
Tensor
Tensor
Tensorflow 2.0에 맞게 다시 Tensorflow를 살펴볼 필요가 있다고 느껴져서 Tensorflow 정식 홈페이지에 나와있는 예제부터 전반적인 Tensorflow 사용법을 먼저 익히는 Post가 된다.
필요한 Library Import
1
2
3
4
5
from __future__ import absolute_import, division, print_function, unicode_literals
import math
import numpy as np
import tensorflow as tf
What is Tensor?
Tnesorflow란 이름에서 알 수 있듯이 Tensor를 포함한 계산을 정의하고 실행하는 Framework이다.
Tensor란 벡터와 행렬을 이차원한 것이고 고차원으로 확장 가능하다. 내부적으로 Tensorflow는 기본적으로 제공되는 자료형을 사용해 n-차원 배열로 나타낸다.
Tensorflow는 다음과 같은 속성을 가지고 있다.
- 자료형 ex) float32, int32, string, …
- 형태(shape)
Tensor안의 각각 원소는 동일한 자료형이다.
Tensor의 대표적인 종류는 다음과 같다.
- tf.Variable: Training으로서 Weight Update가 가능한 Tensor
- tf.constant: Training으로서 Weight Update가 불가능한 Tensor (Weight Update시 tape.watch() 필요)
- tf.SparseTensor: Sparse한 구조의 Tensor. Data의 대부분이 Sparse한 구조를 가지고 있기 때문에(Image 혹은 Lidar 형태의 Data인 경우) 지원한는 기능. Sparse하다는 것은 일반적으로 0(의미없는 데이터 ex) One-Hot-Encoding: Sparse, Embedding: Dense)을 많이 표현하고 있다고 생각하면 된다.
- tf.ragged.: 비정형 데이터를 다루기 위하여 variable-length 한 Tensor 형태
Rank
Tensor의 Rank란 Tensor의 Dimension을 의미하게 되고 각각의 랭크는 다음과 같은 의미를 가집니다.
| Rank | Math entity |
| 0 | Scalar(magnitude(값) only) |
| 1 | Vector(magnitude(값) and direction(방향)) |
| 2 | Matrix(table of numbers) |
| 3 | 3-Tensor(cube of numbers) |
| n | n-Tensor |
이러한 Tensor의 Rank는 tf.rank로서 확인 가능합니다.
다차원의 Tensor의 경우에는 Indexing을 통하여 접근 가능합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# Rank 0
mammal = tf.Variable("Elephant", tf.string)
ignition = tf.Variable(451, tf.int16)
floating = tf.Variable(3.14159265359, tf.float64)
its_complicated = tf.Variable(12.3 - 4.85j, tf.complex64)
print('Rank 0')
print('Rank of Rank 0 Tensor: ',tf.rank(mammal))
print('Value of Rank 0 Tensor: ',mammal.numpy(),ignition.numpy(),floating.numpy(),
its_complicated.numpy())
print()
# Rank 1
mystr = tf.Variable(["Hello"], tf.string)
cool_numbers = tf.Variable([3.14159, 2.71828], tf.float32)
first_primes = tf.Variable([2, 3, 5, 7, 11], tf.int32)
its_very_complicated = tf.Variable([12.3 - 4.85j, 7.5 - 6.23j], tf.complex64)
print('Rank 1')
print('Rank of Rank 1 Tensor: ',tf.rank(mystr))
print('Value of Rank 0 Tensor: ',mystr.numpy(),cool_numbers.numpy(),
first_primes.numpy(),its_very_complicated.numpy())
print()
# Higher Rank
mymat = tf.Variable([[7],[11]], tf.int16)
myxor = tf.Variable([[False, True],[True, False]], tf.bool)
linear_squares = tf.Variable([[4], [9], [16], [25]], tf.int32)
squarish_squares = tf.Variable([ [4, 9], [16, 25] ], tf.int32)
rank_of_squares = tf.rank(squarish_squares)
mymatC = tf.Variable([[7],[11]], tf.int32)
print('Higher Rank')
print('Rank of Higher Rank Tensor: ',tf.rank(mymat),tf.rank(myxor),
tf.rank(linear_squares),tf.rank(squarish_squares),tf.rank(rank_of_squares),
tf.rank(mymatC))
print('Value of Higher Rank Tensor: ',mymat.numpy(),myxor.numpy(),linear_squares.numpy(),
squarish_squares.numpy(),rank_of_squares.numpy(),mymatC.numpy())
print()
# Indexing
my_image = tf.zeros([2, 2, 2, 3])
print('Indexing')
print('Rank of Rank my_image Tensor: ',tf.rank(my_image))
print('Value of Rank my_image Tensor')
print(my_image.numpy())
for i,value in enumerate(my_image):
print('my_image Tensor index: {}, value: {}'.format(i,value.numpy()))
Rank 0
Rank of Rank 0 Tensor: tf.Tensor(0, shape=(), dtype=int32)
Value of Rank 0 Tensor: b'Elephant' 451 3.1415927 (12.3-4.85j)
Rank 1
Rank of Rank 1 Tensor: tf.Tensor(1, shape=(), dtype=int32)
Value of Rank 0 Tensor: [b'Hello'] [3.14159 2.71828] [ 2 3 5 7 11] [12.3-4.85j 7.5-6.23j]
Higher Rank
Rank of Higher Rank Tensor: tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32) tf.Tensor(0, shape=(), dtype=int32) tf.Tensor(2, shape=(), dtype=int32)
Value of Higher Rank Tensor: [[ 7]
[11]] [[False True]
[ True False]] [[ 4]
[ 9]
[16]
[25]] [[ 4 9]
[16 25]] 2 [[ 7]
[11]]
Indexing
Rank of Rank my_image Tensor: tf.Tensor(4, shape=(), dtype=int32)
Value of Rank my_image Tensor
[[[[0. 0. 0.]
[0. 0. 0.]]
[[0. 0. 0.]
[0. 0. 0.]]]
[[[0. 0. 0.]
[0. 0. 0.]]
[[0. 0. 0.]
[0. 0. 0.]]]]
my_image Tensor index: 0, value: [[[0. 0. 0.]
[0. 0. 0.]]
[[0. 0. 0.]
[0. 0. 0.]]]
my_image Tensor index: 1, value: [[[0. 0. 0.]
[0. 0. 0.]]
[[0. 0. 0.]
[0. 0. 0.]]]
Shape
Shape란 Tensor에서 각각의 Dimension을 의미하게 된다.
이러한 Shape는 특정한 값으로서 선언하거나 None으로서 자동으로 생성 가능하게 지정할 수 있다.
각각의 Rank와 Shape는 다음과 같다.
| Rank | Shape | Dimension number | Example |
| 0 | [] | 0-D | A 0-D tensor. A scalar |
| 1 | [D0] | 1-D | A 1-D tensor. tensor with shape[5] |
| 2 | [D0, D1] | 0-D | A 2-D tensor. tensor with shape[3,4] |
| 3 | [D0, D1, D2] | 3-D | A 3-D tensor. tensor with shape[1,4,3] |
| n | [D0, D1, ..., Dn-1] | n-D | A n-D tensor. tensor with shape[D0,D1, ...,Dn-1] |
위와같은 Tensor의 Shape는 .shape()로서 접근 가능하고 Indexing이 가능하다.
또한 tf.reshape를 통하여 Tensor의 Shape가 변경 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Rank 1 Tensor
zeros_1 = tf.zeros(shape=[5])
print(zeros_1.shape)
# Rank 2 Tensor
zeros_2 = tf.zeros(shape=[3,4])
print(zeros_2.shape)
# Shape Indexing
zeros_i = tf.zeros_like(zeros_2[1])
print('zeros_i value: ',zeros_i.numpy())
print('zeros_i shape: ',zeros_i.shape)
# Reshape
zeros_re = tf.reshape(zeros_2,[4,3])
print('Original shape=(3,4) Tensor')
print(zeros_2.numpy())
print('Change shape=(4,3) Tensor')
print(zeros_re.numpy())
(5,)
(3, 4)
zeros_i value: [0. 0. 0. 0.]
zeros_i shape: (4,)
Original shape=(3,4) Tensor
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
Change shape=(4,3) Tensor
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
자료형
Tensor는 2가지 속성을 가지고 있다고 설명하였다.
Shape와 자료형이다.
위에서 Shape는 살펴보았으니 자료형에 대해서 알아보자.
기본적으로 Tensor는 한 개이상의 자료형을 가지는 것은 불가능하다.(임의의 데이터 구조를 직렬화한 string 제외)
tf.Dtypeor.dtype: Tensor 자료형 확인tf.cast: Tensor 자료형 변경
Tensorflow에서 지원하는 자료형은 다음과 같다.
자료형 |
상세 |
|---|---|
tensorflow.int8 |
8비트 정수 |
tensorflow.int16 |
16비트 정수 |
tensorflow.int32 |
32비트 정수 |
tensorflow.int64 |
64비트 정수 |
tensorflow.uint8 |
8비트 0을 포함한 자연수 |
tensorflow.string |
문자열 |
tensorflow.bool |
부울린값(True,False) |
tensorflow.complex64 |
복소수 |
tensorflow.qint8 |
양자화 명령어용 8비트 정수 |
tensorflow.qint32 |
양자화 명령어용 21비트 정수 |
tensorflow.quint8 |
양자화 명령어용 8비트 0을 포함한 자연수 |
tensorflow.float32 |
32비트 실수 |
tensorflow.float64 |
64비트 실수 |
1
2
3
4
5
6
7
8
9
# int 형 자료형 선언
tensor_int = tf.Variable(3,dtype=tf.int16)
print('tensor_int 값: ',tensor_int.numpy())
print('tensor_int 자료형: ',tensor_int.dtype)
# int -> float으로 DType변경
tensor_float = tf.cast(tensor_int,dtype=tf.float16)
print('tensor_float 값: ',tensor_float.numpy())
print('tensor_float 자료형: ',tf.DType(tensor_float))
tensor_int 값: 3
tensor_int 자료형: <dtype: ‘int16’>
tensor_float 값: 3.0
tensor_float 자료형: <dtype: ‘int32’>
Evaluate tensors
Graph를 생성하면 텐서에 할당된 값을 가져오는 계산이 가능하다.
Tensor를 계산하는 가장 간단한 방법은 Tensor.eval 메서드를 사용하는 것 이다.(Numpy값을 Return한다. => Tensor 1.x Version)
Tensorflow 2.0에서는 Eager Tensor가 생겼기 때문에 Tensor.eval이 아닌 바로 .numpy()로서 계산하고 값을 확인 가능하다. Tensor.eval사용시 Error가 발생하면서 .numpy()를 사용하라고 한다.
1
2
3
4
5
6
7
8
# Tensor 선언
constant = tf.constant([1,2,3])
# Graph 선언
tensor = constant * constant
# .numpy을 통하여 Tensor 계산 확인
print(tensor.numpy())
# Tensorflow 2.0이상인 경우 tensor.eval() Error
print(tensor.eval())
[1 4 9]
NotImplementedError: eval is not supported when eager execution is enabled, is .numpy() what you’re looking for?
Ragged tensors
비정형 Data를 다루기 위하여 Variable Length가 지원되는 Tensor(Tensor Array라고 생각하면 편하다.)이다.
이러한 Tensor는 tf.ragged.Tensor()로서 선언되고 tf.add(), tf.reduce_mean()와 같이 math operation 그리고 tf.concat(), tf.tile()와 같이 array operation외에 많은 기능이 제공된다.
tf.ragged.map_flat_values()를 사용하게 되면 RaggedTensor에 Fuctnio을 적용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# Ragged Tensor 선언
digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])
words = tf.ragged.constant([["So", "long"], ["thanks", "for", "all", "the", "fish"]])
# Math Operation 확인
print('Math Operation')
print(tf.add(digits, 3))
print(tf.reduce_mean(digits, axis=1))
print()
# Array Operation 확인
print('Array Operation')
print(tf.concat([digits, [[5, 3]]], axis=0))
print(tf.tile(digits, [1, 2]))
print(tf.strings.substr(words, 0, 2))
print()
# Indexing
print('Indexing')
print(digits[0])
# First two values in each row
print(digits[:, :2])
# Last two values in each row
print(digits[:, :-2])
print()
# tf.ragged.map_flat_values
print('Original')
print(digits)
print('Function: 2x+1')
times_two_plus_one = lambda x: x * 2 + 1
print('tf.ragged.map_flat_values() Result')
print(tf.ragged.map_flat_values(times_two_plus_one, digits))
Math Operation
<tf.RaggedTensor [[6, 4, 7, 4], [], [8, 12, 5], [9], []]>
tf.Tensor([2.25 nan 5.33333333 6. nan], shape=(5,), dtype=float64)
Array Operation
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], [], [5, 3]]>
<tf.RaggedTensor [[3, 1, 4, 1, 3, 1, 4, 1], [], [5, 9, 2, 5, 9, 2], [6, 6], []]>
<tf.RaggedTensor [[b'So', b'lo'], [b'th', b'fo', b'al', b'th', b'fi']]>
Indexing
tf.Tensor([3 1 4 1], shape=(4,), dtype=int32)
<tf.RaggedTensor [[3, 1], [], [5, 9], [6], []]>
<tf.RaggedTensor [[3, 1], [], [5], [], []]>
Original
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9, 2], [6], []]>
Function: 2x+1
tf.ragged.map_flat_values() Result
<tf.RaggedTensor [[7, 3, 9, 3], [], [11, 19, 5], [13], []]>
Construction a ragged tensor
1. tf.ragged.constant
RaggedTensor를 정의하는 가장 쉬운 방법이다. Python의 List와 같이 정의하면 된다.
참조: tf.ragged.constant 사용법
2. tf.RaggedTensor.from_value_rowids
Python의 List에 각각의 List의 원소와 그 원소의 Row를 아는 경우 사용하는 방법이다.
그림으로 나타내면 다음과 같다.
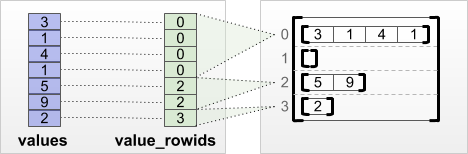
사진 참조: ragged tensor guide
3. tf.RaggedTensor.from_row_lengths
Python의 List에 각각의 List의 원소와 Row당 원소의 개수가 알 때 사용한다.
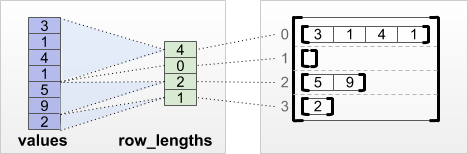
사진 참조: ragged tensor guide
4. tf.RaggedTensor.from_row_splits
Python의 List에 각각의 List의 원소와 각 Row의 시작 Index를 알 때 사용한다.
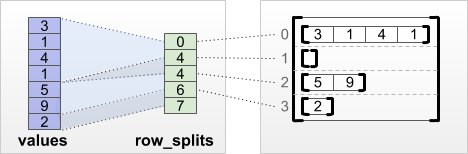
사진 참조: ragged tensor guide
참조: tf.ragged 사용법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# tf.ragged.constant
print(tf.ragged.constant([
[['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],
[['Do', 'you', 'want', 'to', 'come', 'visit'], ["I'm", 'free', 'tomorrow']],
]))
# tf.RaggedTensor.from_value_rowids
print(tf.RaggedTensor.from_value_rowids(
values=[3, 1, 4, 1, 5, 9, 2],
value_rowids=[0, 0, 0, 0, 2, 2, 3]))
# tf.RaggedTensor.from_row_lengths
print(tf.RaggedTensor.from_row_lengths(
values=[3, 1, 4, 1, 5, 9, 2],
row_lengths=[4, 0, 2, 1]))
# tf.RaggedTensor.from_row_splits
print(tf.RaggedTensor.from_row_splits(
values=[3, 1, 4, 1, 5, 9, 2],
row_splits=[0, 4, 4, 6, 7]))
<tf.RaggedTensor [[[b'I', b'have', b'a', b'cat'], [b'His', b'name', b'is', b'Mat']], [[b'Do', b'you', b'want', b'to', b'come', b'visit'], [b"I'm", b'free', b'tomorrow']]]>
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
<tf.RaggedTensor [[3, 1, 4, 1], [], [5, 9], [2]]>
what you can store in a ragged tensor
Tensor처럼 각각의 Element의 dtype은 일치하여야 하고 각 values의 depth(rank of tensor)가 일치하여야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# Type = String, rank = 2
tensor_s_2 = tf.ragged.constant([["Hi"], ["How", "are", "you"]])
print('tensor_s_2 value: ',tensor_s_2)
print('tensor_s_2 type: ',tensor_s_2.dtype)
print()
# Type = int32, rank = 3
tensor_i_3 = tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])
print('tensor_i_3 value: ',tensor_i_3)
print('tensor_i_3 type: ',tensor_i_3.dtype)
print()
# Multiple types
print('Multiple types exception')
try:
tf.ragged.constant([["one", "two"], [3, 4]])
except ValueError as exception:
print(exception)
print()
# Multiple nesting depths
print('Multiple nesting depths exception')
try:
tf.ragged.constant(["A", ["B", "C"]])
except ValueError as exception:
print(exception)
tensor_s_2 value: <tf.RaggedTensor [[b'Hi'], [b'How', b'are', b'you']]>
tensor_s_2 type: <dtype: 'string'>
tensor_i_3 value: <tf.RaggedTensor [[[1, 2], [3]], [[4, 5]]]>
tensor_i_3 type: <dtype: 'int32'>
Multiple types exception
Can't convert Python sequence with mixed types to Tensor.
Multiple nesting depths exception
all scalar values must have the same nesting depth
Example use cases
tf.ragged.constant가 사용되는 예시이다.
다음 과정은 Data의 전처리 과정으로서 Bigram과 Embedding을 통하여 단어를 Tensor로 바꾸는 과정이다. 전체적인 과정은 다음과 같다.
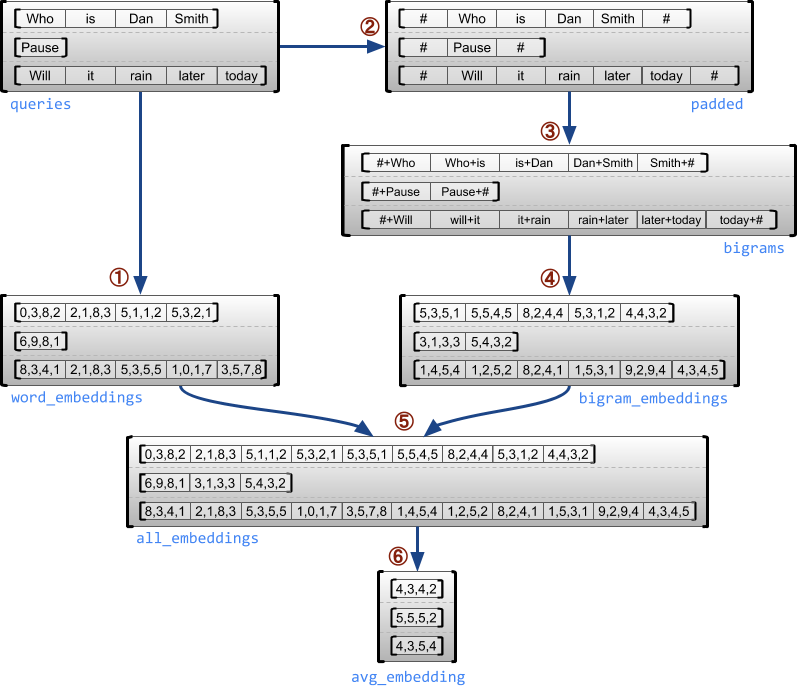
사진 참조: ragged tensor guide
Input tf.ragged.constant()가 어떻게 변하는지 상세하게 출력하였다.
아래 과정이 이해가 안되시면 다음 링크를 참조하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],
['Pause'],
['Who', 'is', 'Hwang', 'Jeong', 'Yong']])
# Create an embedding table.
num_buckets = 1024
embedding_size = 4
embedding_table = tf.Variable(
tf.random.truncated_normal([num_buckets, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
print('Embedding Table Value')
print(embedding_table)
print('Embedding Table Max Value',np.max(embedding_table.numpy()))
print('Embedding Table Min Value',np.min(embedding_table.numpy()))
print('Embedding Table Std Value',np.std(embedding_table.numpy()))
print()
# Look up the embedding for each word.
word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)
word_embeddings = tf.ragged.map_flat_values(
tf.nn.embedding_lookup, embedding_table, word_buckets)
print('Wrod Buckets')
for i,value in enumerate(word_buckets):
print('{} -> {}'.format(queries[i].numpy(), value.numpy()))
print()
print('Word Embedding')
for i,value in enumerate(word_embeddings):
print('{} -> '.format(word_buckets[i].numpy()))
print(value.numpy())
print()
# Add markers to the beginning and end of each sentence.
marker = tf.fill([queries.nrows(), 1], '#')
padded = tf.concat([marker, queries, marker], axis=1)
print('Padded')
for i,value in enumerate(padded):
print('{} -> {}'.format(queries[i].numpy(), value.numpy()))
print()
# Build word bigrams & look up embeddings.
bigrams = tf.strings.join([padded[:, :-1],
padded[:, 1:]],
separator='+')
print('Bigrams')
for i,value in enumerate(bigrams):
print('{} -> {}'.format(padded[i].numpy(), value.numpy()))
print()
print('Look up embeddings')
bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)
bigram_embeddings = tf.ragged.map_flat_values(
tf.nn.embedding_lookup, embedding_table, bigram_buckets)
for i,value in enumerate(bigram_embeddings):
print('{} ->'.format(bigrams[i].numpy()))
print(value.numpy())
print()
# Find the average embedding for each sentence
print('Average Embedding')
all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1)
avg_embedding = tf.reduce_mean(all_embeddings, axis=1)
print(avg_embedding)
Embedding Table Value
<tf.Variable 'Variable:0' shape=(1024, 4) dtype=float32, numpy=
array([[-0.26984987, 0.33821583, -0.25303894, 0.01355879],
[-0.31692794, 0.2507733 , -0.04176231, 0.47682792],
[ 0.138528 , 0.8105369 , -0.1459025 , -0.25926843],
...,
[ 0.03473174, 0.71605283, 0.3699363 , -0.00614554],
[ 0.01484714, -0.49983358, 0.4236563 , 0.83395946],
[ 0.29265305, -0.02712937, 0.13999745, 0.6439858 ]],
dtype=float32)>
Embedding Table Max Value 0.99935836
Embedding Table Min Value -0.9903946
Embedding Table Std Value 0.44566667
Wrod Buckets
[b'Who' b'is' b'Dan' b'Smith'] -> [633 768 237 309]
[b'Pause'] -> [28]
[b'Who' b'is' b'Hwang' b'Jeong' b'Yong'] -> [633 768 872 282 283]
Word Embedding
[633 768 237 309] ->
[[-0.20994134 -0.1857289 0.5846876 0.18298072]
[-0.32397014 0.77367496 0.09295609 -0.7025036 ]
[-0.44442365 -0.49605316 -0.23920043 0.35544553]
[-0.15591177 -0.9721323 -0.24233624 0.3026163 ]]
[28] ->
[[ 0.75021434 0.2933693 0.39557642 -0.45455787]]
[633 768 872 282 283] ->
[[-0.20994134 -0.1857289 0.5846876 0.18298072]
[-0.32397014 0.77367496 0.09295609 -0.7025036 ]
[ 0.42836288 0.22043757 0.5645658 -0.17434597]
[-0.0612235 -0.22269532 -0.05117381 -0.70351416]
[ 0.53572744 0.5649934 0.7251783 -0.05632596]]
Padded
[b'Who' b'is' b'Dan' b'Smith'] -> [b'#' b'Who' b'is' b'Dan' b'Smith' b'#']
[b'Pause'] -> [b'#' b'Pause' b'#']
[b'Who' b'is' b'Hwang' b'Jeong' b'Yong'] -> [b'#' b'Who' b'is' b'Hwang' b'Jeong' b'Yong' b'#']
Bigrams
[b'#' b'Who' b'is' b'Dan' b'Smith' b'#'] -> [b'#+Who' b'Who+is' b'is+Dan' b'Dan+Smith' b'Smith+#']
[b'#' b'Pause' b'#'] -> [b'#+Pause' b'Pause+#']
[b'#' b'Who' b'is' b'Hwang' b'Jeong' b'Yong' b'#'] -> [b'#+Who' b'Who+is' b'is+Hwang' b'Hwang+Jeong' b'Jeong+Yong' b'Yong+#']
Look up embeddings
[b'#+Who' b'Who+is' b'is+Dan' b'Dan+Smith' b'Smith+#'] ->
[[ 0.25747493 0.13615859 0.5341867 -0.85479945]
[-0.3306522 0.01117908 -0.69294995 -0.18351139]
[-0.83060795 -0.41425812 0.36051166 -0.9900611 ]
[-0.21996655 -0.48888227 -0.2747723 -0.05589481]
[-0.57145834 0.81615496 -0.31114626 -0.38524503]]
[b'#+Pause' b'Pause+#'] ->
[[ 0.60230803 0.13398379 -0.05554185 -0.285491 ]
[ 0.0515134 0.1544675 -0.6966816 0.15531673]]
[b'#+Who' b'Who+is' b'is+Hwang' b'Hwang+Jeong' b'Jeong+Yong' b'Yong+#'] ->
[[ 0.25747493 0.13615859 0.5341867 -0.85479945]
[-0.3306522 0.01117908 -0.69294995 -0.18351139]
[ 0.8724997 0.62738943 -0.35298598 0.21889828]
[-0.78824115 -0.7772786 0.30318534 -0.6767643 ]
[-0.18517442 0.42661405 0.27245098 -0.44607124]
[-0.22832447 0.99909246 0.52889496 -0.26612002]]
Average Embedding
tf.Tensor(
[[-0.3143841 -0.09109858 -0.02089591 -0.25899696]
[ 0.46801195 0.1939402 -0.11888235 -0.19491072]
[-0.00304202 0.23398517 0.22809054 -0.33291608]], shape=(3, 4), dtype=float32)
RaggedTensor shape
RaggedTensor의 Shape는 Tensor와 마찬가지 .shape()를 통하여 알 수 있다.
하지만 다음과 같은 Tensor가 정의되어있을때 shape를 생각해 보자.
tf.ragged.constant([["Hi"], ["How", "are", "you"]]).shape
위의 Code는 Shape가 (2,1) 이라고 표현해야 하는가 (2,3)이라고 표현해야 하는지 정할 수 없다.
따라서 Tensorflow의 결과는 (2,None)으로서 출력된다.
이러한 RaggedTensor 특성 때문에 .bounding_shape()를 사용하게 된다.
.bounding_shape()의 출력 형태를 보면 다음과 같다.
tf.Tensor([2 3], shape=(2,), dtype=int64)
- 2,3: 최대 Shape
- shape=(2,): 2차원 이나 나머지 차원은 다르다.
- dtype: DType
1
2
3
4
5
6
# Ragged Tensor 선언
r_tensor = tf.ragged.constant([["Hi"], ["How", "are", "you"]])
# .shape 사용
print(r_tensor.shape)
#. bounding_shape 사용
print(r_tensor.bounding_shape())
(2, None)
tf.Tensor([2 3], shape=(2,), dtype=int64)
Ragged vs sparse Tensor
이런 특이한 Raggend Tensor를 합치는 방법은 2가지가 있다.
tf.concat으로서 tf.Ragged.Tensor + tf.Ragged.Tensor = tf.Ragged.Tensor으로 나타애는 방법과

사진 참조: ragged tensor guide
tf.sparse.concat으로서 tf.SparseTensorCasting(tf.Ragged.Tensor) + tf.SparseTensorCasting(tf.Ragged.Tensor) = tf.Tensor로서 나타내는 방법이 존재한다.
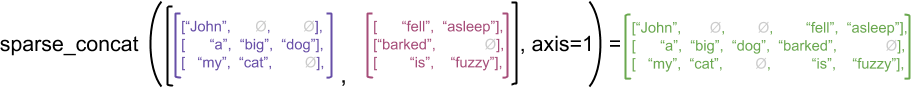
사진 참조: ragged tensor guide
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# ragged_concat
ragged_x = tf.ragged.constant([["John"], ["a", "big", "dog"], ["my", "cat"]])
ragged_y = tf.ragged.constant([["fell", "asleep"], ["barked"], ["is", "fuzzy"]])
print('ragged_concat')
print(tf.concat([ragged_x, ragged_y], axis=1))
print()
# sparse_concat
# Spaese Tensor로 변경
sparse_x = ragged_x.to_sparse()
sparse_y = ragged_y.to_sparse()
# sparse_concat수행
sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)
print('sparse_concat')
print(sparse_result)
print()
# spase -> dense 수행
print('saprse -> dense')
print(tf.sparse.to_dense(sparse_result, ''))
ragged_concat
<tf.RaggedTensor [[b'John', b'fell', b'asleep'], [b'a', b'big', b'dog', b'barked'], [b'my', b'cat', b'is', b'fuzzy']]>
sparse_concat
SparseTensor(indices=tf.Tensor(
[[0 0]
[0 3]
[0 4]
[1 0]
[1 1]
[1 2]
[1 3]
[2 0]
[2 1]
[2 3]
[2 4]], shape=(11, 2), dtype=int64), values=tf.Tensor(
[b'John' b'fell' b'asleep' b'a' b'big' b'dog' b'barked' b'my' b'cat' b'is'
b'fuzzy'], shape=(11,), dtype=string), dense_shape=tf.Tensor([3 5], shape=(2,), dtype=int64))
saprse -> dense
tf.Tensor(
[[b'John' b'' b'' b'fell' b'asleep']
[b'a' b'big' b'dog' b'barked' b'']
[b'my' b'cat' b'' b'is' b'fuzzy']], shape=(3, 5), dtype=string)
Overload operators
Ragged Tensor를 계산하기 위해서는 Ragged Tensor끼리는 shape가 동일하여야 하고 하나의 Element와 Ragged Tensor가 연산을 수행하게 되면 모든 Ragged Tensor의 Element와 하나의 Element의 연산을 수행(Broad Casting)하게 된다.
1
2
3
4
5
6
7
8
9
10
print('tf.ragged.constant + tf.ragged.constant')
x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])
y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])
print('x shape: ',x.shape)
print('y shape: ',x.shape)
print('x + y = : ',x+y)
print()
print('tf.ragged.constant + Element')
print(x + 3)
tf.ragged.constant + tf.ragged.constant
x shape: (3, None)
y shape: (3, None)
x + y = : <tf.RaggedTensor [[2, 3], [5], [7, 8, 9]]>
tf.ragged.constant + Element
<tf.RaggedTensor [[4, 5], [6], [7, 8, 9]]>
Indexing
Ragged Tensor또한 indexing이 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
queries = tf.ragged.constant(
[['Who', 'is', 'George', 'Washington'],
['What', 'is', 'the', 'weather', 'tomorrow'],
['Goodnight']])
print('queris[1] = ',queries[1])
# A single word
print('queris[1,2] = ',queries[1,2])
# Everything but the first row
print('queris[1:] = ',queries[1:])
# The first 3 words of each query
print('queris[:,:3] = ',queries[:,:3])
# The last 2 word of each query
print('queris[:,-2:] = ',queries[:,-2:])
queris[1] = tf.Tensor([b'What' b'is' b'the' b'weather' b'tomorrow'], shape=(5,), dtype=string)
queris[1,2] = tf.Tensor(b'the', shape=(), dtype=string)
queris[1:] = <tf.RaggedTensor [[b'What', b'is', b'the', b'weather', b'tomorrow'], [b'Goodnight']]>
queris[:,:3] = <tf.RaggedTensor [[b'Who', b'is', b'George'], [b'What', b'is', b'the'], [b'Goodnight']]>
queris[:,-2:] = <tf.RaggedTensor [[b'George', b'Washington'], [b'weather', b'tomorrow'], [b'Goodnight']]>
Tensor Type Conversion
Ragged Tensor -> Tensor or Tensor -> Ragged Tensor or Sparse Tensor -> Ragged Tensor 등 Raggend Tensor또한 다양한 Type Conversion이 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
ragged_sentences = tf.ragged.constant([
['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])
print('Ragged Tensor')
print(ragged_sentences)
print()
print('Ragged Tensor -> Tensor')
print('Tensor')
print(ragged_sentences.to_tensor(default_value=''))
print()
print('Ragged Tensor -> Sparse Tensor')
print('Sparse Tensor')
print(ragged_sentences.to_sparse())
print()
print()
print('Tensor -> Ragged Tensor')
x = tf.Variable([[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]])
print('Tensor')
print(x)
print('Ragged Tensor')
print(tf.RaggedTensor.from_tensor(x, padding=-1))
print()
print()
print('Sparse Tensor -> Ragged Tensor')
st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],
values=['a', 'b', 'c'],
dense_shape=[3, 3])
print('Sparse Tensor')
print(st)
print('Ragged Tensor')
print(print(tf.RaggedTensor.from_sparse(st)))
Ragged Tensor
<tf.RaggedTensor [[b'Hi'], [b'Welcome', b'to', b'the', b'fair'], [b'Have', b'fun']]>
Ragged Tensor -> Tensor
Tensor
tf.Tensor(
[[b'Hi' b'' b'' b'']
[b'Welcome' b'to' b'the' b'fair']
[b'Have' b'fun' b'' b'']], shape=(3, 4), dtype=string)
Ragged Tensor -> Sparse Tensor
Sparse Tensor
SparseTensor(indices=tf.Tensor(
[[0 0]
[1 0]
[1 1]
[1 2]
[1 3]
[2 0]
[2 1]], shape=(7, 2), dtype=int64), values=tf.Tensor([b'Hi' b'Welcome' b'to' b'the' b'fair' b'Have' b'fun'], shape=(7,), dtype=string), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
Tensor -> Ragged Tensor
Tensor
<tf.Variable 'Variable:0' shape=(3, 4) dtype=int32, numpy=
array([[ 1, 3, -1, -1],
[ 2, -1, -1, -1],
[ 4, 5, 8, 9]], dtype=int32)>
Ragged Tensor
<tf.RaggedTensor [[1, 3], [2], [4, 5, 8, 9]]>
Sparse Tensor -> Ragged Tensor
Sparse Tensor
SparseTensor(indices=tf.Tensor(
[[0 0]
[2 0]
[2 1]], shape=(3, 2), dtype=int64), values=tf.Tensor([b'a' b'b' b'c'], shape=(3,), dtype=string), dense_shape=tf.Tensor([3 3], shape=(2,), dtype=int64))
Ragged Tensor
<tf.RaggedTensor [[b'a'], [], [b'b', b'c']]>
None
Evaluation ragged tensors
Ragged Tensors를 Tensor의 List(집합) 이라고 표현하였다.
따라서 Ragged Tensor는 이전 Post Eager execution에서 다루었던 Eager Tensor처럼 .numpy()로서 바로 Value를 확인하지 못한다.
Ragged Tensors는 Tensor의 List이므로 .to_list()로서 Python List형태로서 바꾼다.
또한 Ragged Tensors의 각각의 Element들은 EagerTensor이므로 .numpy()로서 값이 확인 가능하다.
또한 위에서 언급하였던 Construction a ragged tensor처럼 Ragged Tensor를 나타내는 다양한 방법을 통하여 특정 값을 확인 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Ragged Tensor 생성
rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])
print('Ragged Tensor')
print(rt)
print()
# Ragged Tensor -> List
rt_list = rt.to_list()
print('Ragged Tensor -> List')
print('List Value: {}, List Type: {}'.format(rt_list, type(rt_list)))
print()
# Ragged Tensor -> Indexing -> Eager Tensor
rt_eager = rt[1]
print('Ragged Tensor -> Indexing -> Eager Tensor')
print('Eager Tensor: {}, Eager Tensor: {}'.format(rt_eager, type(rt_eager)))
print()
# Function
print('Ragged Tensor Value{}'.format(rt.values))
print('Ragged Tensor row_splits{}'.format(rt.row_splits))
Ragged Tensor
<tf.RaggedTensor [[1, 2], [3, 4, 5], [6], [], [7]]>
Ragged Tensor -> List
List Value: [[1, 2], [3, 4, 5], [6], [], [7]], List Type: <class 'list'>
Ragged Tensor -> Indexing -> Eager Tensor
Eager Tensor: [3 4 5], Eager Tensor: <class 'tensorflow.python.framework.ops.EagerTensor'>
Ragged Tensor Value[1 2 3 4 5 6 7]
Ragged Tensor row_splits[0 2 5 6 6 7]
참조: 원본코드
참조: Ragged Tensor
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment