
YOLO9000(Concept)
YOLO9000
논문 참조: YOLO9000:Better, Faster, Stronger

(1) Introduction
YOLO9000의 결과부터 살펴보면 다음과 같다.

해당 논문에서 가장 처음으로 이야기 하는 것은 모든 Object Detection Algorithm의 공통된 사항이다.
General purpose object detection should be fast, accurate, and able to recognize a wide variety of objects.
3가지의 큰 틀로서 Object Detection에 관하여 이야기 하고 있다.
- Fast, 2. Accurate, 3. recognize a wide variety of objects
현재 YOLO9000: Better, Faster, Stronger에 제목에 맞춰서 생각하면 위의 각각의 3가지의 큰 틀에 맞춰서 전체적으로 향상된 기법이라고 얘기할 수 있다.
특히 향상된 분야는 제목에서도 알 수 있듯이 9000개 이상의 카테고리를 분류할 수 있는 Stronger에서 매우 뛰어난 성능을 보여주는 Model이라는 것 이다.
이러한 Model에 관하여 해당 논문은 다음과 같이 설명하고 있다.
Using this method we train YOLO9000, a real-time object detector that can detect over 9000 different object categories.
First we improve upon the base YOLO detection system to produce YOLOv2, a state-of-the-art, real-time detector.
Then we use our dataset combination method and joint training algorithm to train a model on more than 9000 classes from ImageNet as well as detection data from COCO.
YOLO9000을 만들기 위한 가장 중요한 방법 2가지(Stronger)에 대해서 얘기하고 있다.
- we use our dataset combination method
- joint training algorithm to train a model on more than 9000 classes from ImageNet as well as detection data from COCO
CycleGAN과 같이 Dataset 구축에는 많은 시간과 자원이 할당됨으로서 구축하기 어렵다는 것을 언급하고 있다.
따라서 기존에 가지고 있는 Dataset을 가지고 Combination Method를 거친 뒤, Joint Training을 사용하여 Model을 학습시킨다고 나와있다.
각각의 과정을 논문의 제목대로 Better,Faster,Stronger순으로 알아보도록 하자.
(2) Better
YOLO suffers from a variety of shortcomings relative to state-of-the-art detection systems.
Error analysis of YOLO compared to Fast R-CNN shows that YOLO makes a significant number of localization errors.
…
However, with YOLOv2 we want a more accurate detector that is still fast.
Instead of scaling up our network, we simplify the network and then make the representation easier to learn.
위의 내용이 Better를 향상시키기 위한 목적이다.
기존 YOLO보다 Model의 성능을 향상시키기 위하여 Localization Error를 줄이도록 노력하였다는 것 이다.
하지만 다른 CNN의 추세와는 달리 Object Detection의 성능에는 Fast도 포함되어있으므로, Model을 Scaling up하는 방식이 아닌 쉽게 Learn할 수 있는 방향으로 바꾸어서 Model의 성능을 향상시켰다고 얘기하고 있다.

위의 결과가 YOLOv1에 비교하여 YOLO9000에서 Accurate를 증가시키기 위하여 사용한 방법들이고 각각의 방법을 적용함에 따라서 mAP가 63.4 -> 78.6 으로서 증가한 것을 확인할 수 있다.
각각의 방법에 대하여 하나씩 알아보자.
1) Batch Normalization
Batch Normalization을 통하여 Regularization을 하였다. 이러한 결과로서 mAP에서 2%정도 향상을 보였다고 한다. 또한 이러한 Batch Normalization을 통하여 Dropout을 제거하여도 Overfitting이 발생하지 않았다고 한다.
2) High Resolution Classifier
YOLO v1을 살펴보게 되면 Model을 224x224로서 Training하고 Object Detection의 경우 448x448로서 Input으로 넣을 것을 확인할 수 있다.
YOLO v2는 224x224 Input을 가지는 Model에 미리 10번정도 448x448 ImageNet Dataset으로서 FineTuning을 실시하게 된다. -> 이러한 결과로 인하여 미리 고해상도 이미지에 대한 좀 더 좋은 성능을 보여준다고 한다.
3) Convolutional With Anchor Boxes
YOLOv1에서는 FC Layer를 통하여 나온 Feature map을 7x7x30의 Tensor로서 바꾼다음에 Object Detection을 사용하였다.
하지만 YOLO9000에서는 다음과 같은 과정을 거친다고 한다.
- FC Layer는 제거하고 Convolution을 사용하게 된다.
- Network의 입력 이미지는 448x448 -> 416x416으로 축소시킨다. 최종적인 Feature Map의 크기를 13x13 즉, 홀수로 맞추기 위해서 이다. 홀수의 장점은 정확한 Center를 구할 수 있다는 것이다. Object가 특히 큰 경우 중앙에 위치하는 경우가 많기 때문에 이를 위해서 network의 Input Image의 Size를 변경시켰다고 한다.(짝수인 경우 4x4에서 Cell을 선택하거나 전부 선택하여야 한다. 즉, 주변 Cell까지 영향을 미치게 된다.)
- Anchor Box를 사용한다. Faster R-CNN이나, SSD와 같이 Localization Loss를 줄이기 위하여 사용한 것 이다.
위와 같은 결과로서 mAP는 0.3%감소 되었지만, Recall같은 경우 81% -> 88%로서 상승하였다고 한다.
Introduction에서 이야기한 YOLOv1의 Localization의 단점을 이러한 방식으로서 해결하였다.
참조(mAP(Precision), Recall)
mAP와 Recall은 둘다 Confusion Matrix를 통하여 구하게 된다.
사진 참조: better-today 블로그

위와 같은 Confusion Matrix가 있을 경우
Precision 식
$$Precision = \frac{TP}{TP+FP} = \frac{\text{Model이 True라고 예측한 것 중 실제 True인 것}}{\text{Model이 True라고 예측한 것}}$$
AP(Average Precision): Precision값들의 Average
mAP(mean Average Precision)이란 1개의 object당 1개의 AP값을 구하고, 여러 object-detector에 대해서 mean값을 취한 것 이다.
Recall 식
$$Recall = \frac{TP}{TP+FN} = \frac{\text{Model이 True라고 예측한 것 중 실제 True인 것}}{\text{실제 True인 모든 Data}}$$
참조: better-today 블로그
4) Dimension Clusters
1~3까지의 방법은 기존의 Model에서 사용하는 방법이거나 SSD와 차이가 없었다.
개인적으로 YOLO9000에서 중요한 한 부분이라고 생각한다.
먼저 Dimension Clusters에 대하여 그림으로 살펴보면 다음과 같다.
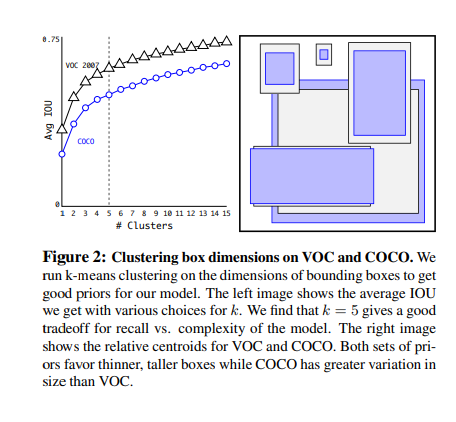
위의 사진과 같이 다양한 Anchor Box를 생성하는데에 있어서 SSD와 같이 일정 Size로서 Anchor Box를 지정하는 것이 아니라 K-means를 사용하여 Model에 적합한 Anchor Box를 생성한다.
중요한 것은 Euclidian 거리 공식을 사용하여 K-Means를 구현하게 되면 Box의 Size에 따라서 값이 달라지게 되므로 다음과 같은 공식으로서 거리를 계산하고 K-Means기법을 사용하였다.
$$d(box,centroid) = 1 - IOU(box,centroid)$$
K-Means Cluster를 사용하여 Anchor Box를 구성하였을 경우와 다른 방법을 사용하였을 때의 성능을 비교한 지표를 살펴보면 다음과 같다.
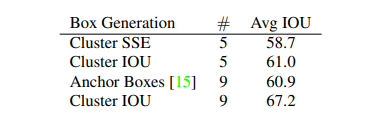
위의 사진에서 살표볼 수 있듯이 일반적인 정의한 Anchor Box 9개를 사용한 것보다 K-Means Cluster를 사용하여 5개의 Anchor Box를 사용한 것이 좀 더 IOU가 좋은 것을 알 수 있다.
해당 논문에서는 이러한 K=5로서 고정하고 사용하였다.
K의 개수를 늘릴수록 Avg IOU의 성능은 좋아지나 Model의 Complexity가 증가하기 때문에 5라고 정의하고 Anchro Box를 생성하였다.(이러한 상반되는 상황을 Trade-Off라고 칭한다.)
참고사항(K-means, IOU)
각각의 방법에 대해서 보르면 아래 링크를 참조하자.
5) Direct location prediction
위에서 K=5로서 사용하여 5개의 Anchor Box를 설정하였다.
이제 이러한 Anchor Box를 활용하여 Image안의 실제 Object의 Localization을 추축하여야 한다.
먼저 사용할 Parameter를 알아보면 다음과 같다.
- \(c_x,c_y\): 각 Grid Cell의 좌상단 끝 offset
- \(p_w,p_h\): Prior Anchor Box의 Width, Height. 즉, 5개의 Anchor Box중에서 가장 IOU가 높은 Anchor Box의 Width, Height.
- \(b_x,b_y,b_w,b_h\): 실제 Label Data의 Bounding Box 정보
- \(t_x,t_y,t_w,t_h\): Model이 예측한 Bounding Box 정보
- \(\sigma\): Sigmoid 함수
$$b_x = \sigma(t_x)+c_x$$
$$b_y = \sigma(t_y)+c_y$$
$$b_w = p_w e^{t_w}$$
$$b_h = p_h e^{t_h}$$
위의 식을 그림으로서 표현하면 아래와 같다.
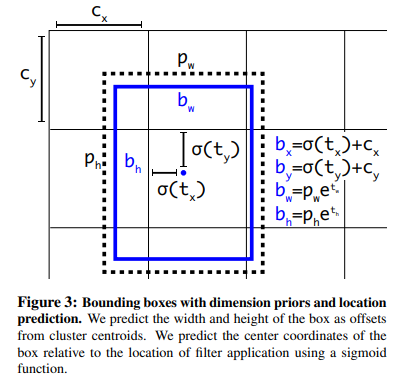
위의 식과 그림을 살펴보게 되면 각각의 목적은 보이게 된다.
$$b_x,b_y = \frac{1}{2}+c_x,c_y \rightarrow t_x,t_y = 0$$
$$b_w,b_h = p_w*1,p_h*1 \rightarrow t_w,t_h = 0$$
최종적으로 Model의 예측값이 모두 0으로서 수렴하도록 설계하여 좀 더 Stable하게 Model이 Training되고, 4,5번 기법을 통하여 약 5% 성능이 향상되었다고 한다.
6) Fine-Grained Features
Model의 최종적인 Featur Map의 Size는 13x13이다.
이러한 Featur Map은 큰 Size의 Object를 Detection하기는 충분하지만, 작은 Object를 Detection하는 데에는 적합하지 않다고 설명한다.
SSD와 마찬가지로 여러 Size의 Featur Map을 사용하기 위하여 ResNet과 같이 Skip Connection을 사용하였다.
즉, 13x13 FeatureMap의 전 26x26 FeaturMap을 13x13x4로서 변경(가운데 기준으로 2x2로서 나눔)하여 최종적으로는 13x13+13x13x4 = 13x13x5의 FeaturMap으로서 ObjectDetection을 수행하였다.
논문에서는 이러한 Layer를 passthrough layer로서 표현한다.
Model의 성능은 1%상승하였다고 한다.
7) Multi-Scale Training
Model을 Robust 즉, 다양한 Size의 Input으로부터 결과를 좋게 하기 위하여 10의 Batch마다 {320,352,…,608}로서 Input Image를 Resize하여 학습을 진행하였다고 한다.
이러한 결과로서 다음과 같은 지표를 공개하였다.
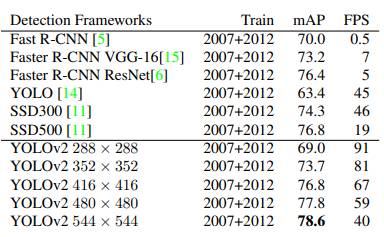
(3) Faster
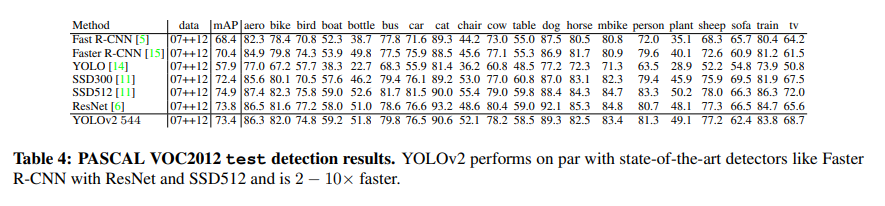
VOC2012기준으로서 20개의 Class를 분류하는 데 있으서 SSD300과 SSD512중간의 Accuracy를 보여주면서 속도는 2~10배 정도 빨라졌다고 한다.
1) Darknet-19
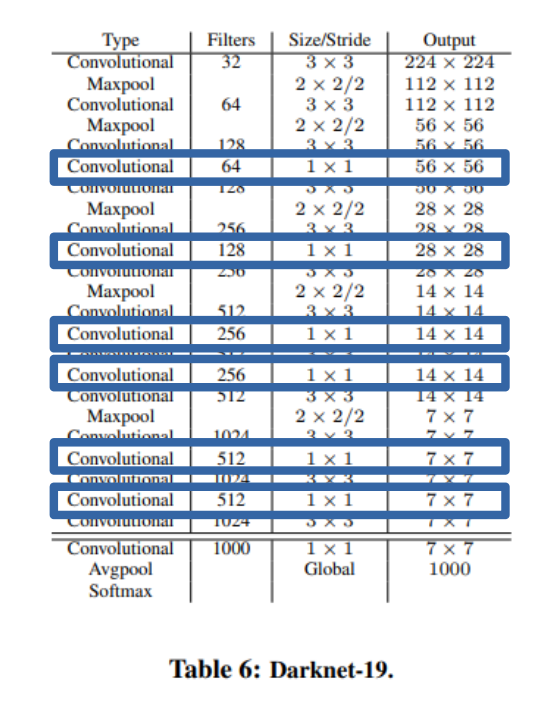
YOLOv1, SSD는 VGG Model을 Customizing하여 사용하였다.
YOLO9000은 위의 사진과 같이 독자적인 DarkNet을 Model로서 사용하였다. 중요한 점은 사진에 표시한것과 같이 3x3 Convolution사이에 1x1 Convolution을 사용하여 Feature representation을 Compress했다는 것 이다.
이러한 결과를 VGG16과 비교하면 다음과 같다.
- 30.69 billion operations -> 5.58 billion operations로서 감소
- 92.7% top-5 test accuracy in ImageNet -> 91.2% top-5 accuracy on ImageNet 으로서 Accuracy는 비슷하다.
2) Training for classification
DarkNet을 Image Classification을 위하여 Training하는 방법이다.
각각의 Hyperparameter Setting은 다음과 같다.
- starting learning rate of 0.1
- polynomial rate decay with a power of 4
- weight decay of 0.0005
- momentum of 0.9
- Optimizer: SGD
- Data Augmentation: Random crop, Shift, Rotation…
처음에는 224x224로서 FinTuning하고 448x448의 고해상도 Image로서 Fine Training을 진행하게 된다.
SSD와 마찬가지로 Learning Rate를 점점 줄여가며서 Training을 진행하게 되고 최종적인 결과로서는 top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%성능을 보였다고 한다.
3) Training for detection
Detection을 위한 Network의 구조변경은 다음과 같다.
- 기존의 DarkNet의 구조에서 뒤의 1개의 Layer(1x1x1000)를 제거한다.
- 3x3x1024 Convolutional Layer를 추가한다.
- 1x1x125(5(Anchor Box)*(5(Coordinate)+20(Class)))를 추가한다.
- 2-6) Fine-Grained Features의 passthrough의 작업을 실시한다.
다음과 같은 구조에서 각각의 Hyperparameter Setting은 다음과 같이 변경하였다.
- Epoch: 160
- starting learning rate of 0.001
- dividing learning rate by 10 at 60 and 90 epochs
- weight decay of 0.0005
- momentum of 0.9
- Data Augmentation: Random crop, Shift, Rotation…
(4) Stronger
Introduction에서 Stronger에 대해 말한 것을 다시 한번 살펴보면 다음과 같다.
- we use our dataset combination method
- joint training algorithm to train a model on more than 9000 classes from ImageNet as well as detection data from COCO
위와 같은 방식에 대해서 자세히 설명하는 부분이다.
During training we mix images from both detection and classification datasets.
When our network sees an image labelled for detection we can backpropagate based on the full YOLOv2 loss function.
When it sees a classification image we only backpropagate loss from the classificationspecific parts of the architecture.
…
Detection datasets have only common objects and general labels, like “dog” or “boat”. Classification datasets have a much wider and deeper range of labels.
ImageNet has more than a hundred breeds of dog, including “Norfolk terrier”, “Yorkshire terrier”, and “Bedlington terrier”. If we want to train on both datasets we need a coherent way to merge these labels.
…
This presents problems for combining datasets, for example you would not want to combine ImageNet and COCO using this model because the classes “Norfolk terrier” and “dog” are not mutually exclusive.
YOLO9000의 핵심인 부분이여서 정확한 내용을 전달하기 위하여 논문 그대로의 설명을 많이 가져왔다.
하나씩 살펴보면 다음과 같다.
- Dataset을 구축하기 위하여 ImageNet Datset + Detection Dataset으로서 Dataset을 구축하였다.
- 문제가 되는 것은 “Norfolk terrier”(ImageNet Dataset) and “dog”(Detection Dataset)은 mutually exclusive하지 않으므로 Dataset을 무작정 합치면 안된다.(we use our dataset combination method)
- Detection Dataset이 들어오게 되면 Model에서 Detection관련된 부분의 Weight를 Update하기 위하여 Backpropagation을 수행하게 되고, Classification Dataset이 들어오게 되면 Model에서 Classification관련되 부분의 Weight를 Update한다.(joint training algorithm)
이러한 Stronger Model을 만들기 위하여 YOLO9000이 제시한 방법에 대해서 알아보자.
1) Hierarchical classification
위에서 2번에 관한 설명이다. 현재 Detection에 관련된 Dataset과 Classification에 대한 Dataset을 합칠 때 mutally exclusive하지 단순히 합치면 안되는 것 이다.
이러한 해결방법으로서 Paper는 WordNet구조로서 Label을 공통적으로 묶는 작업을 실시하였다.
이러하 과정에서 특정 Root단어부터 연관되는 단어들을 이어가면서 Hierarchical classification구조를 갖추게 되었고 Label의 개수가 1000개에서 1369개로 늘어났다.
또한 Label Data는 단순한 1개의 Label을 가지는 것이 아니라 유사한 관련있는 즉, Root까지의 Label을 모두 가지게 된다.
이러한 Tree구조를 가지고 있을 때 Node의 Classification을 하기 위해서는 Bayes’ theorem를 통하여 계산을 하게 된다.
예를 들면 다음과 같다.
Terrier안에 수많은 Node가 있다고 가정하면 각각의 Node의 확률은 다음과 같이 정의될 수 있다.
$$Pr(Norfolk terrier|terrir)$$
$$Pr(Yorkshire terrier|terrir)$$
$$Pr(Bedlington terrier|terrir)$$
만약, \(Pr(physical object)=1\)이라 가정하면 Norfolk terrir에 대한 확률은 Bayes’ theorem을 통하여 다음과 같이 나타낼 수 있다.
$$ Pr(Norfolk terrier) = Pr(Norfolk terrier|terrir)$$
$$*Pr(terrir|huntingdog)$$
$$*...*$$
$$*Pr(mammal|animal)$$
$$*Pr(animal|physical object)$$
위와 같은 식에서 볼 수 있듯이 해당 Nodel의 Label이 Norfolk terrier이라면 Norfolk terrier, terrier … physical object까지 모두 Update가 되는 것을 확인할 수 있다.
이러한 과정을 통하여 왜 Label의 개수가 1000개에서 1369개로 늘어났는지 확인할 수 있다.
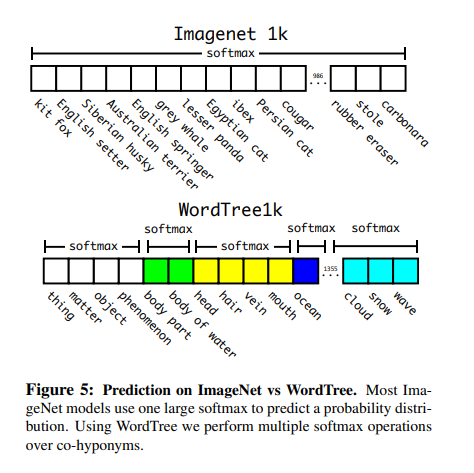
또한 위의 사진에서도 알 수 있듯이, Probability를 계산하는 경우 구성된 WordTree에서 같은 Level에 있는 기준으로 Softmax를 실시하게 되어서 Length가 다른것을 확인할 수 있다.
참고사항(WordNet, Bayes’ theorem)
위의 설명에서 WordNet과 수식에서 사용한 Bayes’ theorem이 이해되지 않으면 아래 링크를 참조하자.
2) Dataset combination with WordTree
위와 같은 과정의 WordNet을 구성하기 위하여 COCO Dataset과 ImageNet을 합치게 되었고 최종적으로 구성된 WordTree는 아래 사진과 같이 구성된다.
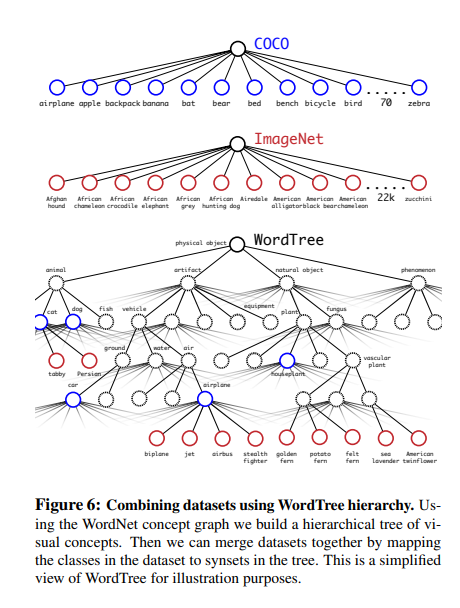
3) Joint classification and detection
- WordTree를 구성하는 단계에서 Detection Dataset(COCO Dataset)이 Classification Dataset(ImageNet Dataset)에 비해 적기 때문에 4:1 비율로서 맞추고자 COCO Dataset을 Oversampling하였다.
- 5개의 AnchorBox를 사용하기에는 Output Size가 맞지 않아서 3개의 Prior AnchorBox를 사용하였다.
- Detection Dataset을 Input으로 받을경우 BackPropagation을 진행하게 된다.(단, IOU가 0.3이상일 경우에만)
- Classification Dataset을 Input으로 받을 경우 Classification에 관해 Backpropagation을 진행한다. 즉, Dog를 입력받은 경우 Dog -> HuntingDog -> terrir와 같이 아래 Node까지 Error가 전파 될 수 있도록 구성한다. 단, 마지막 단 즉, 자식 Node가 없는 경우 자기 자신에게만 부여한다.
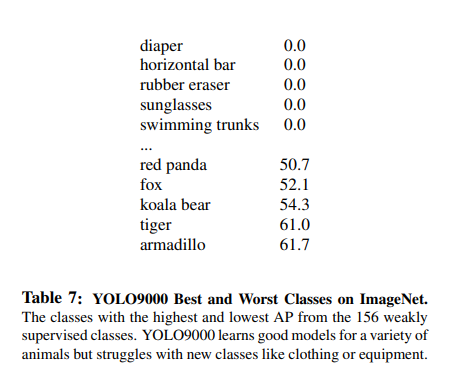
위와 같은 과정으로서 Model을 Training하였을 경우, 19.7mAP의 수치를 보여주었고, Training되지 않은 Object에 관하여서는 16.06mAP의 성능을 보여주었다.
(5) Conclusion
19.7mAP라는 낮은 성능을 보여주었지만(다른 Object Detection 기법보다는 높은 수치) 9000개 이상의 Category를 분류할 수 있는 Stronger한 Model의 시발점이 될 수 있는 기법이라고 생각한다.
또한 COCODataset의 한계로서 Bounding Box Label이 잘 구축되어있는 동물 분류는 잘 하는반면, 의류나 장비쪽에서는 많이 부족한 것을 보여주고 있다.
참조: YOLO9000:Better, Faster, Stronger
참조: Taeu 블로그
참조: better-today 블로그
참조: sogangori 블로그
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment