#One-Sample T-test
#귀무가설: 모수와 같다.
#대립가설: 모수와 다르다.
#예1) 어느 남성 집단의 평균 키 검정하기
one_sample=[177.0,182.7,169.6,176.8,180.0]print("one_sample 평균: ",np.array(one_sample).mean())'''
귀무: 어느 남성 집단의 평균 키는 177이다. (모수)
대립: 어느 남성 집단의 평균 키는 177 이 아니다.
'''result1=stats.ttest_1samp(one_sample,popmean=177)# popmean=177 -> 예상평균 값
'''
귀무: 어느 남성 집단의 평균 키는 167이다. (모수)
대립: 어느 남성 집단의 평균 키는 167 이 아니다.
'''result2=stats.ttest_1samp(one_sample,popmean=167)# popmean=167 -> 예상평균 값
print("result1 결과) statistic: %.3f, pvalue: %.3f"%result1)# pvalue: 0.925 > 0.05 이므로 귀무 채택 -> 177이 맞다!
print("result2 결과) statistic: %.3f, pvalue: %.3f"%result2)# pvalue: 0.010 < 0.05 이므로 대립 채택 -> 167이 아니다!
#independent samples t-test
#예1) 남녀 집단 간 파이썬 시험의 평균 차이 검정
'''
귀무: 남녀 두 집단 간 파이썬 시험의 평균에 차이가 없다.
대립: 남녀 두 집단 간 파이썬 시험의 평균에 차이가 있다.
'''male=[75,85,100,72.5,86.5]female=[63.2,76,52,100,70]two_sample=stats.ttest_ind(male,female)print(two_sample)# pvalue=0.25 > 0.05 이므로 귀무 채택
print(np.mean(male))print(np.mean(female))
#예2) 두 가지 교육방법에 따른 평균시험 점수에 대한 검정 수행
'''
귀무: 교육방법에 따른 시험점수는 차이가 없다.
대립: 교육방법에 따른 시험점수는 차이가 있다.
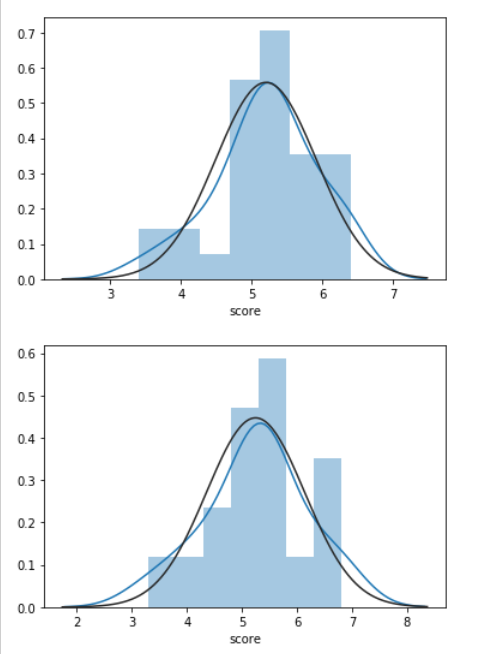
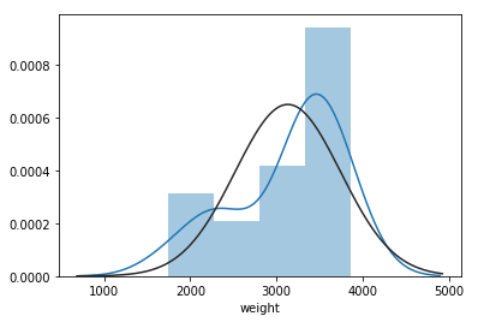
'''data=pd.read_csv("https://raw.githubusercontent.com/wjddyd66/R/master/Data/two_sample.csv")print(data.head(2))result=data[["method","score"]]print(result.head())m1=result[result["method"]==1]m2=result[result["method"]==2]score1=m1["score"]score2=m2["score"]sco1=score1.fillna(score1.mean())sco2=score2.fillna(score2.mean())print(sco1)sns.distplot(sco1,fit=stats.norm)plt.show()sns.distplot(sco2,fit=stats.norm)plt.show()print(stats.shapiro(sco1))# 0.36 > 0.05
print(stats.shapiro(sco2))# 0.67 > 0.05
result=stats.ttest_ind(sco1,sco2)print("t 검정 통계량: %.5f, p값: %.5f"%result)# pvalue=0.84 > 0.05 귀무 채택
#paired samples t-test
#동일한 관찰대상으로부터 처리 이전과 이후를 1:1로 대응시킨 두 집단 표본을 이용해 t 검정을 실시한다.
'''
예)복부 수술 전 9명의 몸무게와 복부 수술 후 몸무게 변화
귀무: 변화에 차이가 없다.
대립: 변화에 차이가 있다.
'''baseline=[67.2,67.4,71.5,77.6,86.0,89.1,59.5,81.9,105.5]follow_up=[62.4,64.6,70.4,62.6,80.1,73.2,58.2,71.0,101.0]paired_result=stats.ttest_rel(baseline,follow_up)print(paired_result)# pvalue=0.00632 < 0.05 대립 채택
#ANOVA: 세 집단 이상의 평균차이 검정
#종속변수의 분산과 독립변수의 분산간의 관계를 사용하여
#선형회귀 분석의 성능평가 모형으로 사용 가능
'''
예) 세 가지 교육방법을 적용하여 1개월 동안 교육받은 교육생 80명을 대상으로 실기시험을 실시한다.
귀무: 교육방법(세 집단)에 따른 시험점수 차이가 없다.
대립: 교육방법(세 집단)에 따른 시험점수 차이가 있다.
'''url="https://raw.githubusercontent.com/wjddyd66/R/master/Data/three_sample.csv"data=pd.read_csv(url)print(data.head(3))print(len(data))# 80
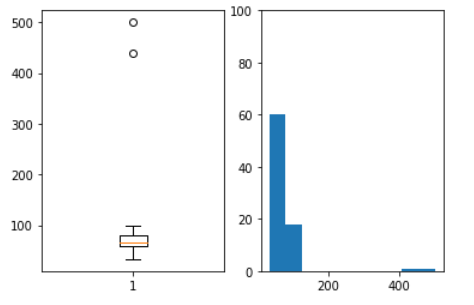
print(data.describe())# outlier 발견
plt.grid()plt.subplot(121)plt.boxplot(data.score)plt.subplot(122)plt.hist(data.score)plt.ylim(0,100)plt.show()
# 교차표
data2=pd.crosstab(index=data["method"],columns="count")data2.index=["방법1","방법2","방법3"]print("data2: \n",data2)# 교차표: 교육방법 별 만족여부 건 수
data3=pd.crosstab(index=data["method"],columns=data["survey"])data3.index=["방법1","방법2","방법3"]data3.columns=["만족","불만족"]print("data3: \n",data3)print("-"*30)importstatsmodels.formula.apiassmfreg=smf.ols("data['score'] ~ data['method']",data=data).fit()#단일회귀 모델
table=sm.stats.anova_lm(reg,type=2)print(table)

Leave a comment