
Paper35. Personalized Transfer of User Preferences for Cross-domain Recommendation
Personalized Transfer of User Preferences for Cross-domain Recommendation
Abstract
Cold-start problem is still a very challenging problem in recommender systems. Fortunately, the interactions of the cold-start users in the auxiliary source domain can help cold-start recommenda- tions in the target domain. How to transfer user’s preferences from the source domain to the target domain, is the key issue in Cross- domain Recommendation (CDR) which is a promising solution to deal with the cold-start problem. Most existing methods model a common preference bridge to transfer preferences for all users. Intuitively, since preferences vary from user to user, the prefer- ence bridges of different users should be different. Along this line, we propose a novel framework named Personalized Transfer of User Preferences for Cross-domain Recommendation (PTUPCDR). Specifically, a meta network fed with users’ characteristic embeddings is learned to generate personalized bridge functions to achieve personalized transfer of preferences for each user. To learn the meta network stably, we employ a task-oriented optimization procedure. With the meta-generated personalized bridge function, the user’s preference embedding in the source domain can be transformed into the target domain, and the transformed user preference embed- ding can be utilized as the initial embedding for the cold-start user in the target domain. Using large real-world datasets, we conduct extensive experiments to evaluate the effectiveness of PTUPCDR on both cold-start and warm-start stages. The code has been available at https://github.com/easezyc/WSDM2022-PTUPCDR.
해당 논문은 Embedding and Mapping 방법으로서, Target Domain에 대하여 Source Domain의 각각의 User’s Characteristic Embeddingm을 하는것을 목표로 한다. 이는 Cold-Start Problem외에 다르 Warm-start 에서도 잘 작동하는 것을 보여준다.
Introduction
PTUPCDR learns a meta network that takes users’ characteristic embeddings in the source domain as input and gener- ates personalized bridges for each user, as shown in Figure 1(b). The generated bridge functions can be viewed as a model parameterized by the learned meta network. Note that the personalized bridge functions which depend on the users’ characteristics vary from user to user, so the process of the preference transfer is personal- ized, which can capture preference relationships between different domains better than existing methods. After training, we feed user embeddings in the source domain into the meta-generated personalized bridge functions and obtain the transformed user embeddings. The transformed user embeddings are utilized as the initial em- beddings in the target domain. With the initial embeddings, our method is effective for cold-start users who have no interactions in the target domain.
해당 논문에서도, CDR의 목표를 Cold-Start Problem을 해결하기 위한 논문이라고 정의하고 있다.
즉, 우리는 Interaction이 풍부한, Source A를 가지고 있을 때, Source A의 도움을 받아 -> Target Domain의 성능을 올리는 것을 기대 한다.
해당 논문에서는 이러한 해결 방법으로서 User Meta Learning을 진행하였다. 즉, Source Domain의 User historical information을 활용하여, Target Domain에 대하여 Embedding 생성을 목표로 한다. 해당 방법으로 Embedding을 진행하게 되면, Source Domain에서 유사한 Item을 구입한 User끼리 Embedding을 진행 할 수 있다. 따라서 Cold-Start Probelm을 해결할 수 있다.
위와 같은 Flow는 아래 Figure를 살펴보면 된다.
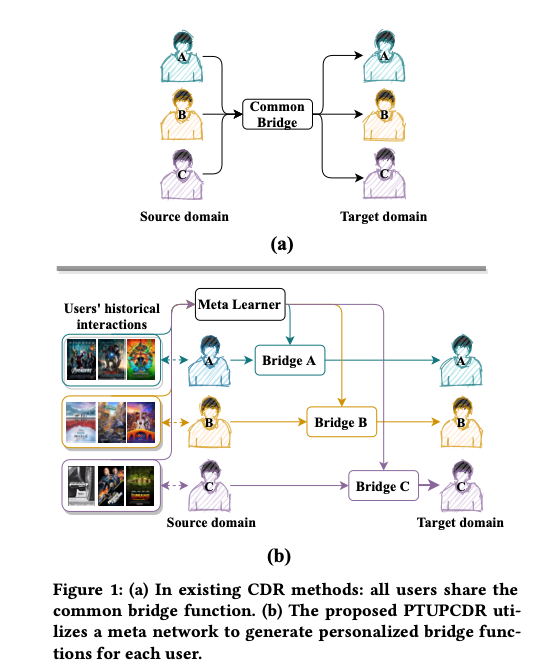
또한, 주요한 부분은 많은 다른 논문들을 찾아봤을때, 기존에 가지고 있는 User에 대해서만 Embedding 혹은 Prediction이 가능하다. 즉, 새로운 User Input에 대하여 Embedding 혹은 Prediction이 불가능하다. (대부분이 Graph Convolution Network or Matrix Factorization 기반이므로) 하지만, 해당 논문에서는 이러한 상황을 큰 문제로 제시하고, 해당 방법은 모든 User에 대하여 Embedding 및 Prediction이 가능하다고 한다.
Model
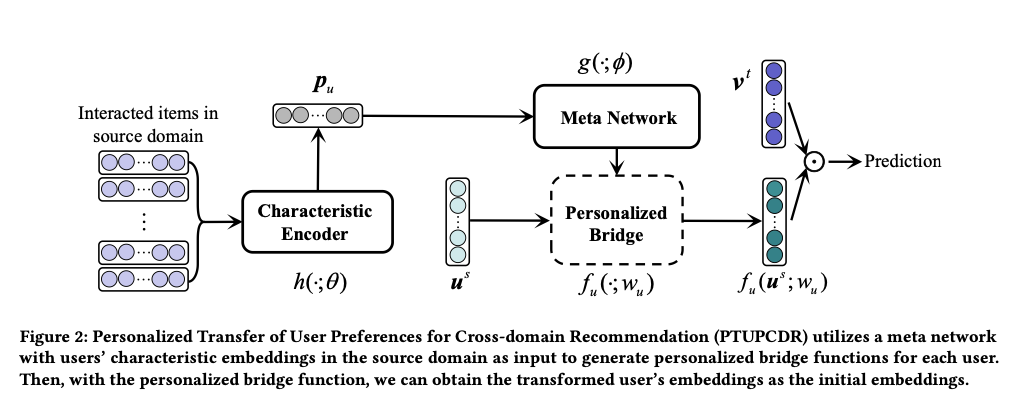
Problem Setting
- \(\mathcal{U} = \{ u_1, u_2, \ldots \}\): User set
- \(\mathcal{V} = \{ v_1, v_2, \ldots \}\): Item set
- \(r_{ij} \in \mathcal{R}\): Rating matrix with \(u_i, v_j\)
- \(\mathcal{U}^s, \mathcal{V}^s, \mathcal{R}^s\): Source Domain Dataset
- \(\mathcal{U}^t, \mathcal{V}^t, \mathcal{R}^t\): Target Domain Dataset
- \(\mathcal{U}^o = \mathcal{U}^s \cap \mathcal{U}^t\): Overlapping User
- \(\mathcal{V}^s, \mathcal{V}^t\): No shared item between two domains
- \(u_i^d \in \mathbb{R}^k, v_i^d \in \mathbb{R}^k, \text{s.t. }d \in \{ s,t \}\): Item and User Ebmedding with dimension k (Domain과 User, Item상관 없이 모두 동일한 Dimension으로 Embedding 되었다고 가정.)
- \(S_{u_i} = \{ v_{t_1}^s, v_{t_2}^s, \ldots, v_{t_n}^s\}\): Source Domain(s)에서 User(\(u_i\))가 TimeStamp(\(t_n\))까지 Interaction이 있었던 모든 Item Set
Characteristic Encoder
Source Domain의 User 특성을 Target Domain으로 옮기기 위해서 가장 먼저 진행되어야 할 사항은 “Source Domain에서 User들의 특성을 잘 분류 하는 것 이다.”
해당 방법을 Characteristic Encoder라 지칭하고 있으며, 수식은 아래와 같다.
$$p_{u_i} = \sum_{v_j^s \in S_{u_i}} a_j v_j^s$$
$$p_{u_i} \in \mathbb{R}^k$$
$$a_j = \frac{\text{exp}(a_{j}^{'})}{\sum_{v_j^s \in S_{u_i}} \text{exp}(a_{j}^{'})}$$
$$a_{j}^{'} = h(v_j ; \theta),$$
$$h(\cdot) \text{ is two-layer feed-forward network}$$
위의 수식을 살펴보게 되면, Attention Mechanism을 활용하여 User Characteristic을 찾아내는 것을 확인할 수 있다. 수식의 의미를 그대로 따라가면 아래와 같다.
- Input으로 User(\(u_i\))에 대한 Interaction Item Embedding List(\(S_{u_i}\))가 들어온다.
- List의 원소인 각 Item(\(v_j\))을 Feed-forward network를 통하여 score로서 prediction한다. (\(a_{j}^{'}\))
- (2)의 결과값을 Softmax하여 Attention Score(\(a_j\))를 획득한다.
- 해당 Attention Score를 통하여 Weighted Average를 수행한다. (\(p_{u_i}\))
해당 Module에서 주요한 점은, \(h(\cdot)\)을 활용하여 Mapping하므로, Sequence의 TimeStamp정보는 전혀 활용하지 않는 다는 것 이다. -> 즉, 최근에 산 Item에 대하여 가중치를 주는 것이 아니라, Item 각각 별로 중요도를 판단한다는 것 이다.
Future Work
- TimeStamp정보를 활용하기 위해서는 단순히 Attention Score가 아닌, Decay Weight값 또한 추가하여야 한다.
Meta Network
※) 해당 Module에 대하여, 특이한 부분은 자세히 설명하지 않고 있습니가. 이부분에 대해서는 개인적인 해석이 포함되어 있습니다.
먼저, 위에서 우리는 Source Domain의 User hitorical interaction을 통하여, User 각각을 Embedding (\(p_{u_i} \in \mathbb{R}^k\)로 Embedding하였다.
이를 활용하여 Target Domain에 대한 User Embedding을 만들어야 한다. 해당 부분은 각각 1) Meta Network, 2) Personalized Bridge로 구성되 었다. 각각의 Component는 아래와 같은 역학을 수행한다.
Meta Network
해당 Component는 User의 구매 이력을 활용한 User Embedding을 Encoding -> Decoding하는 작업을 가지게 된다. Formula는 아래와 같다.
$$w_{u_i} = g(p_{u_i} ; \phi) \in \mathbb{R}^{k \times k}$$
차원을 2제곱하여 Decoding하는 과정을 거친다. 이러한 Embedding 결과는 User의 구매 이력을 나타내는 역할을 진행 한다.
Personalized Bridge
해당 Component는 Source Domain의 User 구매 이력과 + User만의 Feature를 활용하여 Target Domain의 User Embedding을 생성한다. Formula는 아래와 같다.
$$\hat{u}_i^t = f_{u_i}(u_i^s ; w_{u_i})$$
위의 수식을 살펴보게 되면, Source Domain에서의 User 구매 이력 (\(w_{u_i} \in \mathbb{R}^{k \times k}\))과 User 특성 (\(u_i^s \in \mathbb{R}^{k}\))를 활용하여 Target Domain에서의 User Embedding을 구하는 과정이다.
계산은 단순히 bmm을 통하여 이루워 지는 것을 알 수 있다.
※) 아래부터는 개인적인 해석입니다. (나중에 왜 이렇게 했는지 확인……..) 왜 User 구매 이력을 (k x k) 로서 Embedding을하고 User 특성 (k)을 bmm하는지는 정확히 나와있지 않습니다. 해당 부분에 대한 개인적인 생각은 Attention기법과 매우 유사하다고 느꼈습니다.
Task-oriented Optimization
위와같은 Model로서 Training하기 위해서는 아래와 같이 크게 2가지 Step으로 학습이 이루워 진다.
Personalized Bride를 학습 하여야 한다.
$$L = \sum_{u_i \in \mathcal{U}^o} \| \hat{u}_i^t - u_i^t\|^2$$
두번째 Step으로는 실제 prediction을 위한 학습을 진행해야 한다. Formula는 아래와 같다.
$$\text{min}_{\theta, \phi} \frac{1}{|R_o^t|} \sum_{r_{ij} \in R_o^t} (r_{ij} - f_{u_i}(u_i^s;w_{u_i}v_j) )^2,$$
$$R_o^t = \{ r_{ij}|u_i \in \mathcal{U}^o, v_j \in V^t \}$$
위의 수식을 살펴보게 되면, 간단히 Dot Prediction으로서 Similarity를 계산하고 MSE Loss로서 학습하는 것을 알 수 있다.
Overall Procedure
Pre-training stage
먼저, 학습을 진행하기 앞서, User와 Item을 Embedding하는 과정이 필요하다. 해당 논문에서는 아래와 같이 Embedding방법을 선택하였다.
$$\text{min}_{u,v} = \frac{1}{\| R \|} \sum_{r_{ij} \in R} (r_{ij} - u_iv_j)^2$$
위와 같이 Matrix Factorization을 통하여 User와 Item을 Embedding하였다.
※) 참고: 실험해 보야야 할 부분!
논문 원본대로 Rating Matrix만으로서 User, Item을 Embedding한다.
하지만, User, Item을 Embedding함에 있어서 위와 같이 Matrix Factorization으로 진행하지 않아도 될 것 같다. 각각의 Auto-Encoder 혹은 PCA로서 값을 고정하고, 진행해도 될 것 같다. 단, Item Feature를 어떻게 지정할지 생각하여야 한다.
Candidate 방법
- User Feature -> User Embedding 후 MF로 Item만 Update (단, 너무 큰 Matrix이므로, 어떻게 MF를 구현할지 생각….)
- MF의 Label을 단지 0 or 1로 할지, 혹은 0~1사이의 Normalization값을 사용할지 정해야 한다.
- 최대 구매횟수 5로 지정 후… Normalization하여 Continuous Value로 만든 뒤, MSE Loss를 진행해도 되지 않을까? -> Interaction의 횟수가 너무 다양할 것 같다.
Meta stage & Initialization stage
해당 부분에서, 공통된 User로서 학습한다.
※) 참고: 코드에서 확인해야 할 부분
- One-Step으로서 Meta stage & Initialization stage를 학습할 지 정해야 한다.
- Item Embedding하는 부분을 해당 과정에서 학습할 수 있지 않을까?….
- 만약, Target Domain에 User Embedding값이 있으면…. Prediction 값을 쓰는지 혹은, 원본 Embedding값을 쓰는지 확인이 필요하다.
Experiment
Dataset
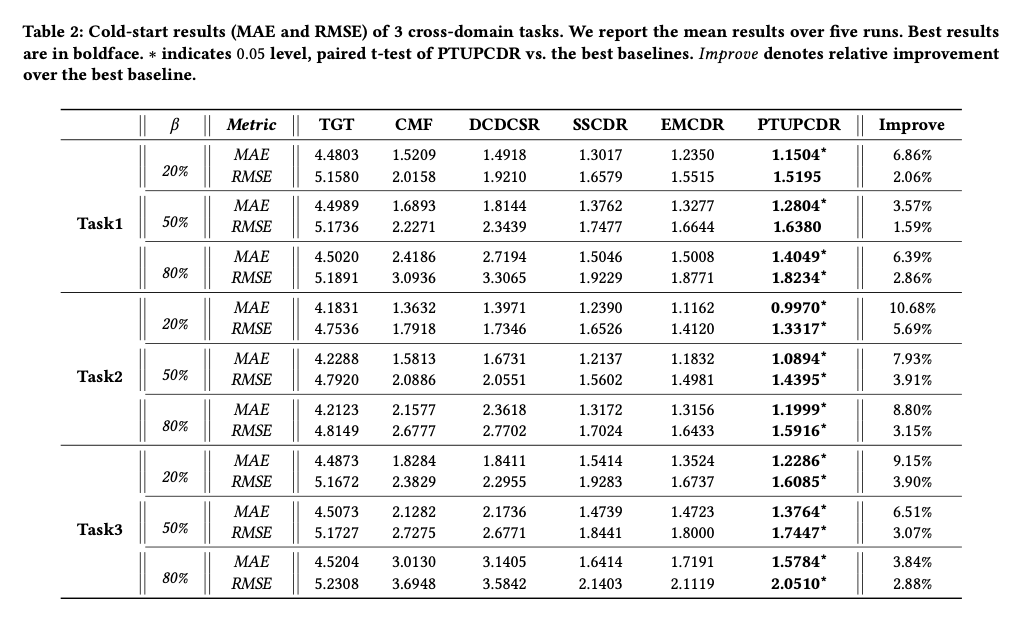
Result
아래 결과를 살펴보게 되면, \(\beta\)가 크면 클 수록 Cold-User(Overlap되지 않은 User)를 늘린 결과 이다.
해당 결과를 확인하게 되면, Overlap되지 않은 User를 늘리면, 늘릴수록 Metric을 떨어지나, 다른 Model들에 비해, 좋은 Performance를 보여 준다.
Leave a comment