
OpenCV-ObjectTracking
참고사항
현재 Post에서 사용하는 Data를 만드는 법이나 사용한 Image는 github에 올려두었습니다.
ObjectTracking
ObjectTracking이란 비디오 영상에서 특정 대상의 위치 변화를 추적하는 것 이다.
비디어는 일련의 영상 프레임으로 구성되고 인접한 영상 프레임들 사이에서는 시공간적 유사성(영상내 대상의 위치, 크기, 형태 등이 유사)이 존재하기 때문에 Tracking에서는 특정대상을 추적하기 위해서 이러한 history를 사용하여 추적한다.
위와 같은 ObjectTracking을 활용하여 고정된 Camera에서 Input으로 들어오는 Frame을 처리하여 자동차를 인식하고 가져오는 Code를 작성하여 보자
원본 동영상: A3 A-road Traffic UK HD - rush hour - British Highway traffic May 2017
참조한 Code: seraj94ai GitHub
필요한 라이브러리 임포트
1
2
3
4
5
6
import cv2
import numpy as np
import matplotlib.pyplot as plt
import ipywidgets as widgets
import IPython.display as display
from ipywidgets import Layout, Button, Box, Layout, Image, IntSlider, AppLayout
Data 수집
Data수집을 위하여 YouTube에서 동영ㅇ상을 mp4로서 다운받는다.
아래 링크를 참조하면 좀 더 Data의 Crawling에 대해서 알 수 있다.
DataCrawling: Python-Pytube,Selenium
Pytube 설치
1
!pip install pytube
Method 정의
Youtube에서 Data수집을 mp4 형식으로 다운받는 코드이다.
Parameter로서 URL과 Dwonload Path를 받아서 Youtube에서 동영상을 내려받는데 사용한다.
1
2
3
4
5
6
7
8
9
from pytube import YouTube
def youtube_download(url,destination):
yt = YouTube(url)
parent_dir = destination
yt.streams.filter(subtype='mp4').first().download(parent_dir)
print('Download Success')
youtube_download('https://www.youtube.com/watch?v=UM0hX7nomi8','./data')
Method 정의 결과
Download Success
데이터 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
cap = cv2.VideoCapture('./data/A3 A-road Traffic UK HD - rush hour - British Highway traffic May 2017.mp4')
if(not cap.isOpened()):
print('Error opening video')
height,width = (int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)),int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)))
wImg1 = widgets.Image(layout = widgets.Layout(border="solid"), width="50%")
display.display(wImg1)
while True:
try:
retval, frame = cap.read()
if not retval:
break
wImg1.value = cv2.imencode(".jpeg", frame)[1].tostring()
except KeyboardInterrupt:
break
if cap.isOpened():
cap.release()
데이터 확인 결과
BackgroundSubtractor로 배경과 전경 분할
아래 Code는 BackgroundSubtractorMOG2를 사용하여 Object를 추출하였다.
다음과 같은 사전지식이 필요로 하다.
- BackgroundSubtractor: OpenCV-비디오 처리
- 모폴리지 연산: OpenCV-영상 공간 필터링
Algorithm
cv2.createBackgroundSubtractorMOG2()를 통하여 BS Structure선언sub.apply()을 통하여 전경 Mask 획득- Closing, Opning, dilation, Threshold로 인하여 noise제거
- 윤곽선 검출
- 윤곽선 중 검출하고자하는 Object의 크기에 만족하는 Object Detect후 Box로 표시
- 각각의 Object의 무게중심(moment)에 Mark와 Text로서 표시
parameter
| 변수 | 설명 |
| sub | BS Structure(MOG2) |
| fps | 동영상 fps |
| fgmask | 전경 Mask(Background 제거) |
| bins | Noise제거 후 Image |
| contours | 윤곽선 검출후 Points |
| M | 크기를 만족하는 Object의 무게중심 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
wImg1 = widgets.Image(layout = widgets.Layout(border="solid"), width="40%")
wImg2 = widgets.Image(layout = widgets.Layout(border="solid"), width="40%")
wImg3 = widgets.Image(layout = widgets.Layout(border="solid"), width="40%")
wImg4 = widgets.Image(layout = widgets.Layout(border="solid"), width="40%")
items = [wImg1, wImg2]
box1 = Box(children=items)
items = [wImg3, wImg4]
box2 = Box(children=items)
display.display(box1,box2)
cap = cv2.VideoCapture("./data/A3 A-road Traffic UK HD - rush hour - British Highway traffic May 2017.mp4")
sub = cv2.createBackgroundSubtractorMOG2(detectShadows=False) # create background subtractor
while True:
ret, frame = cap.read()
if not ret:
print("Check Your Path or Data")
break
if ret:
try:
#BS를 통한 foreground mask 생성
fps = cap.get(cv2.CAP_PROP_FPS)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
fgmask = sub.apply(gray)
#Noise 제거
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
closing = cv2.morphologyEx(fgmask, cv2.MORPH_CLOSE, kernel)
opening = cv2.morphologyEx(closing, cv2.MORPH_OPEN, kernel)
dilation = cv2.dilate(opening, kernel)
retvalbin, bins = cv2.threshold(dilation, 220, 255, cv2.THRESH_BINARY)
#gray = cv2.bitwise_and(gray,bins)
wImg1.value = cv2.imencode(".jpeg", frame)[1].tostring()
wImg2.value = cv2.imencode(".jpeg", fgmask)[1].tostring()
wImg3.value = cv2.imencode(".jpeg", bins)[1].tostring()
#윤곽선 검출
im2, contours, hierarchy = cv2.findContours(bins, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#Detect할 Object의 최소 크기와 최대 크기
minarea = 400
maxarea = 50000
#각각의 Object의 좌표 담을 변수 선언
cxx = np.zeros(len(contours))
cyy = np.zeros(len(contours))
car_count = 0
for i in range(len(contours)):
if hierarchy[0, i, 3] == -1:
#검출한 윤곽선의 면적 계산
area = cv2.contourArea(contours[i])
# 검출한 윤곽선의 면적이 찾고자하는 Object의 크기에 적합한지 비교
if minarea < area < maxarea:
#적합하다면 각각의 무게중심을 구한다.
cnt = contours[i]
M = cv2.moments(cnt)
cx = int(M['m10'] / M['m00'])
cy = int(M['m01'] / M['m00'])
#윤곽선을 감싸는 Box 좌표 반환
x, y, w, h = cv2.boundingRect(cnt)
#검출한 Object를 Object로서 판단하여 표시
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
#각각의 Object의 무게중심 표시
cv2.putText(frame, str(cx) + "," + str(cy), (cx + 10, cy + 10), cv2.FONT_HERSHEY_SIMPLEX,.3, (0, 0, 255), 1)
#Marker로서 무게중심 표시
cv2.drawMarker(frame, (cx, cy), (0, 255, 255), cv2.MARKER_CROSS, markerSize=8, thickness=3,line_type=cv2.LINE_8)
#화면에 표시된 차량 개수 파악
car_count+=1
#최종적인 결과 표시
cv2.putText(frame, 'FPS: '+str(int(fps))+' Car Count: '+str(car_count), (0,30), cv2.FONT_HERSHEY_SIMPLEX,1.3, (255, 255, 255), 2)
wImg4.value = cv2.imencode(".jpeg", frame)[1].tostring()
except KeyboardInterrupt:
break
if cap.isOpened():
cap.release()
BackgroundSubtractor로 배경과 전경 분할 결과
위의 Code를 살펴보게 되면 큰 문제점이 발견된다.
움직이는 모든 Object에 대해서 크기만 만족하면 Vehicle이라고 판단하는 것 이다.
따라서 4. 윤곽선 검출 -> 5. 윤곽선 중 검출하고자하는 Object의 크기에 만족하는 Object Detect후 Box로 표시 과정 사이에 Vehicle인지 아닌지 판단하는 단계가 필요하다.
Cascade Classifier사용
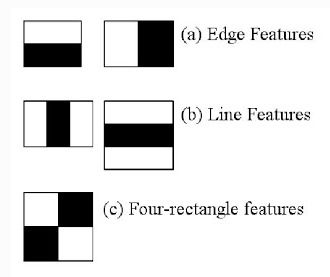
사진 출처:참스터디 iAIDOL 블로그
Haar feature란 Train Data에서 하얀색 사각형에서의 픽셀값의 합을 검정색 사각형 영역의 필셀값의 합에서 뺀 값이다.
이러한 특징을 몇개로 할 것인가 혹은 어떻게 값을 줄 것인가에 대한것은 사람이 직접 정할 수 없는 수많은 Hyperparameter로서 정의될 것이다.
이러한 Trainning의 과정은 OpenCV정식 HomePage에서 자세히 나와있다.
출처: OpenCV 정식 홈페이지
아래에서 사용하는 차량을 판별하기 위한 CascadeClassfier는 Internet상에서 가져와서 사용하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
wImg1 = widgets.Image(layout = widgets.Layout(border="solid"), width="50%")
display.display(wImg1)
#create VideoCapture object and read from video file
cap = cv2.VideoCapture('./data/A3 A-road Traffic UK HD - rush hour - British Highway traffic May 2017.mp4')
#use trained cars XML classifiers
car_cascade = cv2.CascadeClassifier('./data/cars.xml')
#read until video is completed
while True:
try:
#capture frame by frame
ret, frame = cap.read()
#convert video into gray scale of each frames
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#detect cars in the video
cars = car_cascade.detectMultiScale(gray, 1.1, 3)
#to draw arectangle in each cars
for (x,y,w,h) in cars:
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
#display the resulting frame
wImg1.value = cv2.imencode(".jpeg", frame)[1].tostring()
#press Q on keyboard to exit
except KeyboardInterrupt:
break
if cap.isOpened():
cap.release()
Cascade Classifier사용 결과
위의 결과도 만족스럽지 못한 결과를 가져온다.
- 차량을 인식하는 정확도에 있어서 BackgroundSubtractor로 배경과 전경 분할보다 낮은 인식률을 보여준다. 물론 BS를 활용한 방법은 Camera가 도로에 있다고 가정하고 움직이는 물체를 Detect하므로 더 정확도가 높을 수 밖에 없다.
- Frame에 Delay가 상당하다 즉, Image Processing의 Resource가 많이 차지하는 것을 알 수 있다.
두 가지의 과정을 합쳐서 정확한 Vehicle판독을 하려했으나, Out of Memory 즉 연산처리과정에서 너무많은 Resource를 차지하여 매우 느리고 무거운 Coding이 되어서 Deeplearning을 통하여 해결하는 방법을 알아보자.
참조:원본코드
참조:Python으로 배우는 OpenCV 프로그래밍
문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment