
Django-Project-Model 선정
Model 선정
분류를 하기 위하여 6가지의 Classifier Model을 선택하고 각각을 Trainning 및 Parameter를 변화시키며 Accuracy를 확인하였다.
Train DataSet 과 Test DataSet을 분리하여 Overfitting의 여부를 확인하였다.
원래 Code는 Jupyter Notebook으로 한 Shell씩 실행시킨 코드를 GitHub에 올리기 위하여 모아둔 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
#Model.py
#Module Import
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
#DataSet 불러오기
data = pd.read_excel('Z_Data.xlsx')
data2 = pd.read_excel('X_Data.xlsx')
#Train, Test Data로 분리
X_train, X_test, y_train, y_test = train_test_split(data[['People','Univ','Park','Popular','Road','River']], data[['Count']], test_size=0.3, random_state=0)
X_train2, X_test2, y_train2, y_test2 = train_test_split(data2[['People','Park','Popular','Road','River']], data2[['Count']], test_size=0.3, random_state=0)
#GradientBoostingClassifier 결과 확인
from sklearn.ensemble import GradientBoostingClassifier
gbrt = GradientBoostingClassifier(random_state=0)
gbrt.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(gbrt.score(X_test, y_test)))
#GradientBoostingClassifier Parameter 변화
max =0
count1 =0
count2 =0
for i in range(1,10):
for j in np.arange(0.001,0.9,0.001):
gbrt = GradientBoostingClassifier(random_state=0,max_depth=i,learning_rate=j)
gbrt.fit(X_train, y_train)
if(gbrt.score(X_test, y_test)>max):
max = gbrt.score(X_test, y_test)
count1 =i
count2 =j
print("훈련 세트 정확도: {:.3f}".format(gbrt.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(gbrt.score(X_test, y_test)))
print('count1',i)
print('count2',j)
#RandomForestClassifier 결과 확인
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=100, random_state=0)
forest.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(forest.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(forest.score(X_test, y_test)))
#RandomForestClassifier Parameter 변화
max =0
count1 =0
for i in range(1,400):
forest = RandomForestClassifier(n_estimators=i, random_state=0)
forest.fit(X_train, y_train)
if(forest.score(X_test, y_test)>max):
max = forest.score(X_test, y_test)
count1 =i
print("훈련 세트 정확도: {:.3f}".format(forest.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(forest.score(X_test, y_test)))
#KNeighborsClassifier Parameter 변화 및 결과 확인
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pylab as plt
training_accuracy = []
test_accuracy = []
# 1에서 10까지 n_neighbors를 적용
neighbors_settings = range(1, 30)
for n_neighbors in neighbors_settings:
# 모델 생성
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
# 훈련 세트 정확도 저장
training_accuracy.append(clf.score(X_train, y_train))
# 일반화 정확도 저장
test_accuracy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label="Train Accuarcy")
plt.plot(neighbors_settings, test_accuracy, label="Test Accuarcy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
#DecisionTreeClassifier 결과 확인
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(random_state=0)
tree.fit(X_train, y_train)
print("훈련 세트 정확도: {:.3f}".format(tree.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(tree.score(X_test, y_test)))
#DecisionTreeClassifier Parameter 변화
max =0
count1 =0
for i in range(1,10):
tree = DecisionTreeClassifier(random_state=0,max_depth=i)
tree.fit(X_train, y_train)
if(tree.score(X_test, y_test)>max):
max = tree.score(X_test, y_test)
count1 =i
print("훈련 세트 정확도: {:.3f}".format(tree.score(X_train, y_train)))
print("테스트 세트 정확도: {:.3f}".format(tree.score(X_test, y_test)))
#SVC 결과 확인
from sklearn.svm import SVC
svc = SVC()
svc.fit(X_train2, y_train2)
print("훈련 세트 정확도: {:.2f}".format(svc.score(X_train2, y_train2)))
print("테스트 세트 정확도: {:.2f}".format(svc.score(X_test2, y_test2)))
#SVC Parameter 변화
max =0
count1 =0
count2 =0
for i in np.arange(0.1,10,0.1):
for j in np.arange(0.1,1000,0.1):
svc = SVC(C=j,gamma=i)
svc.fit(X_train2, y_train2)
if(svc.score(X_test2, y_test2)>max):
max = svc.score(X_test2, y_test2)
count1 =i
count2 =j
print("훈련 세트 정확도: {:.2f}".format(svc.score(X_train2, y_train2)))
print("테스트 세트 정확도: {:.2f}".format(svc.score(X_test2, y_test2)))
print('count1',i)
print('count2',j)
#MLPClassifier #SVC Parameter 변화 및 결과 확인
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import GridSearchCV
mlp = MLPClassifier(max_iter=100)
parameter_space = {
'hidden_layer_sizes': [(30,30,30),(30,10,10),(30,10,20),(30,20,20),(30,5,5),(5,30,30)],
'activation': ['tanh', 'relu'],
'solver': ['sgd', 'adam'],
'alpha': [0.0001, 0.05],
'learning_rate': ['constant','adaptive'],
}
clf = GridSearchCV(mlp, parameter_space, n_jobs=-1, cv=3)
clf.fit(X_train2, y_train2)
print('Best parameters found:\n', clf.best_params_)
mlp = MLPClassifier(max_iter=3000, alpha= 0.0001, activation= 'tanh', solver= 'adam', learning_rate= 'adaptive', hidden_layer_sizes= (5, 30, 30))
mlp.fit(X_train2,y_train2)
print("훈련 세트 정확도: {:.3f}".format(mlp.score(X_train2, y_train2)))
print("테스트 세트 정확도: {:.3f}".format(mlp.score(X_test2, y_test2)))
결과
| 모델 명 | 정확도(Traing) | 정확도(Test) | 과적합 여부 |
| MLPClassifier | 61.6 % | 61 % | X |
| GradientBoostingClassifie | 54.6 % | 52.2 % | X |
| K-NN | 57 % | 50 % | O |
| Decision Tree | 54 % | 50 % | X |
| SVM | 53 % | 52 % | X |
| Random Forest | 99.2 % | 52 % | O |
정확도가 가장높고, 과적합 하지 않은 모델 선정MLPClassifier가 모델로 선정
MLPClassifier
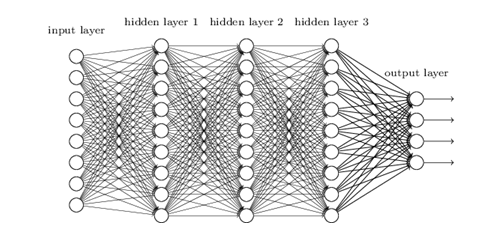
- 모델 구조 및 가정에서 최소의 요구를 가지고 있는 광범위한 예측 모델과 근사
- 모델 해석 가능성이 낮지만 좋은 예측력을 확보할 수 있음
참조:원본코드
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment