
Django-Project-데이터 전처리
데이터 전처리
Euclidean거리 계산 방식 이용
대여소로부터 최단거리의 “대학교, 자전거도로, 관광명소, 공원, 강”까지의 거리를 도출
Euclidean거리 계산 방식 이용
대여소로부터 1.5km내, 관측소들의 유동인구 평균을 도출
위도 경도를 가지고 거리(km)계산 Algorithm
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
#euclidean.py
import numbers
import math
class GeoUtil:
"""
Geographical Utils
"""
@staticmethod
def degree2radius(degree):
return degree * (math.pi/180)
@staticmethod
def get_harversion_distance(x1, y1, x2, y2, round_decimal_digits=5):
"""
경위도 (x1,y1)과 (x2,y2) 점의 거리를 반환
Harversion Formula 이용하여 2개의 경위도간 거래를 구함(단위:Km)
"""
if x1 is None or y1 is None or x2 is None or y2 is None:
return None
assert isinstance(x1, numbers.Number) and -180 <= x1 and x1 <= 180
assert isinstance(y1, numbers.Number) and -90 <= y1 and y1 <= 90
assert isinstance(x2, numbers.Number) and -180 <= x2 and x2 <= 180
assert isinstance(y2, numbers.Number) and -90 <= y2 and y2 <= 90
R = 6371 # 지구의 반경(단위: km)
dLon = GeoUtil.degree2radius(x2-x1)
dLat = GeoUtil.degree2radius(y2-y1)
a = math.sin(dLat/2) * math.sin(dLat/2) \
+ (math.cos(GeoUtil.degree2radius(y1)) \
*math.cos(GeoUtil.degree2radius(y2)) \
*math.sin(dLon/2) * math.sin(dLon/2))
b = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a))
return round(R * b, round_decimal_digits)
@staticmethod
def get_euclidean_distance(x1, y1, x2, y2, round_decimal_digits=5):
"""
유클리안 Formula 이용하여 (x1,y1)과 (x2,y2) 점의 거리를 반환
"""
if x1 is None or y1 is None or x2 is None or y2 is None:
return None
assert isinstance(x1, numbers.Number) and -180 <= x1 and x1 <= 180
assert isinstance(y1, numbers.Number) and -90 <= y1 and y1 <= 90
assert isinstance(x2, numbers.Number) and -180 <= x2 and x2 <= 180
assert isinstance(y2, numbers.Number) and -90 <= y2 and y2 <= 90
dLon = abs(x2-x1) # 경도 차이
if dLon >= 180: # 반대편으로 갈 수 있는 경우
dLon -= 360 # 반대편 각을 구한다
dLat = y2-y1 # 위도 차이
return round(math.sqrt(pow(dLon,2)+pow(dLat,2)),round_decimal_digits)
데이터 전처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
#Pre_Data.py
# goExcel.py
import pandas as pd
from pack.euclidean import GeoUtil
# 결과 엑셀로 저장하기
def makeExcel(name_rental, park, pop, river, road, univ, avg):
data.append([name_rental]+[park]+[pop]+[river]+[road]+[univ]+[avg])
table = pd.DataFrame(data, columns=('name_rental', 'Park', 'pop', 'river', 'road', 'univ', 'avg'))
table.to_excel("Data.xlsx", encoding="cp949", index=True)
# 공원 데이터 로드
data_park = pd.read_excel("park.xlsx", encoding = "CP949")
data_park.columns = ["name", "x", "y"]
data_park = data_park.dropna(axis=0)
# 관광명소
data_pop = pd.read_excel("pop.xlsx", encoding = "CP949")
data_pop.columns = ["name", "x", "y"]
data_pop = data_pop.dropna(axis=0)
# 강
data_river = pd.read_excel("river.xlsx", encoding = "CP949")
data_river.columns = ["name", "x", "y"]
data_river = data_river.dropna(axis=0)
# 자전거 도로
data_road = pd.read_excel("road.xlsx", encoding = "CP949")
data_road.columns = ["name", "x", "y"]
data_road = data_road.dropna(axis=0)
# 대학교
data_univ = pd.read_excel("univ.xlsx", encoding = "CP949")
data_univ.columns = ["name", "x", "y"]
data_univ = data_univ.dropna(axis=0)
# 유동인구
data_people = pd.read_excel("people.xlsx", encoding = "CP949")
data_people.columns = ["name", "count", "x", "y"]
data_people = data_people.dropna(axis=0)
# 대여소 데이터 로드
data_rental = pd.read_excel("map.xlsx", encoding = "CP949")
#print(type(raw_data2)
#data_rental.columns = ["gu", "bunho", "name", "x_value", "y_value"]
data_rental = data_rental.dropna(axis=0)
#print(data_rental.tail())
# 대여소-공원 간 거리 계산
data = []
print("엑셀 저장 작업 시작...")
for i in range(0, len(data_rental)):
loc_rental = [data_rental["x"][i], data_rental["y"][i]]
min1 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_park["x"][0], data_park["y"][0])
min2 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_pop["x"][0], data_pop["y"][0])
min3 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_river["x"][0], data_river["y"][0])
min4 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_road["x"][0], data_road["y"][0])
min5 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_univ["x"][0], data_univ["y"][0])
count = 0
sum = 0
for a in range(0, len(data_park)):
d1 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_park["x"][a], data_park["y"][a])
if d1 < min1:
min1 = d1
for a in range(0, len(data_pop)):
d2 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_pop["x"][a], data_pop["y"][a])
if d2 < min2:
min2 = d2
for a in range(0, len(data_river)):
d3 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_river["x"][a], data_river["y"][a])
if d3 < min3:
min3 = d3
for a in range(0, len(data_road)):
d4 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_road["x"][a], data_road["y"][a])
if d4 < min4:
min4 = d4
for a in range(0, len(data_univ)):
d5 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_univ["x"][a], data_univ["y"][a])
if d5 < min5:
min5 = d5
for a in range(0, len(data_people)):
d6 = GeoUtil.get_harversion_distance(data_rental["x"][i], data_rental["y"][i], data_people["x"][a], data_people["y"][a])
if d6 < 1.5:
sum += data_people["count"][a]
count += 1
if(count ==0):
sum = 1
count=1
people = sum/count
print("대여소명: ", data_rental["name"][i], ", 근접공원: ", min1, ", 근접관광지: ", min2,
", 근접강가:", min3, ", 근접 자전거도로: ", min4, ", 근접대학교:", min5, ", 근접유동인구 평균: ", people)
makeExcel(data_rental["name"][i], min1, min2, min3, min4, min5, people)
print("엑셀로 저장 완료")
빌린 횟수의 경우 범주형(1~5)사이 값으로 바꿈
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#Regulation.R
cen<-length(data$count)/5
for(i in 1:length(data2$count)){
if(i<cen)
data2$count[i] <-5
else if(i<cen*2)
data2$count[i] <-4
else if(i<cen*3)
data2$count[i] <-3
else if(i<cen*4)
data2$count[i] <-2
else
data2$count[i] <-1
}
결과
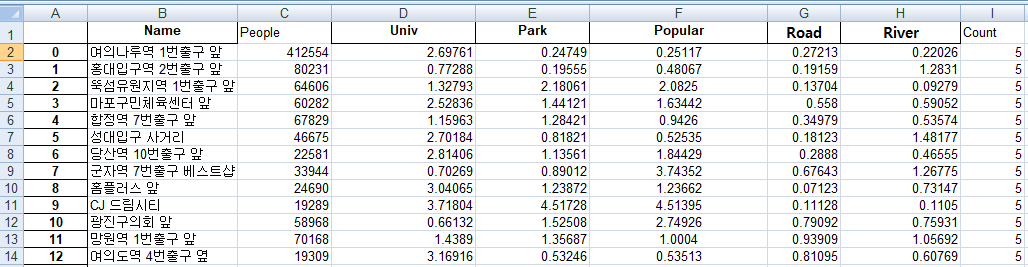
데이터 결측치 처리
유동인구의 경우 정류서 1.5km 이내의 유동인구이다.
즉, 1.5km의 유동인구의 자료가 없는 경우 0의 값으로 자료가 생성된다.
이에 따라 각 구간의 3% 미만의 Data는 Data의 중위수로 치환하는 과정을 진행하였다.
1036개의 Data중 10개의 Data값 변화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
for(i in 1:length(data$Count)){
if(i<cen*1){
if(data$People[i]< quantile(data$People[data$Count==5],0.03))
data$People[i] <- mean(data$People[data$Count==5])
}
else if(i<cen*2){
if(data$People[i]< quantile(data$People[data$Count==4],0.03))
data$People[i] <- mean(data$People[data$Count==4])
}
else if(i<cen*3){
if(data$People[i]< quantile(data$People[data$Count==3],0.03))
data$People[i] <- mean(data$People[data$Count==3])
}
else if(i<cen*4){
if(data$People[i]< quantile(data$People[data$Count==2],0.03))
data$People[i] <- mean(data$People[data$Count==2])
}
else{
if(data$People[i]< quantile(data$People[data$Count==1],0.03))
data$People[i] <- mean(data$People[data$Count==1])
}
}
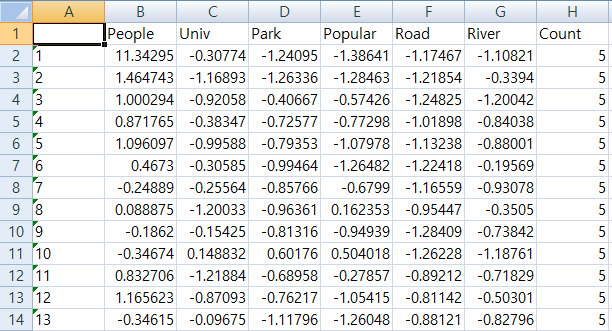
데이터 정규화
알맞은 Model을 선택하기 위하여 Z 변환과 MIN-MAX Normalization 두개를 사용하여 정규화를 진행하였다.
| 명칭 | 수식 | 문법 | 의미 |
| Z 변환 | (x-mean(x))/sd(x) | scale() | 평균0, 표준편차 1로 값 변환 |
| MIN-MAX Normalization | (x-min(x) /(max(x)-min(x)) | X | 0~1값으로 값 변환 |
정규화 과정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
library(readxl)
library(xlsx)
data = read_excel('Data.xlsx')
#Z변환으로 정규화 후 Data 저장
data$People <- scale(data$People)
data$Univ <- scale(data$Univ)
data$Park <- scale(data$Park)
data$Road <- scale(data$Road)
data$River <- scale(data$River)
data$Popular <- scale(data$Popular)
write.xlsx(data,'Z_Data.xlsx')
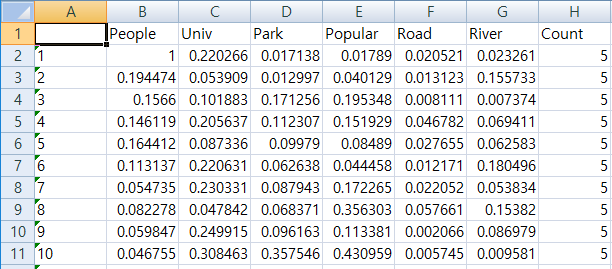
#[0-1]변환으로 정규화 후 Data 저장
data$People <- (data$People-min(data$People))/(max(data$People)-min(data$People))
data$Univ <- (data$Univ-min(data$Univ))/(max(data$Univ)-min(data$Univ))
data$Park <- (data$Park-min(data$Park))/(max(data$Park)-min(data$Park))
data$Road <- (data$Road-min(data$Road))/(max(data$Road)-min(data$Road))
data$River <- (data$River-min(data$River))/(max(data$River)-min(data$River))
data$Popular <- (data$Popular-min(data$Popular))/(max(data$Popular)-min(data$Popular))
write.xlsx(data,'X_Data.xlsx')
Z_Data 사진
X_Data 사진
참조:원본코드
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment