)로서 학습하여, Text입력시에 정확한 Query 생성
- Diversity 강조: 다양한 표현 방식의 SQL 생성하여 Candidate Generation의 역량 강화
- Prompt Engineering
- Zero-shot, Few-shot과 같이 쉽게 사용 가능하고, Generalization 능력이 뛰어나다.
- 단, 연산량이 크고, 정확하게 원하는 SQL쿼리 생성은 불가능 하다.
- Supervised Fine-Tuning (SFT)
M-Schema
M-Schema는 LLM이 Table의 Schema를 잘 이해하여, 정확한 Query를 생성하는데 도움을 준다.
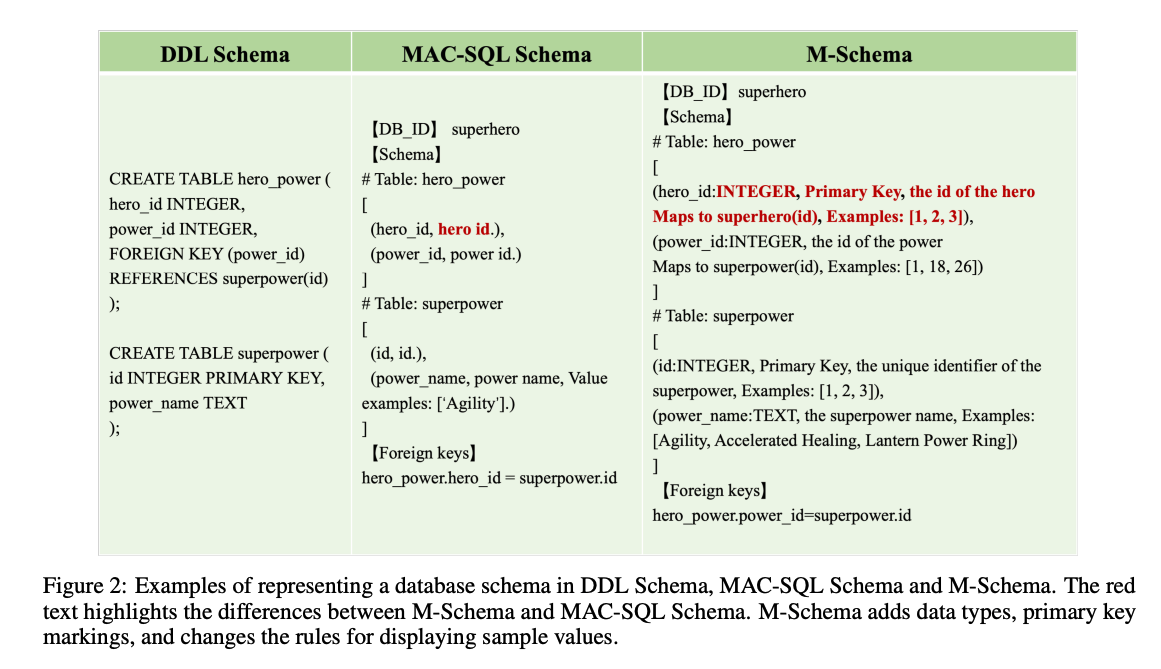
해당 Schema는 아래와 같은 특징을 가지고 있다.
- 계층적 구조 표현: 데이터베이스 → 테이블 → 컬럼 간 관계를 명확하게 표현
- 구조화된 토큰 사용
- 【DB_ID】: 데이터베이스 식별
- # Table: 테이블 시작
- 【Foreign Keys】: 외래키 정보 구간
- 컬럼 정보: 컬럼명, 데이터 타입, 컬럼 설명, Primary Key 여부, 예시 값 등 포함
- Foreign Key 명시적 표시: 테이블 간 관계 이해를 위해 필수
기존의 Few-Shot으로 넣는것에 비하여 구조적이며, 명확한 정보를 전달할 수 있는 방식이다.
Appendix. M-Schema Architecture
저자들은 실제 DB에 접속하여 M-Schema의 값을 가져 온다. 즉, Table의 변경이나, 추가에도 대응할 수 있지만, 아래와 같이 복잡한 과정을 거치게 된다.
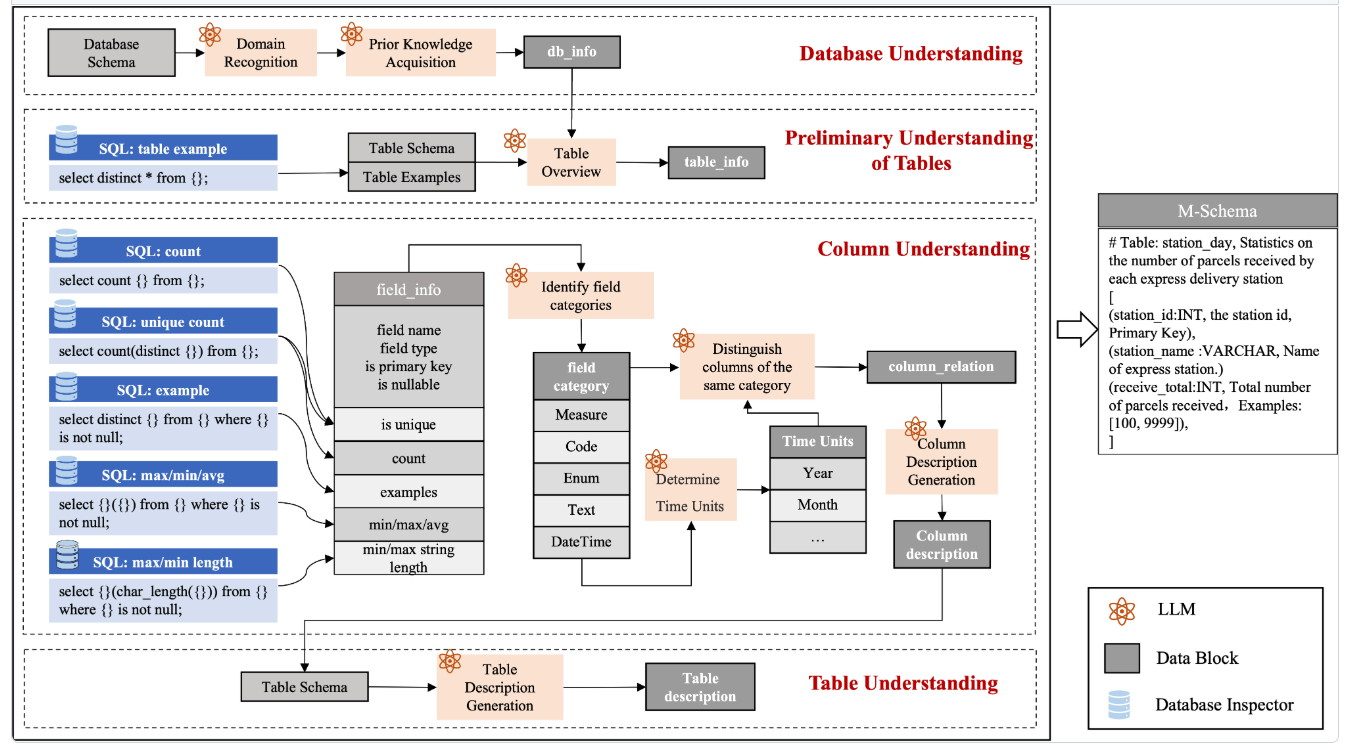
Schema Linking
현재 부터 아래의 모든 단계는 구체적으로 제공되지 않습니다. 다만, 어떻게 학습하였고, 어떻게 구성하였는지에 대해서 적어두었습니다.
Retrieval Module
- 질문에서 키워드와 엔티티를 추출 (few-shot prompting 사용)
- 키워드와 컬럼 설명 간 의미 유사도를 계산하여 관련 컬럼(top-k)을 검색
- 값 검색(value retriever) 은 LSH + 의미 유사도 기반의 2단계 검색 전략 사용
- 최종적으로 컬럼 검색 결과 + 값 검색 결과의 합집합이 candidate schema로 사용됨
Column Selector
- 위에서 추출한 스키마를 M-Schema 포맷으로 구성하여 LLM에 제공
- few-shot 프롬프트 방식으로 LLM이 질문과 관련 있는 컬럼만 선택하도록 유도
- 불필요한 테이블/컬럼은 제거하여 SQL 생성을 위한 최소 스키마 구성
p.s. Table 선택 w M-schema: 위의 설명을 보게 되면, 모든 Table에 대한 정보가 M-Schema에 포함되어 들어가는 것으로 파악할 수 있다. Table 갯수가 많아지게 되면 해당 Table Description <-> Question간의 Similarity를 통하여, 의미있는 Table을 선택할 수 있는 기능이 필요하다.
Candidate Generation
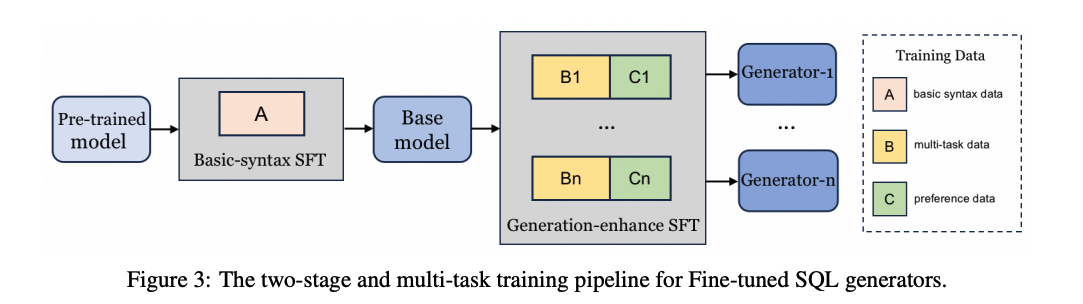
Candidate Generation은 크게 3가지의 Sub Step으로서 학습이 진행되었다. 각각의 Step에 대한 특징은 아래와 같다.
Fine-tuned SQL Generator
Goal: SQL Type에 상관없이, 일반적인 Query를 생성하는 것이 목표
- Basic-syntax training
- 다양한 SQL 기본 문법 패턴을 학습
- SQl Type에 관계없이 일반적인 SQL 문장 구조를 습득
- 적은 데이터셋으로 Fine-Tuning만 진행 (수만개 이상의 샘플 사용)
- Generation-enhance training
- 여러 Query와 여러 Task및 자연어를 다양하게 학습함으로서, 표현의 다양성 및 Generation 능력 획득
- 다양한 Candidate Generation을 위하여 Tuning 방법
- 1) 질문 -> Query 뿐만 아니라 Query -> 질문도 학습.
- 2) Query -> 에서 Evidence선택 학습. 즉, Query의 형태가 왜 그렇게 생성됬는지 파악하기 위하여 (여러 Candidate중에 정확한 Evidence 선택)
- 3) Query 수행 시, Error Message가 발생하게 되면, Error Message + 기존 Query -> 새로운 Query를 생성하도록 학습
- 4) 같은 의미이나, 다양한 표현을 가진 Text rephrase (e.g. “가장 많이 팔린 상품은?”, “최고 매출 제품은?”) -> 다양한 표현에서 추론하는 능력
- 5) SQL dialect (MySQL, PostgreSQL)에 따라 다르게 학습 or dialect 에 따른 다른 Query를 생성하도록 학습 -> 다양한 Query Style을 충족하기 위하여
- 해당 과정을 통하여, key값으로 넣어줘서 판별 vs. 개별적인 Model 생성 중 원하는 형태로 학습 필요
ICL (in-context learning) SQL Generator
위에서 Fine-tuned SQL Generator 외에 ICL로서 SQL Generator를 추가적으로 사용한다. 즉, n개의 query generator가 있다고 한다면, 1~m까지는 Fine-tuned SQL Generator, m~n까지는 ICL SQL Generator를 사용하게 된다. (논문에서는 2개, 1개로 각각 사용하였다.)
해당 논문에서 위와 같이 masked next token generation형태로 학습한 이유는 “Query자체의 의도를 파악하는 것 보다는, Entity (Column Name)등에 초점이 맞춰져서 학습되기 때문”이라고 한다. 해당과 같이 Entity에 Overfitting되는 것을 방지 하기 위하기 위하여 해당 방법을 적용한다. 해당 방법은 Training을 적용하는 것이 아니라, Few-Shot으로서 성능이 향상 될 만한, 예시를 적용하는 방법은 아래와 같다.
- Entity가 제거된 Question을 만든다. e.g. Query를 “America”, “China”등을 <country>로서 NLTK로 치환하여 ICL Learning을 진행하였다고 한다.
- 변형된 질문으로 유사한 예시를 선택한다. vector embedding을 통하여 test set에서 유사한 few shot을 train set에서 Top K개를 선택하게 된다.
- 여러 Table을 활용하는 SQL의 경우에는 Train Set에서 여러 Table을 다루는 SQL에서 선택한다.: 단일 Table을 활용하는 예제를 Few-Shot으로 넣었을 떄는, 효과가 없다고 한다.
p.s. Similarity Train Set을 뽑도록 학습한 Embedding Model은 아직 공개되지 않았다.
SQL Refiner
생성된 Query는 logical or syntactical 에러가 발생한다. 실제 실행 가능한 Query로 변경하기 위해서는 1) 실제 M-Schema의 Schema, 2) SQL 실행 결과, 3) 실제 수행 결과, 4) Error 발생 시 Error Message등을 Input으로 넣어서 실제 Query를 변경하고 수정할 수 있다.
위의 1~4는 특정 횟수 반복하여 Error가 없을 때까지 수행 혹은 해당 Query 사용 X등의 Architecture를 구성할 수 있다.

Candidate Selection
여러 Candidate가 생성될 떄, 가장 많이 적용하는 방법이 “self-consistency”기법으로서, 많이 나온 Query를 선택하는 Voting방식이다. 하지만, 이러한 방법은 아래와 같은 단점이 발생하게 된다.
- 후보 중 모두가 일관되지 않는 경우에는 동작되지 않음
- 가장 일관된 쿼리라고 해도 반드시 정답이라는 보장이 없음
따라서, 해당 논문의 저자들은 따로 Candidate Selection Model을 만들었다. 해당 Model은 아래와 같은 방식으로 동작하게 된다.
- SQL 실행 결과의 일관성을 기준으로 Group을 생성하게 된다. 즉, 실제 결과 몇개를 확인하여 동일한 Query끼리 Group을 정하게 된다.
- 각 Group내에서 inconsistent sample을 제거하여, candidate query를 만든다고 되어있다.
결과가 같아도, inconsistent sample을 진행하는 이유는 아래와 같이 결과가 모두 null이여도, query상에서 의미가 다를 수 있기 때문이다.
1
2
3
4
5
-- 후보 A
SELECT name FROM students WHERE age > 18
-- 후보 B
SELECT name FROM students WHERE age > 30 OR grade = 'A'
Experiment
실제, 4개의 Dataset에서 다른 여러 LLM Model보다 성능이 좋은 것을 확인하였다.
Ablation Test
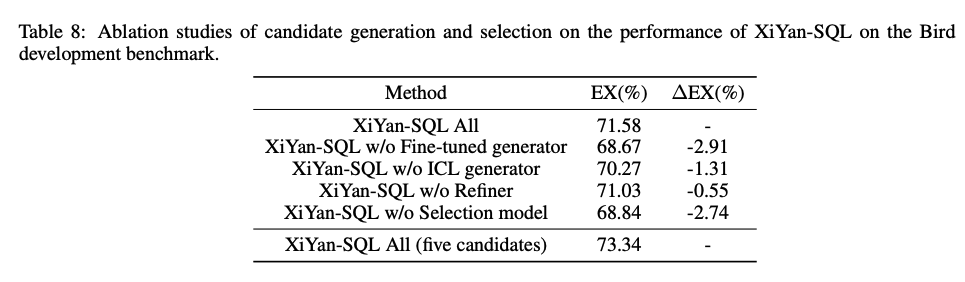
위에서 제히사는 방법들을 하나씩 제거하면서, Ablation Test를 진행하여 효과를 증명하였다. 효과가 큰 순서로 진행하면 다음과 같다.
- Fine-tuned generator (Only ICP generator)
- Selection model (Using self-consistency)
- ICL generator (Only Fine-tuned generator)
- Refiner
또한, Candidate를 증가 했을 때, 성능이 향상된 것을 알 수 있다.
- Base (3 candidates)
- Fine-tuned generator: 2
- ICL generator: 1
- 5 candidates (세부적인 갯수 X)
Appendix. Date Parser
실제 구현한 Code를 확인하게 되면, Date Parser를 따로 만들어서 사용 중 인것 같다. (Model의 API는 구현되어있지만, 실제 넣어서 학습했는지 혹은 LangGraph로서 해당 과정을 거친건지는 잘 파악이 되지 않습니다.)
해당 Model에서는 사용자의 질문에서 Date를 정확히 Parsing해오기 위하여 아래와 같은 단계를 거치게 된다.
1. PreTrained Model
해당 PreTrain Model은 Text에서 필요한 날짜를 받아올 수 있게 구현한 Model이다. 자체적으로 PreTrain해서 사용하고 있으면, 해당 결과는 아래와 같다.
입력: 금년도 판매량은 얼마입니까?
모델 출력:["올해"]
입력:지난주 금요일은 수요일보다 주문량이 얼마나 많습니까?
모델 출력:["지난주 금요일", "지난주 수요일"]
2. DataConvertor
해당 Model에서는 아래와 같이 일반적으로 많이 사용하는 단어를 -> 날짜로서 Mapping하여 사용할 수 있게 구현하였다. (정규식으로 모든 Dictionary 구성)
1
2
3
4
5
class DateTimeUtil:
SPECIFIC_YEAR_MONTH_DAY_PATTERN = re.compile(r'\d{4}年\d{2}月\d{2}日')
GENERAL_YEAR_MONTH_DAY_PATTERN = re.compile(r'(今年|去年|前年|明年|后年)(\d{2}月\d{2}日)')
GENERAL_MONTH_DAY_PATTERN = re.compile(r'(本月|上月|上上月|下月)(\d{2}日)')
GENERAL_DAY_PATTERN = re.compile(r'(今天|昨天|前天|明天|后天|上月今天|上上月今天)')
Leave a comment