
YOLOv3(Concept)
YOLOv3
논문 참조: YOLOv3: An Incremental Improvement
1) Introduction
YOLOv3는 성능을 향상시켰다고 한다. 성능을 살펴보면 다음과 같다.
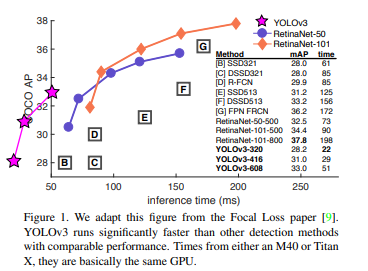
YOLOv1이나 YOLO9000처럼 새로운 기법으로서 Object Detection을 구성하고 성능을 향상시킨 것이 아니라 기존에 있는 기법들을 YOLO9000에 적용하여 더 성능을 향상시켰다고 한다.
결과적으로 YOLO9000보다 FPS 즉, 처리 속도는 조금 느려졌지만 다른 기법들보다 여전히 빠르고 YOLO9000에서의 취야점이던 많은 Category에 대한 mAP를 올리는데 집중한 새로운 YOLO 기법이다.
2) The Deal
실질적으로 다른 기법에서 YOLOv3에 적용한 새로운 방법들에 대해서 소개해주는 Section이다. 많은 부분이 바뀐것이 아니라, 기존의 YOLO9000에서 조금씩만 변형하였다.
2.1) Bounding Box Prediction
기존 YOLO9000에서 사용한 방식에 대해서 생각하면 다음과 같다.
- \(c_x,c_y\): 각 Grid Cell의 좌상단 끝 offset
- \(p_w,p_h\): Prior Anchor Box의 Width, Height. 즉, 5개의 Anchor Box중에서 가장 IOU가 높은 Anchor Box의 Width, Height.
- \(b_x,b_y,b_w,b_h\): 실제 Label Data의 Bounding Box 정보
- \(t_x,t_y,t_w,t_h\): Model이 예측한 Bounding Box 정보
- \(\sigma\): Sigmoid 함수
$$b_x = \sigma(t_x)+c_x$$
$$b_y = \sigma(t_y)+c_y$$
$$b_w = p_w e^{t_w}$$
$$b_h = p_h e^{t_h}$$
위의 식을 그림으로서 표현하면 아래와 같다.
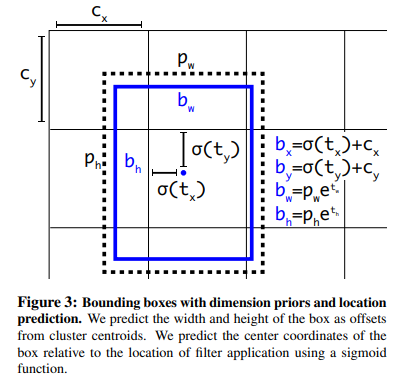
위의 식과 그림을 살펴보게 되면 각각의 목적은 보이게 된다.
$$b_x,b_y = \frac{1}{2}+c_x,c_y \rightarrow t_x,t_y = 0$$
$$b_w,b_h = p_w*1,p_h*1 \rightarrow t_w,t_h = 0$$
위의 수식 그대로에서 차이점을 살펴보면 LossFunction과 IOU에 있어서 나타나게 된다.
LossFunction
LossFUnction을 살펴보게 되면 다음과 같다.
- YOLO9000: L2 Loss사용(MSE)
- YOLOv3: L1 Loss사용
위의 식에서 \(t_x,t_y\)에 대해 살펴보면 다음과 같다.
$$t_x = \sigma(b_x-c_x)^{-1}, t_y = \sigma(b_y-c_y)^{-1}$$
위의 식을 각각 L1, L2 Loss에 적용하면 다음과 같다.
L1 Loss: \(\hat{t_x}-t_x = \hat{t_x}-\sigma(b_x-c_x)^{-1}\)
L2 Loss: \((\hat{t_x}-t_x)^2 = (\hat{t_x}-\sigma(b_x-c_x)^{-1})^2\)
즉, L2 loss를 사용하게 되면 logstic의 제곱꼴이 나오기 때문에 학습에 부정적인 영향을 미치기 때문에 logstic의 그대로를 사용하기 위하여 L1Loss를 사용하였다.
IOU
기존의 YOLO9000은 5개의 AnchorBox중에서 가장 IOU가 높은 하나의 Anchor Box만 사용하게 되었다.
이렇게 측정된 가장 높은 IOU의 값은 매우 낮은 값일 수 있다.
따라서 YOLOv3는 IOU가 0.5이상의 AnchorBox에 대해서 Positive Label을 부여하고 나머지는 무시하는 SSD 혹은 FastRCNN의 방식을 선택하였다.
2.2) Class Prediction
기존의 YOLO9000의 Class Prediction을 살펴보게 되면 다음과 같다.
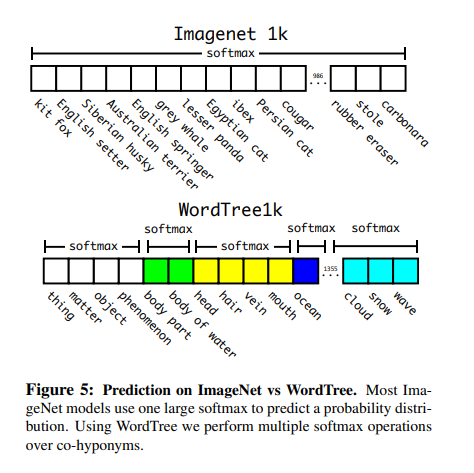
각각의 동일한 종류의 Label을 묶어서 Softmax로서 표현하였고, 이러한 Softmax의 Length는 서로 다른 길이를 가지게 되었다.
하지만, 역시 mutually exclusive문제로 인하여 Overlapping되는 문제가 많았다. 즉, 여자 사람 Image의 Class는 Softmax이므로 Person과 Woman에 값이 부여되게 되고 Woman을 원했으나 Person의 값이 더 높아지는 결과가 나타날 수 있다는 것 이다.
이러한 문제로 인하여 YOLOv3는 Independent logistic classifiers인 binary cross-entropy를 사용하게 된다.
2.3) Predictions Across Scales
기존 YOLO9000에서는 큰 Object를 Detection하기 위하여 13x13 FeatureMap에서 Detection 및 작은 Object를 Detection하기 위하여 26x26 -> 13x13x4로서 변경(passthrough)하여 Detection하였다.
YOLOv3에서는 SSD와 마찬가지로 다양한 Scale의 FeatureMap을 적용시켰다. 최종적인 결론을 말하자면 3개의 BoundingBox를 선택하게 되고, 이러한 BoundingBox는 3개의 Scale의 FeatureMap에서 이루워진다.
각각의 Scale은 2배차이게 되므로 최종적인 BoundingBox는 9개가 선정되고 이러한 BoundingBox는 K-means clustering를 통하여 결정된다.
각각의 FeatureMap의 Output은 YOLO9000과 동일하게 NxNx[3*(4+1+80)]이다.(만약 Class가 80개라면)
- 3: BoundingBox의 개수
- 4: x,y,w,h
- 1: 물체가 존재하는지 안하는지(Confidence)
- 80: Class의 개수
논문에서는 COCO dataset을 사용하였을 경우 9개의 Cluster의 Size는 다음과 같이 나왔다고 이야기 한다.
(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)
2.4) Feature Extractor
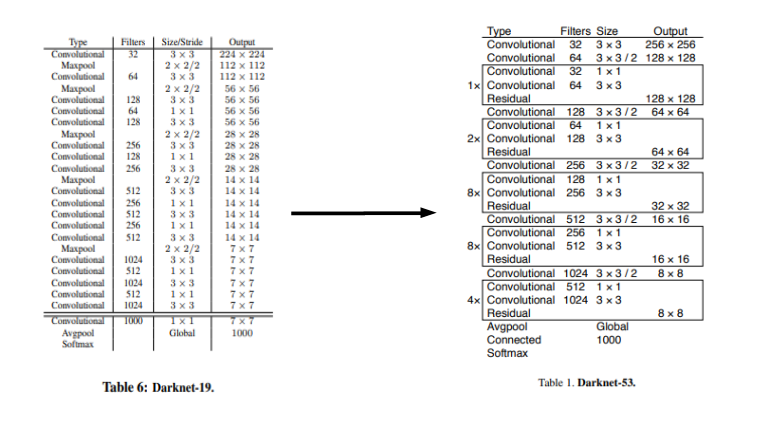
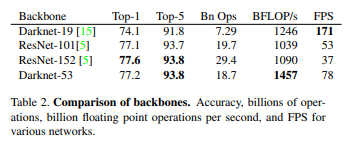
기존 YOLO9000에서 사용하던 Darknet-19가 아닌 Darknet-53을 사용하게 되고 Model의 성능을 높이기 위하여 좀 더 깊게 신경망을 구축하였다.
기존 Darknet-19에 비하여 당연히 FPS 즉, 속도는 떨어졌지만 YOLO9000의 문제인 낮은 mAP를 보안하기 위한 어쩔수 없는 선택이라고 생각된다. 당연하게도 Auucracy는 증가하게 되었다.
DarkNet-53 Network Architecture
DarkNet-53 Performance
2.5) Training
Training은 바뀐 부분이 없다. 중요한 점은 SSD와 다르게 hard negative mining을 실시하지 않았다는 것 이다. 즉, K-means로서 Anchor Box를 선택하는 것은 비교적 임의로 Anchor Box로서 범위를 설정하는 것 보다 성능이 좋아서 이러한 작업이 필요없다는 말과 동일하다.
Training에서 사용한 방법은 다음과 같다.
- no hard negative mining
- multi-scale training
- data augmentation
- batch normalization
3. How We Do
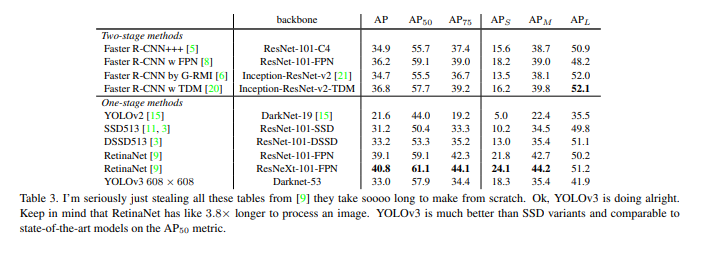
위의 ObjectDetection의 결과를 살펴보게되면 IOU를 기준으로서 YOLOv3의 장점과 단점에 대해서 설명하고 있다.
장점에 대해 설명하면 다음과 같다.
장점
- Fast
- AP50 즉, IOU가 0.5인 곳에서의 성능은 다른 Detection기법에 비하여 뒤떨어지지 않는다.
- APs 즉, Small Object Detection에 관해서 많은 향상을 보여주었다.
단점
- 여전히 RetainNet에 비하여 정확도는 떨어지는 것은 사실이다.
- AP, AP75에 관해서는 AP50보다 확실이 성능이 안나오는 것은 사실이다.
- 다양한 Scale에 FeatureMap을 생성하게 되어서 Medium, Large Object에 대한 Detection능력은 떨어졌다.
4. Things We Tried That Didn’t Work
YOLOv3을 만드는데 있어서 다양한 시도들을 하였으나, 실패하였던 기법들에 대하여 설명하고 있는 부분이다.
4.1) Anchor box x, y offset predictions
Linear activation을 사용하여 다양한 box의 x,y offset, width,height를 측정하려고 하였으나, 이러한 방식은 Model의 stability를 떨어트리고 잘 작동하지 않았습니다.
4.2) Linear x,y predictions instead of logistic
logistic (\(b_x = \sigma(t_x)+c_x, b_y = \sigma(t_y)+c_y\)에서 \(sigma()\))대신 Linear activation을 사용하여 Direct로 x,y의 offset값을 예측하려고 했지만 오히려 성능은 약화되었습니다.
4.3) Focal Loss
Focal Loss를 사용하였지만, 오히려 성능이 떨어졌다고 한다.
실질적으로 object prediction과 conditional class prediction을 분리하기 때문이라고 설명하고 있다.
즉, 물체가 존재할 확률을 구하고 일정 확률 이상에서만 그 물체의 class를 prediction하기 때문이라고 설명하고 있다.
하지만, Paper에서는 정확히 원인을 알 수 없다고 설명하고 있다. 즉, 추측이라는 얘기이다.
4.4) Dual IOU thresholds and truth assignment
현재 YOLOv3는 0.5 이상의 IOU의 값만 Positive example이라고 선언한다.
Dual IOU thresholds란 다음을 의미하게 된다.
0.3,0.7이라는 2개의 IOU thresholds를 선언하게 되면
- 0 ~ 0.3: Negative example
- 0.3 ~ 0.7: Ignore
- 0.7 ~ 1.0: Positive example
이러한 방식은 오히려 Model의 성능을 떨어뜨리게 되었고, 결과적으로 논문에서는 0.5이상의 값만 Positive example이라고 설정하는 방법이 local optima에 근사한 것처럼 꽤나 좋다고 생각한다.
참고사항(Focal Loss)
Focal Loss는 Focal Loss for Dense Object Detection에서 제시하는 방법이다.
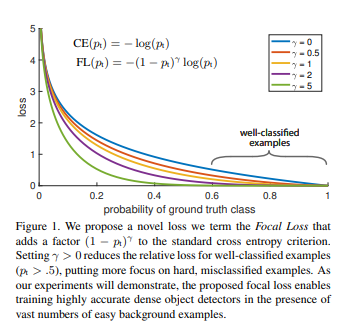
아직 정확히 Paper에 대해서 살펴보지 않아서 대략적으로 Concept에 대해서만 이야기하면 다음과 같다.
기본적으로 CrossEntropy에서 \((1-p_r)^{\gamma}\)의 weight를 부여한다.
중요한 점은 \((1-p_r)^{\gamma}\)로 인하여 값은 작게 될 것이다. 즉, 구분하기 어려운 Object에 관하여 Detection하는 경우 CrossEntropy를 사용하여 Backpropagation을 진행하게 되고, 분류하기 쉬운(BackGround가 대부분인) Object에 대해서는 Focal Loss를 사용하여 적은양을 Backpropagation을 실시한다는 것 이다.
자세한 내용에 대해서는 논문이 제시한 방안을 다시 살펴봐야 할 것 같다.
참조: YOLOv3: An Incremental Improvement
참조: Taeu 블로그
참조: dhhwang89 블로그
참조: 김홍배 Slide
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment