
Theory1. Motivations and Basics
1. Motivations and Basics
\(\newcommand{\argmax}{\mathop{\mathrm{argmax}}\limits}\) Machine Learning의 기초적인 이론부분을 다시 제대로 잡고 싶어서 문일철 교수님의 인공지능 및 기계학습 개론을 정리한 Post입니다.
- 1.1 MLE
- 1.2 MAP
- 1.3 Probability and Distribution
1.1 MLE
Thumbtack Question
압정을 던졌을 경우 앞면의 나올 확률은?
만약 5번을 던졌을 경우 다음과 같이 결과가 나왔다고 가정하자.
- 앞면: 3번
- 뒷면: 2번
각각의 앞정을 던질 확률은 iid(독립)이라고 가정하자.
그러면 이러한 확률분포는 Discrete Distribution이며, 경우의 수는 2개인 Binomial Distribution형태일 것 이다.
즉, 앞면이 나올 확률이 $P(H) = \theta$로서 가정하면 뒷면이 나올 확률은 자연적으로 $P(T) = 1- \theta$가 되는 것 이다.
위와 같은 확률 분포가 만약 Data의 분포형태로 나타내고 싶으면 다음과 같이 나타낼 수 있다.
$$P(D|\theta) = \theta^{\alpha_H}(1-\theta)^{\alpha_T}$$
$$\alpha_H: \text{Number of Head}$$
$$\alpha_T: \text{Number of Tail}$$
그렇다면 어떻게 식을 세워야 최적의 \(\theta\)를 구할 수 있을까?
이러한 의문에서 사용하는 방법이 MLE(Maximum Likelihood Estimation) 즉, Likelihood를 최대화 하는 값을 추정 방법이다. 식으로서 표현하면 아래와 같다.
$$\hat{\theta} = \argmax_{\theta}P(D|\theta)$$
위의 식을 설명하면, \(\theta\)값을 조절하여 \(P(D|\theta)\)값을 최대화 하는 \(\hat{\theta}\)를 찾겠다는 의미이며, 여기서 \(P(D|\theta)\)이 Likelihood라고 불리기 때문에 이러한 방법이 MLE(Maximun Likelihood Estimation)이 되는 것 이다.
위에서 우리는 \(P(D|\theta)\)가 Binomial Distribution으로 설정하였으므로 식을 다음과 같이 변형할 수 있다.
$$\argmax_{\theta}P(D|\theta) = \argmax_{\theta}\theta^{\alpha_H}(1-\theta)^{\alpha_T}$$
위의 식을 좀 더 편하게 치환하기 위하여 Monotonic Function(단조함수)인 Log변환을 적용한다.
$$\argmax_{\theta}\theta^{\alpha_H}(1-\theta)^{\alpha_T} = \argmax_{\theta}ln(\theta^{\alpha_H}(1-\theta)^{\alpha_T})$$
$$= \argmax_{\theta} \alpha_H ln(\theta) + \alpha_T ln(1-\theta)$$
위의 식에서 \(\alpha_H, \alpha_T\)는 시도 횟수이므로 양수이다. 또한, \(\theta\) 는 확률이므로 0~1사이의 값을 가지므로 Concave한 Function인 것을 확인할 수 있다.
따라서 Concave Function에서 argmax를 구하기 위하여 미분한 값이 0인 Point를 찾는 문제로 변하게 된다.
$$\frac{d}{d\theta}(\alpha_H ln(\theta) + \alpha_T ln(1-\theta)) = 0$$
$$\theta = \frac{\alpha_H}{\alpha_H+\alpha_T}$$
$$\therefore \hat{\theta} = \frac{\alpha_H}{\alpha_H+\alpha_T}$$
위와 같은 상황은 실제 상황에서 Noise가 존재하지 않는 Clear하고 Nice한 상황이다.
실제 Noise까지(\(\zeta\))까지 고려하여 Hoeffding’s inequality로서 표현하면 다음과 같다.
$$P(|\hat{\theta} - \theta^{*}| \ge \zeta) \le 2e^{-2N \zeta^2}$$
$$\theta^{*}: \text{Random variables that perfectly predict the actual noise}$$
위의 식을 해석하면 다음과 같다.
- $\zeta$(Error Bound)를 많이 허용할 수록 실제 확률과 가까워 진다.
- N이 높을 수록 실제 확률과 가까워 진다.(즉, 시도를 많이 할수록 더 정확한 확률을 구할 수 있다.)
1.2 MAP
MAP(Maximum a Posteriori Estimation)이란 MLE 방법에서 이미 사전에 알고있는 지식을 추가로 적용하고 싶을 때 사용하는 방법이다.
$$P(\theta|D) = \frac{P(D|\theta)P(\theta)}{P(D)}$$
$$Posterior = \frac{Likelihood*PriorKnowledge}{Normalizing Constant}$$
위의 식에서 P(D)는 Constant한 상수라고 생각하면 기존의 MLE에서 사용하였던 Likelihood에 사전정보를 곱한 식이라고 생각할 수 있다.
따라서 최종적인 식은 다음과 같이 나타낼 수 있다.
$$P(\theta|D) \varpropto P(D|\theta)P(\theta)$$
위의 식에서 위의 식에서 MLE에서 Likelihood는 \(P(D|\theta) = \theta^{\alpha_H}(1-\theta)^{\alpha_T}\)로서 표현하였다.
이제 그러면 \(P(\theta)\)만 잘 표현하면 Argmax의 값을 구할 수 있을 것 이다.
우리는 이러한 확률분포를 Beta Distribution으로서 표현할 수 있다. 식으로서 표현하면 다음과 같다.
$$\text{PDF = } \frac{x^{\alpha-1}(1-x)^{\beta-1}}{B(\alpha,\beta)}$$
$$B(\alpha,\beta) = \frac{\gamma(\alpha)\gamma(\beta)}{\gamma(\alpha+\beta)}$$
\(\gamma()\): Gamma Function이다.
위의 Beta Distribution의 특징은 CDF가 0~1의 값을 가진다는 것 이다.
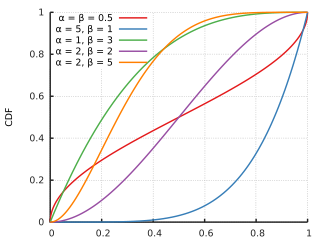
사진 출처:WIKI
따라서 Beta Distribution은 확률을 표현하는 Distribution이 될 수 있고 적용하여 계산하면 최종적인 식은 다음과 같이 될 수 있다.
$$P(\theta|D) \varpropto \theta^{\alpha_H+\alpha-1}(1-\theta)^{\alpha_T +\beta-1}$$
MLE와 마찬가지로 \(\hat{\theta}\)를 구하고자 하면 다음과 같다.
$$\hat{\theta} = \argmax_{\theta} P(\theta|D) = \frac{\alpha_H + \alpha -1}{\alpha_H + \alpha + \alpha_T + \beta -2}$$
위의 수식 전개는 위의 MLE와 같으므로 생략한다.
최종적으로 MLE와 MAP를 비교하게 되면 사전 정보를 사용하고 싶으면 MAP로서 변환이 가능하다는 것 이다.
1.3 Probability and Distribution
많이 사용되는 Probability와 Distribution에 대하여 설명하는 부분이다.
짧은 강의시간안에 깊은 내용까지 다루시기에는 시간이 많이 부족하여 보였다.
따라서 개인적으로 공부한 Statistics에서 기본적인 통계지식을 읽힌 뒤 다음 강의를 진행하는 것을 추천한다.
Leave a comment