
Paper34. IntTower: the Next Generation of Two-Tower Model for Pre-Ranking System-Code
Setting
Import Library
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import numpy as np
import pandas as pd
import torch
import torchvision
import random
from torch.utils.tensorboard import SummaryWriter
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from preprocessing.inputs import SparseFeat, DenseFeat, VarLenSparseFeat
from model.IntTower import IntTower
from deepctr_torch.callbacks import EarlyStopping, ModelCheckpoint
Seed
1
2
3
4
5
6
7
8
9
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
seed = 1023
setup_seed(seed)
Configure
1
2
3
4
5
6
7
device = 'cpu'
embedding_dim = 32
epoch = 10
batch_size = 2048
lr = 0.001
dropout = 0.3
Dataset
Load Dataset & Split Train, Test Dataset
기존의 다르게 특이한 점은 중간 점수인 rating=3은 제외하였다는 것 이다
Label 기준
- 1~2: 0
- 4~5: 1
1
2
3
4
5
6
7
data_path = './data/movielens.txt'
data = pd.read_csv(data_path)
data = data.drop(data[data['rating'] == 3].index)
data['rating'] = data['rating'].apply(lambda x: 1 if x > 3 else 0)
data = data.sort_values(by='timestamp', ascending=True)
train,test = train_test_split(data,test_size= 0.2 )
Additional Feature
get_user_feature
User가 movie별로 매긴 평균 rating을 user_mean_rating으로서 저장한다. -> rating의 기준은 0,1로 지정한 것 이다.
get_item_feature ㅡㅡㅡ Movie가 User별로 매긴 평균 rating을 item_mean_rating으로서 저장한다. -> rating의 기준은 0,1로 지정한 것 이다.
Appendix: user_hist의 경우에는 user가 movie중에서 rating=1로 지정한 movie_id의 모임이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def get_user_feature(data):
data_group = data[data['rating'] == 1]
data_group = data_group[['user_id', 'movie_id']].groupby('user_id').agg(list).reset_index()
data_group['user_hist'] = data_group['movie_id'].apply(lambda x: '|'.join([str(i) for i in x]))
data = pd.merge(data_group.drop('movie_id', axis=1), data, on='user_id')
data_group = data[['user_id', 'rating']].groupby('user_id').agg('mean').reset_index()
data_group.rename(columns={'rating': 'user_mean_rating'}, inplace=True)
data = pd.merge(data_group, data, on='user_id')
return data
def get_item_feature(data):
data_group = data[['movie_id', 'rating']].groupby('movie_id').agg('mean').reset_index()
data_group.rename(columns={'rating': 'item_mean_rating'}, inplace=True)
data = pd.merge(data_group, data, on='movie_id')
return data
train = get_user_feature(train)
train = get_item_feature(train)
test = get_user_feature(test)
test = get_item_feature(test)
Define Feature
Dataset에 있는 Feature안에서 Dense Feature(Continuous Feature)와 Sparse Feature (Category Feature)를 지정한다.
1
2
3
4
5
6
sparse_features = ['user_id', 'movie_id', 'gender', 'age', 'occupation']
dense_features = ['user_mean_rating', 'item_mean_rating']
target = ['rating']
user_sparse_features, user_dense_features = ['user_id', 'gender', 'age', 'occupation'], ['user_mean_rating']
item_sparse_features, item_dense_features = ['movie_id', ], ['item_mean_rating']
Sparse Feature
Category Feature를 Mapping하는 과정이다. (ex) gender의 M, F를 0,1로 Mapping)
1
2
3
4
5
for feat in sparse_features:
lbe = LabelEncoder()
lbe.fit(data[feat])
train[feat] = lbe.transform(train[feat])
test[feat] = lbe.transform(test[feat])
Dense Feature
Continuous Feature의 경우에는 MinMax Scalar를 적용하여 사용한다.
Dense Feature의 경우에는 Train, Test의 각각의 Feature를 통하여 Min-Max를 적용하였다. -> 수정 필요
1
2
3
4
5
mms = MinMaxScaler(feature_range=(0, 1))
mms.fit(train[dense_features])
mms.fit(test[dense_features])
train[dense_features] = mms.transform(train[dense_features])
test[dense_features] = mms.transform(test[dense_features])
Sequence Feature#1
Sequence Feature를 전처리 하는 단계이다. Sequence Feature의 경우에는 크게 2가지로서 나누었다.
- genres: Movie Genres는 Category Value이나 여러 종류에 속할 수 있다. 이러한 경우에는 Sequence Feature로서 지정하였다.
- user_hist: User가 평가를 좋게한 movie_id를 Sequence로서 생각하고 Feature로서 사용하였다.
Algorithm
- Dict형태에 Key와 Value값을 Mapping한다. 주요한 점은 사용하려는 함수에서 0은 padding값을 의미하기 때문에 1부터 값을 시작한다.
- 각각의 Feature를 위에서 정의한 Dict로서 Mapping한다. -> Output은 List형태가 된다. ex) [1, 5]
- 최대 max_length를 구한다.
- max_length가 아닌 값은 뒤에 padding값인 0으로 값을 채운다. -> max_len:6 => [1, 5, 0, 0, 0, 0]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def get_var_feature(data, col):
key2index = {}
def split(x):
key_ans = x.split('|')
for key in key_ans:
if key not in key2index:
# Notice : input value 0 is a special "padding",\
# so we do not use 0 to encode valid feature for sequence input
key2index[key] = len(key2index) + 1
return list(map(lambda x: key2index[x], key_ans))
var_feature = list(map(split, data[col].values))
var_feature_length = np.array(list(map(len, var_feature)))
max_len = max(var_feature_length)
var_feature = pad_sequences(var_feature, maxlen=max_len, padding='post', )
return key2index, var_feature, max_len
genres_key2index, train_genres_list, genres_maxlen = get_var_feature(train, 'genres')
user_key2index, train_user_hist, user_maxlen = get_var_feature(train, 'user_hist')
1
genres_key2index
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{'Animation': 1,
"Children's": 2,
'Comedy': 3,
'Adventure': 4,
'Fantasy': 5,
'Romance': 6,
'Drama': 7,
'Action': 8,
'Crime': 9,
'Thriller': 10,
'Horror': 11,
'Sci-Fi': 12,
'Documentary': 13,
'War': 14,
'Musical': 15,
'Mystery': 16,
'Film-Noir': 17,
'Western': 18}
1
train_genres_list
1
2
3
4
5
6
7
array([[ 1, 2, 3, 0, 0, 0],
[ 1, 2, 3, 0, 0, 0],
[ 1, 2, 3, 0, 0, 0],
...,
[ 7, 10, 0, 0, 0, 0],
[ 7, 10, 0, 0, 0, 0],
[ 7, 10, 0, 0, 0, 0]], dtype=int32)
Define Feature - Sparse, Dense
SparseFeat
SparseFeature를 지정할 Class이다. 해당 방법처럼 구현한 이유는 namedtuple로서 정의하여, Feature에 대한 정보를 한번에 담아두는 것이 가능하다.
- dtype: int32
- dimension: embedding_dim을 입력으로 받는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from collections import OrderedDict, namedtuple, defaultdict
DEFAULT_GROUP_NAME = "default_group"
class SparseFeat(namedtuple('SparseFeat', ['name', 'vocabulary_size', 'embedding_dim', 'use_hash', 'dtype',
'embedding_name', 'group_name'])):
def __new__(cls, name, vocabulary_size, embedding_dim=4, use_hash=False, dtype='int32', embedding_name=None,
group_name=DEFAULT_GROUP_NAME):
if embedding_name is None:
embedding_name = name
if embedding_dim == 'auto':
embedding_dim = 6 * int(pow(vocabulary_size, 0.25))
if use_hash:
print("Notice! Feature Hashing on the fly currently!")
return super(SparseFeat, cls).__new__(cls, name, vocabulary_size, embedding_dim, use_hash, dtype,
embedding_name, group_name)
def __hash__(self):
return self.name.__hash__()
DenseFeat
DenseFeature를 지정할 Class이다. dtype=float, dimension=1
1
2
3
4
5
6
class DenseFeat(namedtuple('DenseFeat', ['name', 'dimension', 'dtype'])):
def __new__(cls, name, dimension=1, dtype="float32"):
return super(DenseFeat, cls).__new__(cls, name, dimension, dtype)
def __hash__(self):
return self.name.__hash__()
Category의 Dimension은 각각 32로 지정하였다.
1
2
3
4
5
6
7
user_feature_columns = [SparseFeat(feat, data[feat].nunique(), embedding_dim=embedding_dim)
for i, feat in enumerate(user_sparse_features)] + [DenseFeat(feat, 1, ) for feat in
user_dense_features]
item_feature_columns = [SparseFeat(feat, data[feat].nunique(), embedding_dim=embedding_dim)
for i, feat in enumerate(item_sparse_features)] + [DenseFeat(feat, 1, ) for feat in
item_dense_features]
1
user_feature_columns
1
2
3
4
5
[SparseFeat(name='user_id', vocabulary_size=6040, embedding_dim=32, use_hash=False, dtype='int32', embedding_name='user_id', group_name='default_group'),
SparseFeat(name='gender', vocabulary_size=2, embedding_dim=32, use_hash=False, dtype='int32', embedding_name='gender', group_name='default_group'),
SparseFeat(name='age', vocabulary_size=7, embedding_dim=32, use_hash=False, dtype='int32', embedding_name='age', group_name='default_group'),
SparseFeat(name='occupation', vocabulary_size=21, embedding_dim=32, use_hash=False, dtype='int32', embedding_name='occupation', group_name='default_group'),
DenseFeat(name='user_mean_rating', dimension=1, dtype='float32')]
1
item_feature_columns
1
2
[SparseFeat(name='movie_id', vocabulary_size=3668, embedding_dim=32, use_hash=False, dtype='int32', embedding_name='movie_id', group_name='default_group'),
DenseFeat(name='item_mean_rating', dimension=1, dtype='float32')]
Define Feature - Sequence
Sequence Feature를 정의한다. 주요한점은 maxlen과 combiner로서 어떻게 Pooling할지 정한다. (mean)
Appendix: @property
property는 흔히 많이 사용하는 get, set과 같이 작동할 수 있습니다. @property자체는 getter의 역할을 하며, setter의 경우에는 @function.setter로 지정합니다.
class Person:
def __init__(self):
self.__age = 0
@property
def age(self): # getter
return self.__age
@age.setter
def age(self, value): # setter
self.__age = value
james = Person()
james.age = 20 # 인스턴스.속성 형식으로 접근하여 값 저장
print(james.age) # 인스턴스.속성 형식으로 값을 가져옴
현재 아래 Class에서 property를 지정한 이유는 -> SparseFeat와 같이 사용하기 때문에, sparsefeat을 거치지 않고 바로 값을 가져오기 위하여 아래와 같이 코드를 작성하게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class VarLenSparseFeat(namedtuple('VarLenSparseFeat', ['sparsefeat', 'maxlen', 'combiner', 'length_name'])):
def __new__(cls, sparsefeat, maxlen, combiner='mean', length_name=None):
return super(VarLenSparseFeat, cls).__new__(cls, sparsefeat, maxlen, combiner, length_name)
@property
def name(self):
return self.sparsefeat.name
@property
def vocabulary_size(self):
return self.sparsefeat.vocabulary_size
@property
def embedding_dim(self):
return self.sparsefeat.embedding_dim
@property
def dtype(self):
return self.sparsefeat.dtype
@property
def use_hash(self):
return self.sparsefeat.use_hash
@property
def embedding_name(self):
return self.sparsefeat.embedding_name
@property
def group_name(self):
return self.sparsefeat.group_name
def __hash__(self):
return self.name.__hash__()
1
2
3
4
5
item_varlen_feature_columns = [VarLenSparseFeat(SparseFeat('genres', vocabulary_size=1000, embedding_dim=embedding_dim),
maxlen=genres_maxlen, combiner='mean', length_name=None)]
user_varlen_feature_columns = [VarLenSparseFeat(SparseFeat('user_hist', vocabulary_size=4000, embedding_dim=embedding_dim),
maxlen=user_maxlen, combiner='mean', length_name=None)]
Original
1
item_varlen_feature_columns[0].sparsefeat.embedding_dim
1
32
Using Property
1
item_varlen_feature_columns[0].embedding_dim
1
32
Define All Using Columns
1
2
# user_feature_columns += user_varlen_feature_columns
item_feature_columns += item_varlen_feature_columns
1
2
3
print('User Fields: {}'.format(len(user_feature_columns)))
for u_f in user_feature_columns:
print(u_f.name)
1
2
3
4
5
6
User Fields: 5
user_id
gender
age
occupation
user_mean_rating
1
2
3
print('Item Fields: {}'.format(len(item_feature_columns)))
for i_f in item_feature_columns:
print(i_f.name)
1
2
3
4
Item Fields: 3
movie_id
item_mean_rating
genres
Define Input
1
2
train_model_input = {name: train[name] for name in sparse_features + dense_features}
train_model_input["genres"] = train_genres_list
Model - IntTower
해당 Model은 왔다갔다 하면서, 복잡하게 구성되어 있다. 아래 Figure를 참조하여 하나씩 생각하여 확인해보자.
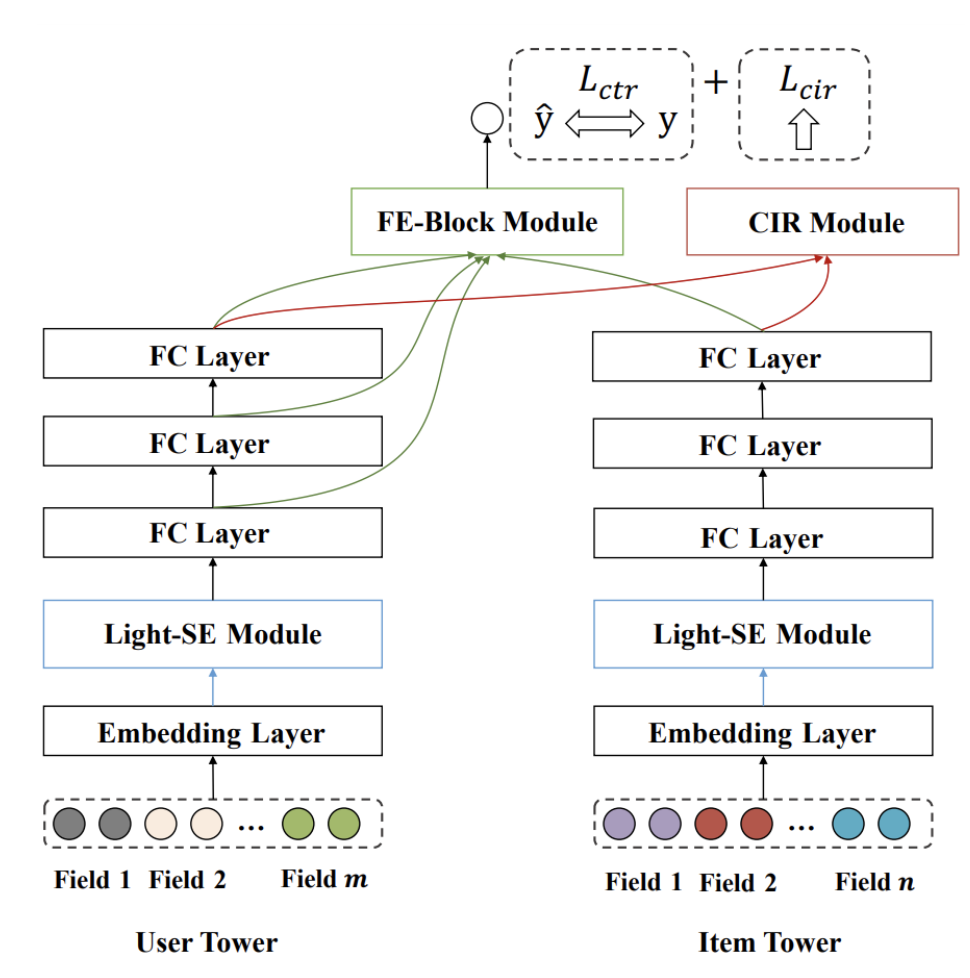
Embedding Layer
Embedding Layer: \(e=[e_1, e_2, \ldots, e_m]\): 각각의 Field를 Look-up operation을 통하여 Embedding하는 과정이다.
- \(e_i \in \mathbb{R}^d\): 위에서 우리는 d를 32 (embedding_dim)으로서 정하였다.
실제 Look-up operation은 nn.Embedding(feat.vocabulary_size, feat.embedding_dim if not linear else 1)로 지정하여 Vocabulary와 embedding_size를 지정하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
def create_embedding_matrix(feature_columns, init_std=0.0001, linear=False, sparse=False, device='cpu'):
'''
Example Input
- feature_columns:
[SparseFeat(name='movie_id', vocabulary_size=3668, embedding_dim=32, ...),
DenseFeat(name='item_mean_rating', dimension=1, ...),
VarLenSparseFeat(sparsefeat=SparseFeat(name='genres', vocabulary_size=1000, embedding_dim=32, ...)]
'''
'''
SparseFeat(name='movie_id', ...)
'''
sparse_feature_columns = list(
filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if len(feature_columns) else []
'''
VarLenSparseFeat(sparsefeat=SparseFeat(name='genres', ...)
'''
varlen_sparse_feature_columns = list(
filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if len(feature_columns) else []
'''
ModuleDict(
(movie_id): Embedding(3668, 32)
(genres): Embedding(1000, 32)
)
'''
embedding_dict = nn.ModuleDict({feat.embedding_name: nn.Embedding(feat.vocabulary_size,
feat.embedding_dim if not linear else 1)
for feat in sparse_feature_columns + varlen_sparse_feature_columns})
# Initialization
for tensor in embedding_dict.values():
nn.init.normal_(tensor.weight, mean=0, std=init_std)
return embedding_dict.to(device)
Example
1
2
3
4
5
6
7
8
import torch.nn as nn
user_dnn_feature_columns = user_feature_columns
item_dnn_feature_columns = item_feature_columns
init_std=0.0001
user_embedding_dict = create_embedding_matrix(user_dnn_feature_columns, init_std, sparse=False, device=device)
item_embedding_dict = create_embedding_matrix(item_dnn_feature_columns, init_std, sparse=False, device=device)
Embedding Layer - Forward
사용할 각 Feature의 Index를 지정합니다. -> 모든 Input의 Feature 기반 입니다. 각 Feature의 타입에 따라서 아래와 같이 나누어 집니다.
- SparseFeat:
- index: start ~ start+1
- ex) gender와 같이 실제 category value는 1차원 으로 들어오기 때문에 해당 end=start+1 입니다.
- DenseFeat:
- index: start ~ start+dimension
- ex) user_mean_rating와 같이 continuous value가 들어오게 됩니다. 현재는 Dimension=1로 모두 고정하였습니다.
- VarLenSparseFeat:
- index: start ~ start+maxlen
- ex) genre를 이전 preprocessing과정에서 padding을 추가하여 (pad_sequences 사용)하여 지정하였기 때문에 아래와 같이 지정
Make Dataset
Step1. Define Index
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def build_input_features(feature_columns):
features = OrderedDict()
start = 0
for feat in feature_columns:
feat_name = feat.name
if feat_name in features:
continue
if isinstance(feat, SparseFeat):
features[feat_name] = (start, start + 1)
start += 1
elif isinstance(feat, DenseFeat):
features[feat_name] = (start, start + feat.dimension)
start += feat.dimension
elif isinstance(feat, VarLenSparseFeat):
features[feat_name] = (start, start + feat.maxlen)
start += feat.maxlen
if feat.length_name is not None and feat.length_name not in features:
features[feat.length_name] = (start, start+1)
start += 1
else:
raise TypeError("Invalid feature column type,got", type(feat))
return features
1
2
feature_index = build_input_features(user_dnn_feature_columns + item_dnn_feature_columns)
feature_index
1
2
3
4
5
6
7
8
OrderedDict([('user_id', (0, 1)),
('gender', (1, 2)),
('age', (2, 3)),
('occupation', (3, 4)),
('user_mean_rating', (4, 5)),
('movie_id', (5, 6)),
('item_mean_rating', (6, 7)),
('genres', (7, 13))])
Step2. Pandas Dataset -> Torch DataLoader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
from preprocessing.utils import slice_arrays
import torch.utils.data as Data
from torch.utils.data import DataLoader
x = train_model_input
y = train[target].values
# Indexing
ex_random_index = random.sample(list(np.arange(train.shape[0])), 100)
x = [x[feature][ex_random_index] for feature in feature_index]
# Split Train & Validation
validation_split=0.2
do_validation = True
'''
hasattr: object의 속성(attribute)를 확인한다. 즉, 아래 코드는 x[0].shape 의 반환값이 있는지로 조건문이 실행된다.
input의 첫번째가 list일 수도있어서 아래와 같이 코드를 짰다.
'''
if hasattr(x[0], 'shape'):
split_at = int(x[0].shape[0] * (1. - validation_split))
else:
split_at = int(len(x[0]) * (1. - validation_split))
x, val_x = (slice_arrays(x, 0, split_at),
slice_arrays(x, split_at))
y, val_y = (slice_arrays(y, 0, split_at),
slice_arrays(y, split_at))
# Concat을 하기 위하여 Dimension을 늘린다. Sparse or Desnse Dataset의 경우 현재 Shape가 (80, )이기 때문에 (80,1)로 변환하기 위하여
for i in range(len(x)):
if len(x[i].shape) == 1:
x[i] = np.expand_dims(x[i], axis=1)
# Concat하여 TensorDataset으로 지정 한다.
train_tensor_data = Data.TensorDataset(torch.from_numpy(np.concatenate(x, axis=-1)), torch.from_numpy(y))
train_loader = DataLoader(dataset=train_tensor_data, shuffle=True, batch_size=16)
Embedding Layer
Step1.Sequence Pooling Layer
Sequence Dataset의 Value, Mask를 입력받아 Pooling하는 Layer 입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
class SequencePoolingLayer(nn.Module):
def __init__(self, mode='mean', support_masking=False, device='cpu'):
super(SequencePoolingLayer, self).__init__()
if mode not in ['sum', 'mean', 'max']:
raise ValueError('parameter mode should in [sum, mean, max]')
self.supports_masking = support_masking
self.mode = mode
self.device = device
self.eps = torch.FloatTensor([1e-8]).to(device)
self.to(device)
def _sequence_mask(self, lengths, maxlen=None, dtype=torch.bool):
# Returns a mask tensor representing the first N positions of each cell.
if maxlen is None:
maxlen = lengths.max()
row_vector = torch.arange(0, maxlen, 1).to(lengths.device)
matrix = torch.unsqueeze(lengths, dim=-1)
mask = row_vector < matrix
mask.type(dtype)
return mask
def forward(self, seq_value_len_list):
'''
Notation
- Batch Size: B
- Sequence Length: T
- Embedding Dimension: E
- seq_value_len_list[0]: Sequence Dataset을 Embedding한 Value 입니다.
- shape: B x T x E
- seq_value_len_list[0]: Pooling Layer를 사용하기 위하여 지정한 mask 입니다.
- shape: B x T
- Value: 0(Padding) or 1
'''
if self.supports_masking:
uiseq_embed_list, mask = seq_value_len_list
mask = mask.float()
# Pooling에 사용하기 위해 Sequence Length가 얼마인지 확인 합니다.
user_behavior_length = torch.sum(mask, 1, keepdim=True)
'''
embedding vector에 mask를 사용하기 위하여 dimension을 늘립니다.
- Input: B x T
- Output: B x T x 1
'''
mask = mask.unsqueeze(2)
else:
uiseq_embed_list, user_behavior_length = seq_value_len_list # [B, T, E], [B, 1]
mask = self._sequence_mask(user_behavior_length, maxlen=uiseq_embed_list.shape[1], dtype=torch.float32)
mask = torch.transpose(mask, 1, 2)
# 실제 Embedding Size 입니다.
embedding_size = uiseq_embed_list.shape[-1]
'''
mask를 Embedding Vector에 반복하기 위하여 횟수를 늘립니다.
- Input: B x T x 1
- Output: B x T x E
'''
mask = torch.repeat_interleave(mask, embedding_size, dim=2) # [B, maxlen, E]
if self.mode == 'max':
hist = uiseq_embed_list - (1 - mask) * 1e9
hist = torch.max(hist, dim=1, keepdim=True)[0]
return hist
# Embedding Vector에 Mask를 적용 합니다.
hist = uiseq_embed_list * mask.float()
'''
Sequence를 기준으로 Summation을 진행합니다.
- Input: B x T x E
- Output: B x E
'''
hist = torch.sum(hist, dim=1, keepdim=False)
# 실제 Average를 적용합니다. 위에서 실제 sequence값을 사용하여 average를 구합니다.
if self.mode == 'mean':
self.eps = self.eps.to(user_behavior_length.device)
hist = torch.div(hist, user_behavior_length.type(torch.float32) + self.eps)
'''
다른 Field의 Embedding Vector와 같이 사용하기 위하여 Dimension을 맞춥니다.
- Input: B x E
- Output: B x 1 x E
'''
hist = torch.unsqueeze(hist, dim=1)
return hist
Step2. Make Sequence Input Layer
실제 Sequence Dataset을 입력받아 Embedding하는 Layer 입니다.ㅇ
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
def get_varlen_pooling_list(embedding_dict, features, feature_index, varlen_sparse_feature_columns, device):
'''
- embedding_dict: Embedding Layer
ModuleDict(
(movie_id): Embedding(3668, 32)
(genres): Embedding(1000, 32))
- features: Input Data
- feature_index:
OrderedDict([('user_id', (0, 1)),
('gender', (1, 2)),
...])
- varlen_sparse_feature_columns: 어떻게 Embedding할지 모아놓은 Configure
[VarLenSparseFeat(sparsefeat=SparseFeat(name='genres', vocabulary_size=1000, embedding_dim=32,...)]
Notation
- Batch Size: B
- Sequence Legnth: T
- Embedding Size: E
'''
varlen_sparse_embedding_list = []
for feat in varlen_sparse_feature_columns:
'''
Input으로 들어오는 Sequence Dataset을 Embedding하는 과정입니다.
- Input: Batch Size x Sequence Legnth
- Output: Batch Size x Sequence Legnth x Embedding Diemension (32)
'''
seq_emb = embedding_dict[feat.embedding_name](
features[:, feature_index[feat.name][0]:feature_index[feat.name][1]].long())
if feat.length_name is None:
'''
Pooling Layer를 사용하기 위하여 mask를 설정합니다.
위의 Data Preprocessing 과정에서 저희는 Sequence Length를 맞추기 위하여 0의 값으로 padding을 추가하였습니다.
따라서 padding인지 혹은 실제 사용해야 하는 값인지 표시하는 단계 입니다.
- Input: B x T
- Output: B x T
- Value: False (padding) or True
'''
seq_mask = features[:, feature_index[feat.name][0]:feature_index[feat.name][1]].long() != 0
'''
Sequence Dataset의 Embedding을 구합니다.
- Input:
- seq_emb: B x T x E
- seq_mask: B x T
- Output: B x 1 x E
'''
emb = SequencePoolingLayer(mode=feat.combiner, support_masking=True, device=device)([seq_emb, seq_mask])
else:
seq_length = features[:, feature_index[feat.length_name][0]:feature_index[feat.length_name][1]].long()
emb = SequencePoolingLayer(mode=feat.combiner, support_masking=False, device=device)([seq_emb, seq_length])
varlen_sparse_embedding_list.append(emb)
return varlen_sparse_embedding_list
Step3. Forward with all values
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
def input_from_feature_columns(X, feature_columns, embedding_dict, support_dense=True):
'''
- feature_columns:
[SparseFeat(name='movie_id', vocabulary_size=3668, embedding_dim=32, ...),
DenseFeat(name='item_mean_rating', dimension=1, ...),
VarLenSparseFeat(sparsefeat=SparseFeat(name='genres', vocabulary_size=1000, embedding_dim=32, ...)]
- embedding_dict:
ModuleDict(
(movie_id): Embedding(3668, 32)
(genres): Embedding(1000, 32))
- X: Dataset
Notation
- B: Batch Size
- F: Features // ex) X = B x F
- E: Embedding Size
'''
'''
[SparseFeat(name='movie_id', vocabulary_size=3668, embedding_dim=32,...)]
'''
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), feature_columns)) if len(feature_columns) else []
'''
[DenseFeat(name='item_mean_rating', dimension=1, dtype='float32')]
'''
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if len(feature_columns) else []
'''
[VarLenSparseFeat(sparsefeat=SparseFeat(name='genres', vocabulary_size=1000, embedding_dim=32,...)]
'''
varlen_sparse_feature_columns = list(filter(lambda x: isinstance(x, VarLenSparseFeat), feature_columns)) if feature_columns else []
if not support_dense and len(dense_feature_columns) > 0:
raise ValueError("DenseFeat is not supported in dnn_feature_columns")
'''
Category Feature
아래 코드는 2단계 과정을 거친다.
Input: [B, F]
1. Indexing
sparse_embedding_list에 맞는 Feature만 Indexing한다.
Output: [B, 1]
2. Embedding
위에서 정의한 Embedding으로 Mapping 진행한다.
Output: [B, 1 ,E]
3. Make List
Output: List([B, 1, E])
'''
sparse_embedding_list = [embedding_dict[feat.embedding_name](
X[:, feature_index[feat.name][0]:feature_index[feat.name][1]].long()) for feat in sparse_feature_columns]
'''
Sequence Feature (위에서 설명)
Output: List([B, 1, E])
'''
varlen_sparse_embedding_list = get_varlen_pooling_list(embedding_dict, X, feature_index,
varlen_sparse_feature_columns, device)
'''
Continuous Feature
해당 Feature의 경우에는 그대로의 값 그대로 사용한다.
[Batch Size, Dimension]
'''
dense_value_list = [X[:, feature_index[feat.name][0]:feature_index[feat.name][1]] for feat in dense_feature_columns]
return sparse_embedding_list + varlen_sparse_embedding_list, dense_value_list
Result
1
2
3
for X,Y in train_loader:
user_sparse_embedding_list, user_dense_value_list = \
input_from_feature_columns(X, user_dnn_feature_columns, user_embedding_dict)
Light-SE Module
이전 과정에서는 각 Field를 동일한 Embedding Size로 맞추기 위한 과정을 거쳤다.
해당 Output을 활용하여 Light-SE Module을 어떻게 구현했는지 알아보자.
Make Input
1
2
3
4
5
'''
Input: List([B, 1, E]) // Length: Number of Fiels
Output: B, F(Field 갯수), E
'''
user_sparse_embedding = torch.cat(user_sparse_embedding_list, dim=1)
Light-SE Module
실제 Light-SE Module을 구현한 Code 이다.
논문에서 Light-SE는 크게 2단계로서 표현하였다.
Step 1. Squeeze
$$z_i = f_{sq}(e_i) = \frac{1}{d} \sum_{t=1}^d e_i^d$$
Step 2. Excitation and Reweight
$$k = f_{ex}(z) = \textit{softmax}(Wz + b)$$
위의 수식을 아래 코드에 적용하면 아래와 같다.
inputs: \(e=[e_1, e_2, ..., e_m]\)Z = torch.mean(inputs, dim=-1, out=None): \(z = [z_1, z_2, ..., z_m]\)- \(z_i = \frac{1}{d} \sum_{t=1}^d e_i^d\)
A = self.excitation(Z): \(Wz\)- Appendix: 논문 수식과 다르게 Bias를 사용하지 않았다.
A = self.softmax(A): \(k=\textit{softmax}(Wz)\)out = inputs * torch.unsqueeze(A, dim=2): \(\tilde{e} = [k_1 \cdot e_1, k_2 \cdot e_2, \ldots, k_m \cdot e_m]\)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
class LightSE(nn.Module):
"""LightSELayer used in IntTower.
Input shape
- A list of 3D tensor with shape: ``(batch_size,filed_size,embedding_size)``.
Output shape
- A list of 3D tensor with shape: ``(batch_size,filed_size,embedding_size)``.
Arguments
- **filed_size** : Positive integer, number of feature groups.
- **reduction_ratio** : Positive integer, dimensionality of the
attention network output space.
- **seed** : A Python integer to use as random seed.
References
"""
def __init__(self, field_size, seed=1024, device='cpu',embedding_size=32):
super(LightSE, self).__init__()
self.seed = seed
self.softmax = nn.Softmax(dim=1)
self.field_size = field_size
self.embedding_size = embedding_size
self.excitation = nn.Sequential(
nn.Linear(self.field_size , self.field_size, bias=False)
)
self.to(device)
def forward(self, inputs):
if len(inputs.shape) != 3:
raise ValueError(
"Unexpected inputs dimensions %d, expect to be 3 dimensions" % (len(inputs.shape)))
# Step 1. Squeeze
Z = torch.mean(inputs, dim=-1, out=None)
A = self.excitation(Z) #(batch,reduction_size)
A = self.softmax(A) #(batch,reduction_size)
# print(A.shape, inputs.shape)
out = inputs * torch.unsqueeze(A, dim=2)
return inputs + out
Result
1
2
3
user_filed_size=4
User_sim_non_local = LightSE(user_filed_size, seed, device)
User_sim_embedding = User_sim_non_local(user_sparse_embedding) # B x F x Embedding
FE Block
FC Layer와 FE-Block을 합친 Module이다.
Step 1. Calculate Input Dimension
최종적인 Model의 Input Dimension을 정하는 코드 이다.
코드는 간단하게 구현되어 있다.
- category, sequence feature는 결국 Embedding되어 Number of Fields X Embedding 이다.
- continuous feature는 dimension을 모두 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def compute_input_dim(feature_columns, include_sparse=True, include_dense=True, feature_group=False):
sparse_feature_columns = list(
filter(lambda x: isinstance(x, (SparseFeat, VarLenSparseFeat)), feature_columns)) if len(
feature_columns) else []
dense_feature_columns = list(
filter(lambda x: isinstance(x, DenseFeat), feature_columns)) if len(feature_columns) else []
dense_input_dim = sum(map(lambda x: x.dimension, dense_feature_columns))
if feature_group:
sparse_input_dim = len(sparse_feature_columns)
else:
sparse_input_dim = sum(feat.embedding_dim for feat in sparse_feature_columns)
input_dim = 0
if include_sparse:
input_dim += sparse_input_dim
if include_dense:
input_dim += dense_input_dim
return input_dim
Appendix: 여러 Activation Layer를 이름에 따라 정의하기 위하여 아래와 같이 선언
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
def activation_layer(act_name, hidden_size=None, dice_dim=2):
"""Construct activation layers
Args:
act_name: str or nn.Module, name of activation function
hidden_size: int, used for Dice activation
dice_dim: int, used for Dice activation
Return:
act_layer: activation layer
"""
if isinstance(act_name, str):
if act_name.lower() == 'sigmoid':
act_layer = nn.Sigmoid()
elif act_name.lower() == 'linear':
act_layer = Identity()
elif act_name.lower() == 'relu':
act_layer = nn.ReLU(inplace=True)
elif act_name.lower() == 'dice':
assert dice_dim
act_layer = Dice(hidden_size, dice_dim)
elif act_name.lower() == 'prelu':
act_layer = nn.PReLU()
elif issubclass(act_name, nn.Module):
act_layer = act_name()
else:
raise NotImplementedError
return act_layer
Step 2. Projection Step
FE Block Module은 Late-Interaction뿐만 아니라 Early-Interaction을 사용하기 위하여 Early-Interaction까지 사용한다. 이를 위하여 Dimension을 맞추기 위한 Porjection과정이 필요하다.
먼저 기존의 Formula는 아래와 같이 정의하였다.
$$m_u^{i,h} = W_u^{i,h} h_u^i + b_u^{i,h}, h=1, 2, \ldots, H$$
- \(i\): 몇 번째 FC Layer의 Output인가.
- \(H\): Heads의 갯수
- \(h_u^i\): Output of i-th User FC Layer Output
- \(W_u^{i,h} \in \mathbb{R}^{d_i \times p}\): Weight
- \(b_u^{i,h} \in \mathbb{R}^{p}\): Bias
- \(m_u^{i,h} \in \mathbb{R}^{p}\): 각각의 Heads
- \(M_u^i \in \mathbb{R}^{pH} = \textit{Concat}(m_u^{i,1}, \ldots, m_u^{i,H})\)
실제 구현된 코드를 보면 아래와 같이 구현하였다.
fc = self.linears[i](deep_input): \(h_u^i\)user_temp = self.Fe_linears[i](deep_input): \(m_u^{i,h} = W_u^{i,h} h_u^i + b_u^{i,h}\)self.user_fe_rep.append(user_temp): \(M_u^i \in \mathbb{R}^{pH} = \textit{Concat}(m_u^{i,1}, \ldots, m_u^{i,H})\)
Future Work#1: Dimension of Hidden Layer
현재 Input으로 들어오는 Dataset의 Shape는 Batch x 129 이다.
하지만, Hidden Dimension으로 Setting한 Dimension의 크기는 [300, 300, 128]이다. 이렇게 Dimension이 늘어나게 구성하는 것이 가능한 것인지 확인할 필요가 있다.
Future Work#2: Dimension of Projection Step
현재 Input으로 들어오는 Dataset의 Shape는 Batch x Dimension of Hidden Layer (300, 300, 128) 이다.
하지만, Projection되는 Dimension은 1024 (Dimension of Field (32) x Number of Heads (32)) 이다. 이렇게 Dimension이 늘어나게 구성하는 것이 가능한 것인지 확인할 필요가 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
class User_Fe_DNN(nn.Module):
def __init__(self, inputs_dim, field_dim, hidden_units, activation='relu', l2_reg=0, dropout_rate=0, use_bn=False,
init_std=0.0001, user_head =6, dice_dim=3, seed=1024, device='cpu'):
super(User_Fe_DNN, self).__init__()
'''
Argument
dnn_hidden_units=(300, 300, 128) # Hidden Layer Dimension 및 몇개를 사용할 것 인지
field_dim = 32 # 각 Head의 Dimension
dnn_activation='relu' # Activation 종류 선택
l2_reg_dnn=0
dnn_dropout = dropout # Dropout 비율
dnn_use_bn = True # Batch Normalization 사용 여부
user_head = 32 # 사용할 User Head 갯수
init_std=0.0001 # For Weight Normalization
'''
self.dropout_rate = dropout_rate
self.dropout = nn.Dropout(dropout_rate)
self.seed = seed
self.l2_reg = l2_reg
self.use_bn = use_bn
self.user_head = user_head
self.field_dim = field_dim
# Define Input Dimension
if len(hidden_units) == 0:
raise ValueError("hidden_units is empty!!")
if inputs_dim > 0:
hidden_units = [inputs_dim] + list(hidden_units)
else:
hidden_units = list(hidden_units)
self.linears = nn.ModuleList(
[nn.Linear(hidden_units[i], hidden_units[i+1]) for i in range(len(hidden_units) - 1)])
self.Fe_linears = nn.ModuleList(
[nn.Linear(hidden_units[i], self.field_dim*self.user_head) for i in range(len(hidden_units) - 1)])
# self.user_Fe_rep = []
if self.use_bn:
self.bn = nn.ModuleList(
[nn.BatchNorm1d(hidden_units[i+1]) for i in range(len(hidden_units) - 1)])
self.activation_layers = nn.ModuleList(
[activation_layer(activation, hidden_units[i+1], dice_dim) for i in range(len(hidden_units) - 1)])
for name, tensor in self.linears.named_parameters():
if 'weight' in name:
nn.init.normal_(tensor, mean=0, std=init_std)
self.to(device)
def forward(self, inputs):
deep_input = inputs # B x F
self.user_fe_rep = []
for i in range(len(self.linears)):
fc = self.linears[i](deep_input) # B x H
user_temp = self.Fe_linears[i](deep_input) # B x (Field Dimension X Number of heads)
self.user_fe_rep.append(user_temp)
if self.use_bn:
fc = self.bn[i](fc)
fc = self.activation_layers[i](fc)
fc = self.dropout(fc)
deep_input = fc
return self.user_fe_rep
Input
1
sparse_dnn_input = torch.flatten(User_sim_embedding, start_dim=1) # B, (F x Embedding) // Concat
만약 Continuous Value가 있어서 사용하는 경우 -> Concat하여 FC Layer의 Input으로 사용한다.
1
2
3
4
5
if(len(user_dense_value_list)>0):
dense_dnn_input = torch.flatten(torch.cat(user_dense_value_list, dim=-1), start_dim=1)
user_dnn_input = torch.cat([sparse_dnn_input, dense_dnn_input],axis=-1)
else:
user_dnn_input = sparse_dnn_input # B, (F x Embedding + Continuous Value Dimension)
Result
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
dnn_hidden_units=(300, 300, 128) # Hidden Layer Dimension 및 몇개를 사용할 것 인지
field_dim = 32 # 각 Head의 Dimension
dnn_activation='relu' # Activation 사용 여부
l2_reg_dnn=0
dnn_dropout = dropout # Dropout 비율
dnn_use_bn = True # Batch Normalization 사용 여부
user_head = 32 # 사용할 User Head 갯수
init_std=0.0001 # For Weight Normalization
user_fe_dnn= User_Fe_DNN(compute_input_dim(user_dnn_feature_columns),
field_dim,
dnn_hidden_units,
activation=dnn_activation,
l2_reg=l2_reg_dnn,
dropout_rate=dnn_dropout,
use_bn=dnn_use_bn,
user_head = user_head,
init_std=init_std,
device=device)
user_dnn_embedding = None
'''
List
- Element Shapr: Batch Size x (Field Dimension X Number of heads)
- Length: Number of Hidden Layer
'''
user_fe_rep = user_fe_dnn(user_dnn_input.to(torch.float32))
# Last FC Layer Output // Batch Size x (Field Dimension X Number of heads)
user_dnn_embedding = user_fe_rep[-1]
Item Vector
위에서 선언한 Layer와 Function을 활용하여 Item Vector를 구한다.
1
2
3
4
5
6
7
8
9
10
11
12
# Embedding Layer
item_sparse_embedding_list, item_dense_value_list = \
input_from_feature_columns(X, item_dnn_feature_columns, item_embedding_dict)
item_sparse_embedding = torch.cat(item_sparse_embedding_list, dim=1)
# Light SE-Module
item_filed_size = 2
Item_sim_non_local = LightSE(item_filed_size, seed, device)
Item_sim_embedding = Item_sim_non_local(item_sparse_embedding)
sparse_dnn_input = torch.flatten(Item_sim_embedding, start_dim=1)
dense_dnn_input = torch.flatten(torch.cat(item_dense_value_list, dim=-1), start_dim=1)
item_dnn_input = torch.cat([sparse_dnn_input, dense_dnn_input], axis=-1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from layers.core import Item_Fe_DNN
# FE Block -> Projection
item_head=32
item_fe_dnn = Item_Fe_DNN(compute_input_dim(item_dnn_feature_columns),
field_dim,
dnn_hidden_units,
activation=dnn_activation,
l2_reg=l2_reg_dnn,
dropout_rate=dnn_dropout,
use_bn=dnn_use_bn,
item_head = item_head,
init_std=init_std,
device=device)
item_dnn_embedding = None
item_fe_rep = item_fe_dnn(item_dnn_input.to(torch.float32))
item_dnn_embedding = item_fe_rep[-1]
Step 3. Interaction Step
위에서 얻은 각각의 Embedding을 통하여 relevance score(similarity) 및 Prediction을 구한다.
relevance score(similarity)
$$S_{u,v}^i = \sum_{h_u=1}^H \text{max}_{h_v \in 1,2,\ldots,H} \{(m_u^{i,h_u})^T m_v^{L,h_v}\}$$
Prediction
$$\hat{y} = \sum_{i=1}^L S_{u,v}^i$$
Algorithm Step
- User Heads중 특정 Head하나를 고정한다.: \(m_u^{i,h_u}\)
- Item Heads모두와 Similairty를 구하고 가장 큰 값을 구한다.: \(\text{max}_{h_v \in 1,2,\ldots,H} \{(m_u^{i,h_u})^T m_v^{L,h_v}\}\)
- 위의 과정을 User Heads모두에 반복하여 적용하여 Relevance Score를 구하게 된다.: \(S_{u,v}^i = \sum_{h_u=1}^H \text{max}_{h_v \in 1,2,\ldots,H} \{(m_u^{i,h_u})^T m_v^{L,h_v}\}\)
- 3에서 얻은 과정을 User FC i-th Layer에 모두 적용한다.: \(\hat{y} = \sum_{i=1}^L S_{u,v}^i\)
위의 과정을 코드에 적용하면 아래와 같다.
user_temp: \(m_u^{i,h_u}\)item_temp: \(m_v^{L,h_v}\}\)(user_temp @ item_temp.permute(0, 2, 1)).max(2).values.sum(1): \(S_{u,v}^i = \sum_{h_u=1}^H \text{max}_{h_v \in 1,2,\ldots,H} \{(m_u^{i,h_u})^T m_v^{L,h_v}\}\)score = torch.stack(score).transpose(1, 0), torch.sum(score, 1): \(\hat{y} = \sum_{i=1}^L S_{u,v}^i\)ㅇ
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
def fe_score(user_rep, item_rep, user_fea_col, item_fea_col, user_embedding_dim, item_embedding_dim):
'''
- user_rep: 모든 User FC Layer의 Output 입니다.
- item_rep: 모든 Item FC Layer의 Output 입니다.
- user_fea_col: User Heads의 갯수 입니다.
- item_fea_col: Item Heads의 갯수 입니다.
- user_embedding_dim: List형태로서, 각 user_rep 의 element(User i-th FC Layer Output)의 Dimension 입니다.
- item_embedding_dim: List형태로서, 각 item_rep 의 element(Item i-th FC Layer Output)의 Dimension 입니다.
Notation
- B: Batch Size
- H: Number of Heads
- HD: Dimension of Head
'''
score = []
# User i-th FC Layer Output을 선택합니다.
for i in range(len(user_embedding_dim)):
# User i-th FC Layer Output을 선택합니다.
'''
- Input: user_rep[i]: B X (H X HD)
- Output: user_temp: B x H X HD
'''
user_temp = torch.reshape(user_rep[i], (-1, user_fea_col, user_embedding_dim[i]))
# Item Last FC Layer Output을 선택합니다.
item_temp = torch.reshape(item_rep[-1], (-1, item_fea_col, item_embedding_dim[i]))
'''
- (user_temp @ item_temp.permute(0, 2, 1)):
- Shape: B X H X H
- Description: 각 User-Head 와 Item-Head에 대한 dot product (similarity)를 수행한다.
- Appendix: 각 차원의 Dimension의 의미
- 0: Batch
- 1: User Head를 의미
- 2: Item Head를 의미
- (user_temp @ item_temp.permute(0, 2, 1)).max(2).values:
- Shape: B x H
- Description: 하나의 User-Head를 고정하고, 모든 Item-Head와의 Similairty중에 가장 큰 값을 선택한다.
- (user_temp @ item_temp.permute(0, 2, 1)).max(2).values.sum(1):
- Shape: B
- Description: 위의 과정을 모든 User-Head에 적용하여 Summation 한다.
'''
score.append((user_temp @ item_temp.permute(0, 2, 1)).max(2).values.sum(1))
score = torch.stack(score).transpose(1, 0)
return torch.sum(score, 1)
Result
1
2
3
4
5
score = fe_score(user_fe_rep, item_fe_rep, user_head, item_head, \
[field_dim, field_dim, field_dim],\
[field_dim, field_dim, field_dim])
score
1
2
3
tensor([2.4253, 2.4889, 2.6910, 2.7736, 2.6505, 2.7698, 2.7587, 2.6291, 2.5361,
2.4785, 2.6214, 2.6614, 2.5035, 2.7104, 2.4393, 2.7446],
grad_fn=<SumBackward1>)
CIR
CIR Module은 “Contrastive Interaction Regularization을 통하여 Interaction을 강조하게 하는 Module” 입니다.
$$L_{cir} = -\frac{1}{Q} \sum_{(u,v) \in Q} \text{log} \frac{\text{exp}(\text{sim}(M_u^L, M_v^L)/\tau)}{\sum_{(u', v') \in N} \text{exp}(\text{sim}(M_{u'}^L, M_{v'}^L)/\tau)}$$
- \(sim(\cdot)\): Similarity
- \(sim(M_u^L, M_v^L) = (M_u^L)^T M_v^L / (\|M_u^L\| \cdot \| M_v^L\|)\)
- \(Q\): The total number of positive instances
- N: Total number of samples
CIR 코드 구현
개인적인 생각으로는 해당 Loss Function의 코드 구현은 잘못 되었습니다. 수정하여 사용할 필요가 있습니다. 잘못되었다고 생각하는 이유는 아래와 같습니다.
먼저, 논문의 수식과 코드가 일치하는 부분 입니다.
user_embedding = torch.nn.functional.normalize(user_embedding, dim=-1): \(M_{u, u'}^L/\|M_{u, u'}^L\|\)item_embedding = torch.nn.functional.normalize(item_embedding, dim=-1): \(M_{v, v'}^L/\|M_{v, v'}^L\|\)scores = torch.matmul(user_embedding, item_embedding.t()) / tau: \(\text{sim}(M_{u, u'}^L, M_{v, v'}^L)/\tau)\)exp_scores = scores.exp(): \(\text{exp}(\text{sim}(M_{u, u'}^L, M_{v, v'}^L)/\tau))\)user_embedding = torch.nn.functional.normalize(user_embedding, dim=-1): \(M_u^L/\|M_u^L\|\)
아래 부분부터는 논문 수식과 코드가 잘못되었다고 생각하는 부분 입니다.
먼저 코드와 수식을 생각하면 아래와 같습니다.
exp_scores:- \(\text{exp}(\text{sim}(M_{u, u'}^L, M_{v, v'}^L)/\tau))\)
- Shape: Batch Size x Batch Size
해당 수식은 아래와 같은 Matrix로서 생각할 수 있습니다.
user_embedding- \(U=[U_1, ..., U_B], B=\text{Batch Size}\)
item_embedding- \(V=[V_1, ..., V_B], B=\text{Batch Size}\)
exp_scores- \(\begin{bmatrix} U_1 \cdot V_1 & \cdots & U_1 \cdot V_B \\ \vdots & \ddots & \vdots \\ U_B \cdot V_1 & \cdots & U_B \cdot V_B \end{bmatrix}\)
현재 우리가 가지고 있는 데이터셋은 \(X = [[U_1, V_1, y_1], [U_2, V_2, y_2], ..., [U_B, V_B, y_B]]\)라고 생각할 수 있다.
하지만, 아래 Code를 수행하게 되면 (exp_scores.sum(dim=1), scores[range(scores.shape[0]), y])
우리는 모든 User와 Item에 Pair에 대한 Contrastive Loss를 적용하게 되는 것 이다. 즉, 우리는 Interaction이 없어서 알 수 없는 정보에 대하여 이상한 label값을 사용하게 된다.
Example Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
scores_matrix = np.array(
[
[11, 12, 13, 14],
[21, 22, 23, 24],
[31, 32, 33, 34],
[41, 42, 43, 45]
]
)
y_ex = np.array([0, 1, 0, 0]).reshape(4, 1)
scores_matrix[range(scores_matrix.shape[0]), y_ex]
'''
array([[11, 21, 31, 41],
[12, 22, 32, 42],
[11, 21, 31, 41],
[11, 21, 31, 41]])
'''
해당 코드를 사용하기 위해서는 (1) 다른 논문 (InfoNCE)를 참조하여, 해당 코드를 검증하거나, (2) 해당 수식에 맞게 데이터를 전처리해서 가져오는 과정이 필요하거나, (3) 위의 코드에서 Diagonal Element를 가져오는 과정이 필요하다.
Appendix: 실제 Training Code
실제 구현하여 Training 하는 코드에서도 아래와 같이 Training을 진행 하였다.
1
2
3
4
5
6
7
8
9
10
11
12
# CIR Loss
contras = contrast_loss(y_contras, user_embedding, item_embedding)
# FE Loss
loss = loss_func(y_pred, y.squeeze(), reduction='sum')
# Regularization Loss
reg_loss = self.get_regularization_loss()
# CIR Loss빼고 학습
# total_loss = loss + reg_loss + self.aux_loss + contras
total_loss = loss + reg_loss + self.aux_loss
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def contrast_loss(y, user_embedding, item_embedding):
# Normalize the embeddings
user_embedding = torch.nn.functional.normalize(user_embedding, dim=-1)
item_embedding = torch.nn.functional.normalize(item_embedding, dim=-1)
# Set temperature parameter
tau = 0.07
# Compute similarity scores
scores = torch.matmul(user_embedding, item_embedding.t()) / tau
# Subtract max for numerical stability
scores -= scores.max()
exp_scores = scores.exp()
# Compute the loss
loss = torch.log(exp_scores.sum(dim=1)) - scores[range(scores.shape[0]), y]
loss = loss.mean()
return loss
Leave a comment