
NeuralNetwork (1) Basic & Activation Function
NeuralNetwork
Neural Network는 아래와 같은 그림으로 이루워져 있다.

왼쪽부터 Input(입력층), Hidden(은닉층),Output(출력층)으로 표현할 수 있다.
각각의 Hidden Layer의 Node하나하나를 이전에 Post하였던 Perceptron이라고 생각할 수 있다.
Neural Network는 다음과 같은 중요한 개념은 크개5개로서 이루워진다고 할 수 있다.
- 활성화 함수(Activation Function)
Input Data를 Weight와 Bias를 통하여 Output에 가깝게 하기 위한 Function - Loss Function
예측값과 실제값의 차이를 표현하는 Function - Optimazation
Loss Function을 통하여 Weight와 Bias를 Trainning하기 위한 과정 - BackPropagation
결과 값을 통해서 다시 역으로 input방향으로 오차를 보내며 가중치를 재업데이트하는 것 - 검증
2~4를 통하여 만들어진 Model을 검증하는 방법
위와 같은 큰 개념 5개중 Activation Function에 대해서 먼저 알아보도록 하자.
활성화 함수(Activation Function)
1. 시그모이드
식: \(\sigma(x) = {1 \over 1+e^{-x}}\)
미분식: \(\sigma\prime(x) = \sigma(x)(1-\sigma(x))\)
범위:[0,1]
위와 같은 시그모이드는 아래 코드로서 구현될 수 있다.
1
2
3
4
5
6
#sigmoid 함수 선언
def sigmoid(x):
return 1/(1+np.exp(-x))
#sigmoid 미분 함수 선언
def sigmoid_(x):
return sigmoid(x)*(1-sigmoid(x))
Sigmoid 그래프를 확인하기 위하여 아래 코드를 실행
1
2
3
4
5
6
7
8
9
#Sigmoid 그래프로서 표현하기
x = np.arange(-7.0,7.0,0.1)
y = sigmoid(x)
plt.plot(x,y)
plt.plot([0,0],[1.0,0.0],':')
plt.ylim(-0.1,1.1)
plt.title('Sigmoid Function')
plt.show()
시그모이드 함수 그래프
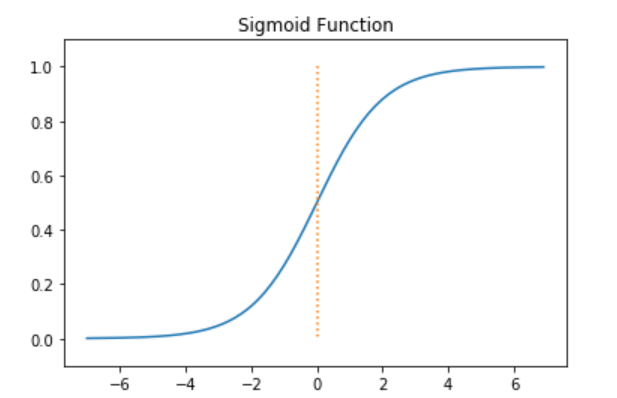
Sigmoid 미분 그래프를 확인하기 위하여 아래 코드를 실행
1
2
3
4
5
6
7
8
9
#Sigmoid 미분그래프로서 표현하기
x = np.arange(-7.0,7.0,0.1)
y = sigmoid_(x)
plt.plot(x,y)
plt.plot([0,0],[0.5,0.0],':')
plt.ylim(-0.1,0.5)
plt.title('Sigmoid Differential Function')
plt.show()
시그모이드 미분 그래프
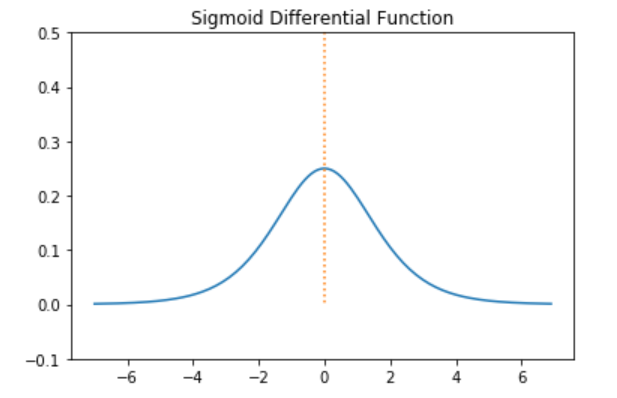
-5 보다 작거나 5 보다 클 경우Gradient값이 지나치게 작아지고 exp연산때문에 느려지는 단점이 생기게 된다.
항상 0이상의 값을 가지기 때문에 Gradient Decent로 w를 학습시 허용되는 방향에 제약이 가해져 학습속도가 늦거나 수렴이 어렵게 된다.
2. 하이퍼 볼릭 탄젠트
식: \(\tanh(x) = {e^{x} - e^{-x} \over e^{x} + e^{-x} }\)
미분식: \(\tanh\prime(x) = 1-\tanh^2(x)\)
범위:[-1,1]
위와 같은 하이퍼 볼릭 탄젠트는 아래 코드로서 구현될 수 있다.
1
2
3
4
5
6
#tanh 함수 선언
def tanh(x):
return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x))
#tanh 미분 함수 선언
def tanh_(x):
return 1-(tanh(x)*tanh(x))
tanh 그래프를 확인하기 위하여 아래 코드를 실행
1
2
3
4
5
6
7
8
9
#tanh 그래프로서 표현하기
x = np.arange(-7.0,7.0,0.1)
y = tanh(x)
plt.plot(x,y)
plt.plot([0,0],[1.0,-1.0],':')
plt.ylim(-1.1,1.1)
plt.title('tanh Function')
plt.show()
tanh 함수 그래프
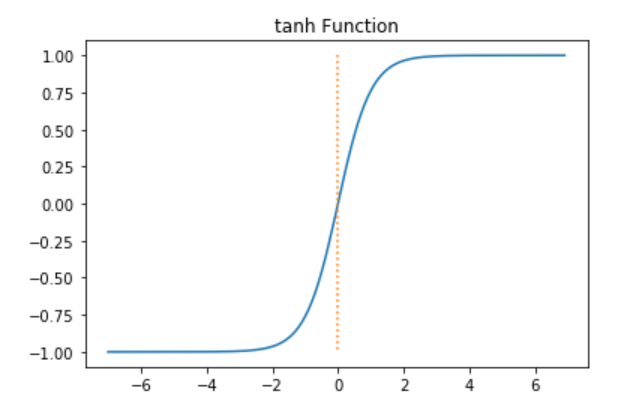
tanh 미분 그래프를 확인하기 위하여 아래 코드를 실행
1
2
3
4
5
6
7
8
9
#tanh 미분그래프로서 표현하기
x = np.arange(-7.0,7.0,0.1)
y = tanh_(x)
plt.plot(x,y)
plt.plot([0,0],[2.0,0.0],':')
plt.ylim(-0.1,2.0)
plt.title('tanh Differential Function')
plt.show()
tanh 미분 그래프
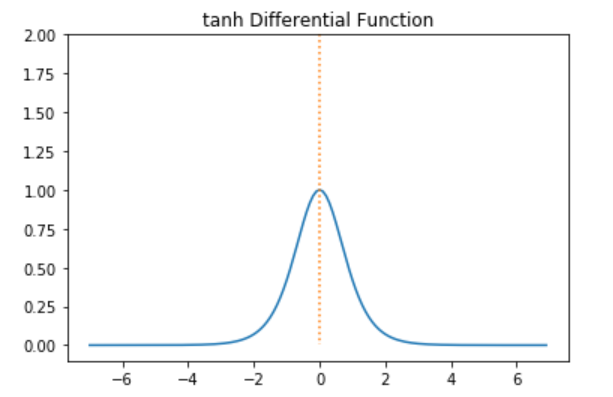
-5 보다 작거나 5 보다 클 경우Gradient값이 0으로 가까워 진다는 단점이 존재하게 된다.
0을 기준으로 대칭되는 값을 가지기 때문에 Gradient Decent로 w를 학습시 허용되는 방향에 제약이없어져 시그모이드보다 학습속도가 빠르고 수렴이 쉽게 된다.
3. ReLU
식: \(f(x) = max(0,x)\)
미분식:
- x > 0 : 1
- x < 0 : 0
범위:0이상의 양수
위와 같은 ReLU는 아래 코드로서 구현될 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
#ReLU 함수 선언
def relu(x):
return np.maximum(0,x)
#ReLU 미분 함수 선언
def relu_(x):
result =[]
for i in x:
if(i>=0):
result.append(1)
else:
result.append(0)
return result
ReLU 그래프를 확인하기 위하여 아래 코드를 실행
1
2
3
4
5
6
7
8
9
#ReLU 그래프로서 표현하기
x = np.arange(-7.0,7.0,0.1)
y = relu(x)
plt.plot(x,y)
plt.plot([0,0],[8.0,-0.5],':')
plt.ylim(-0.3,8.1)
plt.title('ReLU Function')
plt.show()
ReLU 함수 그래프
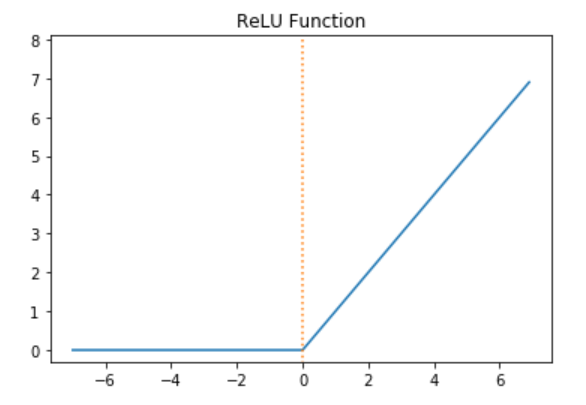
ReLU 미분 그래프를 확인하기 위하여 아래 코드를 실행
1
2
3
4
5
6
7
8
9
#ReLU 미분그래프로서 표현하기
x = np.arange(-7.0,7.0,0.1)
y = relu_(x)
plt.plot(x,y)
plt.plot([0,0],[1.5,-0.5],':')
plt.ylim(-0.5,1.5)
plt.title('ReLU Differential Function')
plt.show()
ReLU 미분 그래프

5 보다 클 경우Gradient값이 0으로 가까워 진다는 단점을 극복하였으나 0 보다 작을 경우모든 값을 0이 된다는 단점이 존재하게 된다.
4. 소프트맥스
식: \(y = \frac{e^{wx_i}}{\sum_{i=0}^n e^{wx_i}}\)
입력받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력 값들의 총합은 항상 1이 되는 특성을 가진 함수이다.
분류하고 싶은 클래수의 수 만큼 출력으로 구성한다.
아래 그림을 보게 되면 Sigmoid와 차이를 알 수 있다.
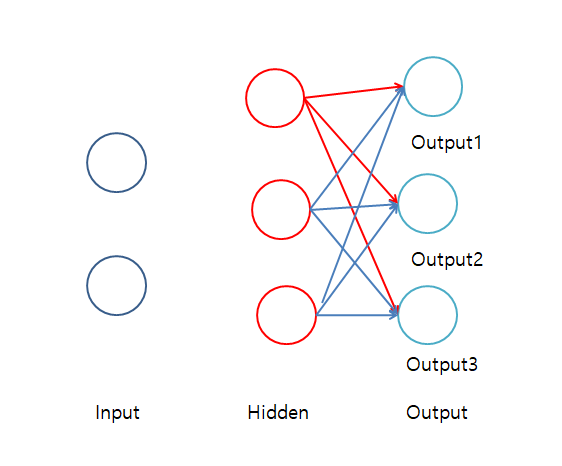
Sigmoid 사용할 경우 Output 1을 위한 Weight를 Update시키게 되면 위의 그림에서 빨간선 3개만 Update의 대상이 된다.
하지만 Softmax를 사용하게 되면 Output1 + Output2 + Output3 =1 이 되므로 Output 1을 위한 Weight를 Update 시키게 되면 자동적으로 Output2, Output3까지 모두 영향을 받게 되므로 학습의 과속화가 진행되어 많이 사용하게 된다.
Softmax는 항상 똑같은 값으로서표현 될 수 없으므로 그래프가 아닌 다음과 같은 과정으로서 확인하여 보였다.
Softmax 함수 선언
1
2
3
4
5
6
def softmax(a):
max = np.max(a)
value = np.exp(a)
sum = np.sum(value)
result = value/sum
return result
Softmax값 확인
1
2
3
4
5
6
7
8
#Softmax그래프로서 표현하기
x = np.array([100,200,300])
y = softmax(x)
plt.scatter(x,y)
plt.ylim(-0.1,1.1)
plt.title('Softmax Result')
plt.show()

위의 결과를 확인하면 y의 총합은 1이되는 것을 알 수 있고, 특정 한개의 값은 1 나머지의 값은 0으로서 값이 출력되는 것을 확인할 수 있다.
Softmax 미분
Softmax의 미분을 알아보기 위하여 먼저 Parameter들을 아래와 같이 정의하였다.
| Parameter | 의미 |
| $$n$$ | 분류해야할 범주 수 |
| $$a_i$$ | Softmax의 i 번째 입력값 |
| $$p_i$$ | Softmax의 i 번째 출력값 |
위와 같이 Parameter를 정의하게 되면 Softmax의 식은 아래와 같이 나타낼 수 있다.
$$p_i = \frac{exp(a_i)}{\sum_n exp(a_n)}$$
위와 같이 선언하였을때 Softmax의 미분은 2가지 경우에 따라서 값이 다르게 나온다.
1. \(i=j\)의 경우
$$\frac{\partial p_i}{\partial a_i} = \frac{\partial \frac{exp(a_n)}{\sum_n exp(a_n)}}{\partial a_i}$$
$$ = \frac{exp(a_i)\sum_n exp(a_n) - exp(a_i)exp(a_i)}{(\sum_n exp(a_n))^2}$$
$$ = \frac{exp(a_i)[\sum_n exp(a_n) - exp(a_i)]}{(\sum_n exp(a_n))^2}$$
$$ = \frac{exp(a_i)}{\sum_n exp(a_n)} \frac{\sum_n exp(a_n) - exp(a_i)}{\sum_n exp(a_n)}$$
$$ = \frac{exp(a_i)}{\sum_n exp(a_n)} (1-\frac{exp(a_i)}{\sum_n exp(a_n)})$$
$$ = p_i(1-p_i)$$
2. \(i \neq j\)의 경우
$$\frac{\partial p_i}{\partial a_i} = \frac{0 - exp(a_i)exp(a_j)}{(\sum_n exp(a_n))^2}$$
$$ = -\frac{exp(a_i)}{\sum_n exp(a_n)} \frac{exp(a_j)}{\sum_n exp(a_n)}$$
$$ = -p_ip_j$$
Softmax 구현시 주의사항
exp함수를 사용함으로써 입력 값의 증가에 따라 Return 값이 무한정으로 커지는 단점이 존재한다.
컴퓨터는 8bit 이므로 8bit 이상으로 표현되는 숫자는 Overflow가 발생하는 문제가 생기게 된다.
이러한 문제를 해결하기 위하여 입력 값중에 제일 큰 값을 뺸 것을 입력값으로 사용함으로써 해결하게 된다.
아래 식으로서 입력 값 중에 제일 큰 값을 빼도 된다는 것을 알 수 있다.
$$y = \frac{e^{wx_i}}{\sum_{i=0}^n e^{wx_i}}$$
$$ = \frac{Ce^{wx_i}}{C\sum_{i=0}^n e^{wx_i}} (C는 임의의 상수)$$
$$ = \frac{e^{wx_i+logC}}{\sum_{i=0}^n e^{wx_i+logC}}$$
$$ = \frac{e^{wx_i}+C'}{\sum_{i=0}^n e^{wx_i}+C'}$$
위에서 선언한 C’를 입력값 중 제일 큰 값이라고 생각하면 Return값이 무한정으로 커지는 것을 어느정도 해결할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
'''
Sofrmax 구현시 주의사항
exp 함수를 사용함으로써 x값의 증가에 따라 Return값이 무한정으로 커지는 단점이 존재
매우 큰 수로 나눗셈을 실시 할 시 Overflow가 발생하게 된다.
'''
#exp 그래프로서 표현하기
x = np.arange(-1,500,1)
y = np.exp(x)
plt.plot(x,y)
plt.title('Exp Function')
plt.show()
#Overflow 발생 예시
a = np.array([1010,1000,990])
y = softmax(a)
print(y)
'''
[nan nan nan]
C:\Tensor\envs\tensorflow\lib\site-packages\ipykernel_launcher.py:6: RuntimeWarning: invalid value encountered in true_divide
'''
#Overflow 발생 해결 방법
max = np.max(a)
a = a-max
y2=softmax(a)
print(y2) #[9.99954600e-01 4.53978686e-05 2.06106005e-09]
[nan nan nan]
[9.99954600e-01 4.53978686e-05 2.06106005e-09]

위의 대표적인 활성화함수 4개를 살펴보게 되면 전부 Linear 하지 않은 특성을 가지고 있다.
아래 예시를 보게 되면 왜 활성화 함수는 Linear 하지 않아야 하는지 알 수 있다.
선형 함수인 h(x)=cx를 활성 함수로 사용한 3층 네트워크를 떠올려 보세요. 이를 식으로 나타내면 y(x)=h(h(h(x)))가 됩니다. 이 계산은 y(x)=c∗c∗c∗x처럼 세번의 곱셈을 수행하지만 실은 y(x)=ax와 똑같은 식입니다. a=c3이라고만 하면 끝이죠. 즉 히든레이어가 없는 네트워크로 표현할 수 있습니다. 그래서 층을 쌓는 혜택을 얻고 싶다면 활성함수로는 반드시 비선형함수를 사용해야 합니다.
참고사항
각각의 활성함수에 대해서 알아보았을때 각자 장 단점이 존재한다는 것을 알 수 있다. 다음은 주로 활성화 함수를 사용할 경우에 대해서 알아보자
회귀 : 항등함수(출력값을 그대로 반환하는 함수) indentity function
분류(0/1): Sigmoid Function
분류(multiple): Softmax Function
NeuralNetwork 구현
현재 1~5과정 중 1. 활성화 함수(Activation Function) 에 대해서만 배웠으므로 2~4 과정이 되어있는 Model을 불러서 사용하는 예제를 따라해 보았다.
Model은 pkl형식(Python 객체를 그대로 파일에 저장하고 다시 파일에서 읽어들이기 위한 확장자)으로 되어있었다.
DataSet은 Mnist 형식의 손글씨 형식으로서 사진에 흑백으로 숫자가 적혀있다.

배치 처리:이미지 여러장을 한꺼번에 입력하여 Trainning되는 시간을 줄였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
import pickle
import numpy as np
from mnist import load_mnist
# MNIST 데이터셋
'''
0~9 숫자 이미지로 구성.
훈련 이미지 60000장, 시험 이미지 10000장
28*28 크기의 회색조 이미지이며 각 픽셀은 0~255의 값을 가짐
레이블은 정답에 해당하는 숫자
'''
# 이미지를 numpy 배열로 저장
# flatten : 입력 이미지를 평탄화(1차원 배열로)
# normalize : 입력 이미지를 정규화(0.0~1.0 사이의 값으로)
# one_hot_label : 레이블을 원-핫 인코딩 형태로 저장
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True,
normalize=False)
# 각 데이터의 형상 출력
print(x_train.shape) # (60000, 784)
print(t_train.shape) # (60000,)
print(x_test.shape) # (10000, 784)
print(t_test.shape) # (10000,)
# 신경망의 추론 처리
'''
입력층 784개, 출력층 10개,
은닉층 50개, 100개로 구성(임의)
'''
def get_data():
(x_train, t_train), (x_test, t_test) = \
load_mnist(flatten=True, normalize=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
# 학습된 가중치 매개변수가 담긴 파일
# 학습 없이 바로 추론을 수행
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
accuracy_cnt = 0
'''
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) # 확률이 가장 높은 원소의 인덱스를 얻는다.
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x))) # Accuracy:0.9352
'''
# 배치 처리
batch_size = 100
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x))) # Accuracy:0.9352
(60000, 784)
(60000,)
(10000, 784)
(10000,)
Accuracy:0.9352
참조:원본코드
참조: ratsgo 블로그
참조: 밑바닥 부터 시작하는 딥러닝
참조:문과생도 이해하는 딥러닝
문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment