
R-통계 기초
통계기초
기술통계와 추론통계
- 기술통계: 수집한 데이터를 요약 묘사 설명하는 통계 기법
- 평균값, 중위수, 최빈수, 최대값, 최소값, 범위, 분산….
- 추론통계: 수집한 데이터를 바탕으로 추론 예측하는 통계 기법
- 선거철 후보자의 지지도 조사
- 선거철 후보자의 지지도 조사
척도: 조사 대상을 측정하기 위해 임의로 부여한 숫자간의 관계
- 명목척도(Nominal Scale): 가장 낮은 수준의 척도로 단지 측정대상의 특성만 구분하기 위하여 숫자나 기호를 할당한 것으로 특성간의 양적인 분석을 할 수 없고, 때문에 특성간에 대소의 비료도 할 수 없다.
- 서열척도(Ordinal Scale): 측정대상의 특성들을 구분하여 줄뿐만 아니라 이들 사이의 상대적인 크기를 나타낼 수 있고, 서로 간에 비교가 가능한 척도
- 등간척도(Interval Scale): 명목척도와 서열척도의 특징을 모두 가지고 있으면서 크기가 어느 정도나 되는지, 특성간의 차이가 어느 정도나 되는지 파악이 가능한 척도
- 비율척도(Ratio Scale): 가장 높은 수준의 척도로서, 가장 자세한 정보를 제공, 서로의 구분, 크기의 비교, 크기의 차이, 그리고 특성들 간의 계산까지 가능한 수준, 모두 숫자로 표현되고 그것들의 계산이 가능한 척도
왜도,첨도
- 왜도: 분포의 비대칭 정도를 나타내는 통계량
- 첨도: 분포의 꼬리부분의 길이와 중앙부분의 뾰족함에 대한 정보를 제공
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
#기술통계보고서 작성예시
data<-read.csv("C:/git/R/Datadescriptive.csv",header=T)
head(data,3) #지정한 수만큼 데이터 출력가능
table(data$resident)
table(data["resident"]) #상동
#척도별 기술통계량
dim(data)
str(data)
summary(data)
#명목척도: 평균,요약 통계량은 별 의미 없다! 카테고리 분류따위에 효과적.
unique(data$gender)
summary(data$gender)
table(data$gender)
data<-subset(data,data$gender==1 | data$gender==2) #결과값이 1,2인 데이터만 추출
unique(data$gender)
x<-table(data$gender)
barplot(x)
y<-round(prop.table(x),2)
y
#서열척도: 계급을 수치로 표현
summary(data$level)
x1<-table(data$level)
x1
barplot(x1)
round(prop.table(x1),2)
#등간척도
survey<-data$survey
summary(survey)
x2<-table(survey)
x2
hist(survey)
#비율척도
summary(data$cost)
mean(data$cost,na.rm=TRUE)
plot(data$cost)
hist(data$cost)
#아웃라이어(주변값) 제거작업
data<-subset(data,data$cost>=2&data$cost<=10)
head(data)
x3<-data$cost
x3
summary(x3)
table(x3)
hist(x3)
plot(x3)
#데이터 범주화
data$cost2[data$cost>=1&data$cost<=3]<-1
data$cost2[data$cost>=4&data$cost<=6]<-2
data$cost2[data$cost>=7]<-3
table(data$cost2)
hist(data$cost2)
install.packages("moments")
library(moments)
co<-data$cost #생활비 비율척도
co
#왜도: 평균 중심으로 기울어진 척도
skewness(co) #-0.297234(음수): 오른쪽으로 치우쳐져있다.
hist(co,density = co)
#첨도: 그래프의 뾰족한 정도 (자료가 중앙에 얼마나 몰려있는지)
kurtosis(co)
hist(co)
#보고서 작성
data$resident2[data$resident==1]<-"특별시"
data$resident2[data$resident>=2&data$resident<=2]<-"광역시"
data$resident2[data$resident==5]<-"시/구/군"
table(data$resident2)
#가공작업
summary(data$cost)
sum(data$cost)
write.csv(data,"./desc_report1.csv") #가공된 데이터로 저장하기로
독립변수, 종속변수
- 종속변수: 반응변수, 결과변수, 어떠한 영향을 받는 변수(Y)
- 독립변수: 설명변수, 원인변수, 종속변수에 의해 영향을 주는 변수(X)
| 독립변수 | 종속변수 | 분석방법 |
|---|---|---|
| 범주형 | 범주형 | 카이제곱 검정 |
| 범주형 | 연속형 | T검정, ANOVA |
| 연속형 | 범주형 | 로지스틱 회귀 분석 |
| 연속형 | 연속형 | 회귀분석 |
검정방법
- 모수적 방법: 모집단이 정규분포를 따른다는 가정하에 사용되는 통계 분석(일반적인 방법)
- 비모수적 방법: 수집된 자료가 정규분포를 하지 않는 경우
모집단이 정규분포를 할 때는 표본수가 커질수록 정규분포에 가까워지게 된다.. 즉 표본수가 작을 때 정규분포를 하기 어려워지고 모집단이 정규분포를 따르는지를 알 수 없게 되기 때문에 이때 비모수 검정을 사용하게 된다.
측정 자료가 명목형(이산형)일 경우도 마찬가지로 정규분포를 하지 않죠. 예를 들어 얘기해서 남.녀의 수를 비교한다는 것은 정규분포를 할 수 없다.
참조: 미래교육디자인연구소 블로그
귀무가설, 대립가설, p-value
귀무가설(H0): 관습적이고 보수적인 주장, 차이가 없다.
대립가설(H1): 적극적으로 입증하려는 주장, 차이가 있음을 통계적 근거를 통해 입증하고 하는 주장
p-value(유의확률): 대립가설이 틀릴 확률
출력결과
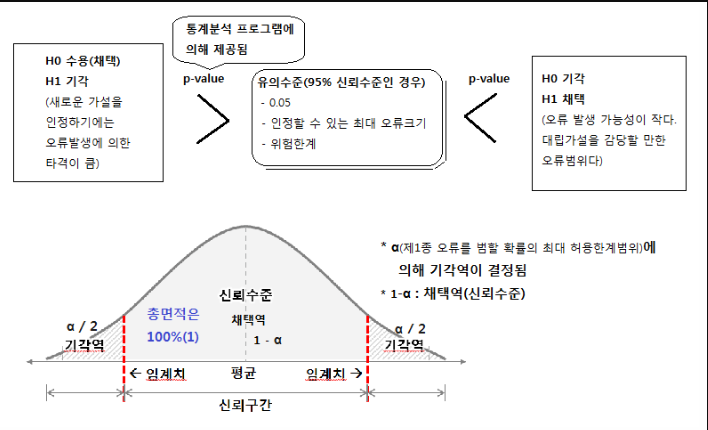
우리 R 환경에서는 귀무가설은 통상적인 이념이 아닌 “차이가 없다, 영향력이 없다, 연관성이 없다, 효과가 없다”로 생각하자.
참조: 꼬깔콘의 분석일지 블로그
표본추출 방법
- 단순임의추출: 임의로 추출
- 계통추출: 표본 원소에 번호를 부여한 후 표본의 크기 K값 정함 => 난수표를 이용하여 K-1의 숫자중 하나를 선택하고 그 숫자에 K만큼 더해가며 개체를 선택
- 층화추출: 그룹의 차이가 존재하는 그룹으로 나눈뒤 그룹에서 선택
- 군집추출: 그룹간의 차이가 없는 그룹으로 나눈뒤 그룹에서 선택
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#표본추출 방법 3가지
#단순임의추출:복원,비복원
base::sample(1:10,5) #(모집단,표본집단), 비복원추출(default)
sample(1:10,5,replace = TRUE) #복원추출:중복자료 추출가능
sample(1:10,5,replace = TRUE,prob = 1:10) #prob:가중치부여(가중치 부여한 수의 출현빈도高)
#층화임의추출
install.packages("sampling")
library(sampling)
aa<-sampling::strata(c('Species'),size=c(3,3,3),method = 'srswor',data=iris)
#'srswr'외에도 possion,systematic등이 있다. 검색을 통해 알아보기.
aa
sampling::getdata(iris,aa)
#계통추출:단계를 주면서 작업할때
install.packages("doBy")
library(doBy)
(x<-data.frame(x=1:10))
doBy::sampleBy(~1,frac = .3,data=x,systematic = TRUE) #
sampleBy(~Species,frac = 0.1,data=iris)
sampleBy(~Species,frac = 0.1,data=iris,replace = FALSE,systematic = T)
참조: 원본코드
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment