
Kubernetes
사전지식
Kubeflow를 구축하기에 앞서 Kubeflow는 Kubernetes + mlflow 의 합친 말 이다.
mlflow란 Machine Learning의 Workflow를 의미한다.
즉 Machine Learning을 Kubernetes를 활용하여 쉽게 관리하게 도와주는 것이 Kubeflow라는 것 이다.
따라서 Kubeflow의 기반인 Kubernetes에 대해서 깊게는 아니여도 기본적인 개념은 알아두고 Kubeflow에 대해새 알아보자
먼저 Kubernetes에대해서 알기 전에 Docker 에 대해서 사전지식이 필요한다.
Docker 사전지식: Docker Category
클라우드를 사용한 Docker 실행 환경 구축 Post를 살펴보면 Kubernetes를 컨테이너 오케스트레이션의 하나라고 잠시 언급하였다.
컨테이너 오케스트레이션은 컨테이너의 시작 및 정지와 같은 조작뿐만 아니라 호스트간의 네트워크 연결이나 스토리지 관리, 컨테이너를 어떤 호스트에서 가동할지와 같은 스케줄링, 컨테이너가 정상적으로 작동하고 있는지 아닌지를 감시하는 기능을 갖춘 툴이라고 정의하였다.
그렇다면 많은 오케스트레이션툴 중에서 Kubernetes의 특징에 대해서 알아보자.
Kubernetes
Kubernetes는 오케스트레이션 툴 중에서 가장널리 사용되는 솔루션이며 약자로 k8s라고 불린다.
이러한 Kubernetes를 사용하는 이유에 대해서 알아보자.
다양한 배포 방식
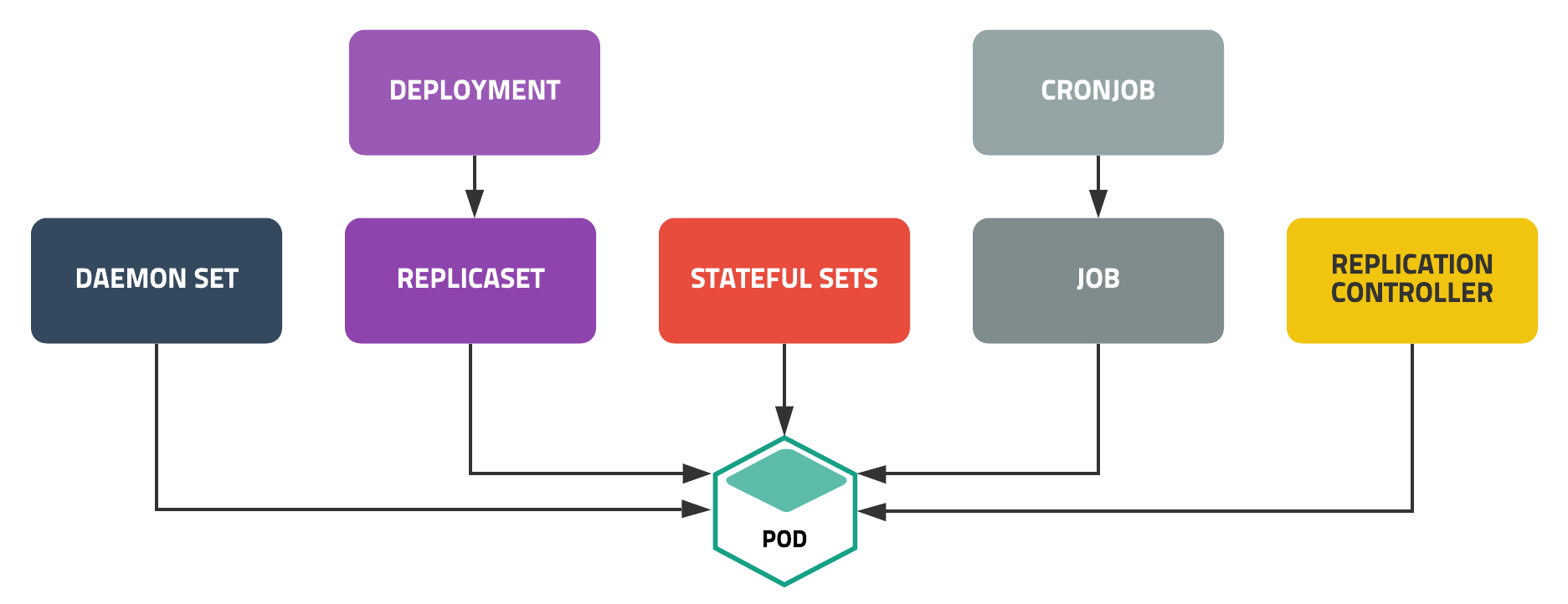
사진 출처: subicura 블로그
Kubernetes는 Deployment, Statefulsets, DemonSet, Job, CronJob등 다양한 배포 방식을 지원한다.
- Job: Job이 종료되면 Pod를 같이 종료
- Cron jobs: 주기적으로 정해진 스케줄에 따라 자동화해서 실행
자세한 내용: 조대협의 블로그
Ingress 설정
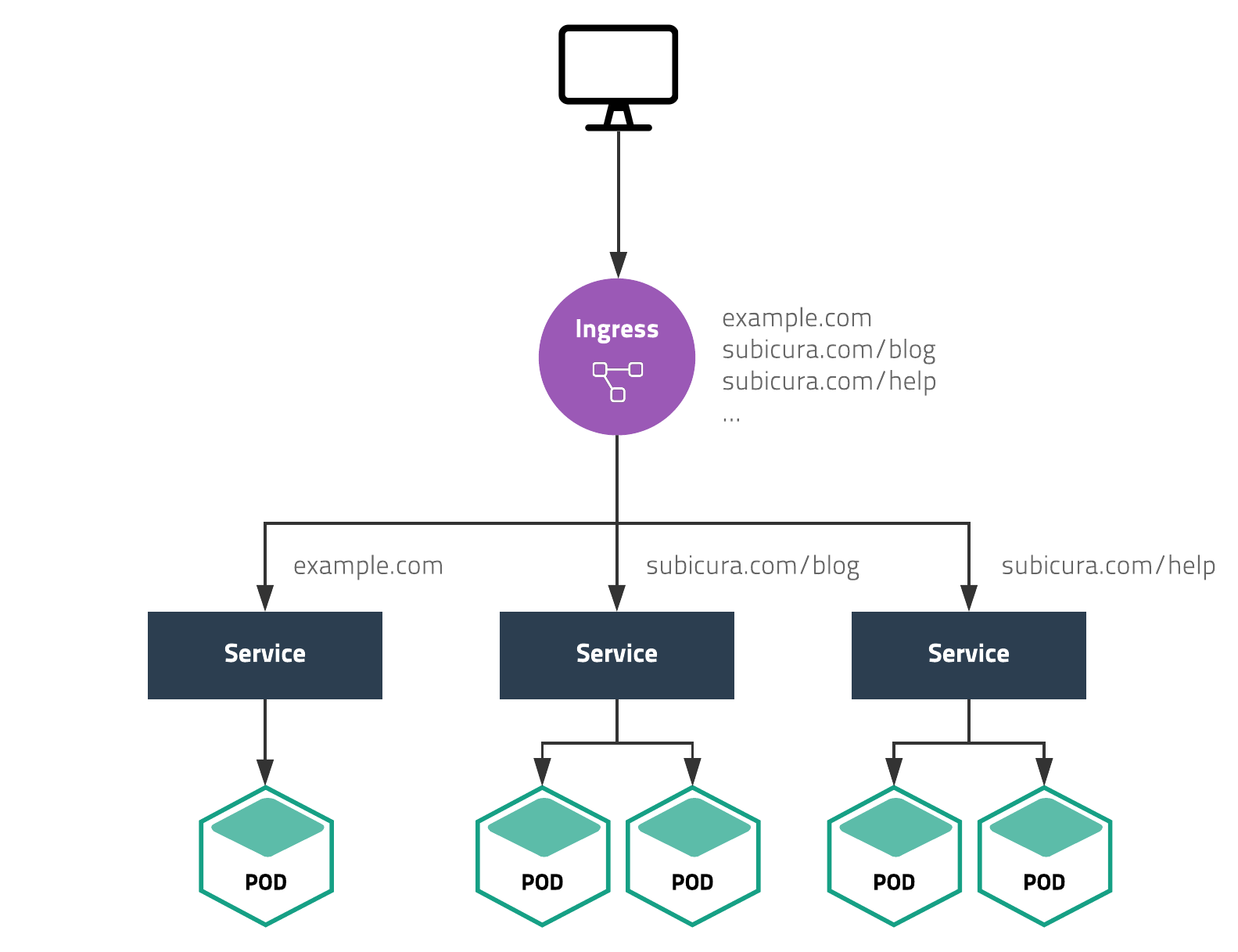
사진 출처: subicura 블로그
실질적으로 Kubernetes를 사용하면서 가장 편했던 기능 중 하나이다.
다양한 웹 애플리케이션을 하나의 로드 밸런서로 서비스하기위해 Ingress기능을 제공한다.
즉, 외부에서 직접 접근할 수 업도록 애플리케이션을 내부망에 설치하고 외부에서 접근이 가능한 Nginx, Apache를 프록시 서버로 활용한다.
Kubernetes는 서버가 바뀌거나 IP가 변경되어도 따로 변경하지 않는다. (외부와 내부를 분리)
따라서 기존 프록시 서버에서 사용하는 설정을 거의 그대로 사용할 수 있다.
클라우드 지원

사진 출처: subicura 블로그
Kubernetes는 다양한 클라우드 환경을 제공한다.(Google이 만들었으므로, 대부분의 Document는 GCP랑 연동하는 방법에 나와있다.)
Kubernetes는 부하에 따라 자동으로 서버를 늘리는 기능 AutoScaling이 있고 IP를 할당받아 로드밸런스를 사용할 수 있다.
이러한 기능은 Cloud에서 환경을 적용시켜 손쉽게 이루워질 수 있다.
(하지만, 비용 문제 때문에 앞으로의 실습환경은 Local에서 Minikube를 사용합니다.)
RBAC(role-based access control)
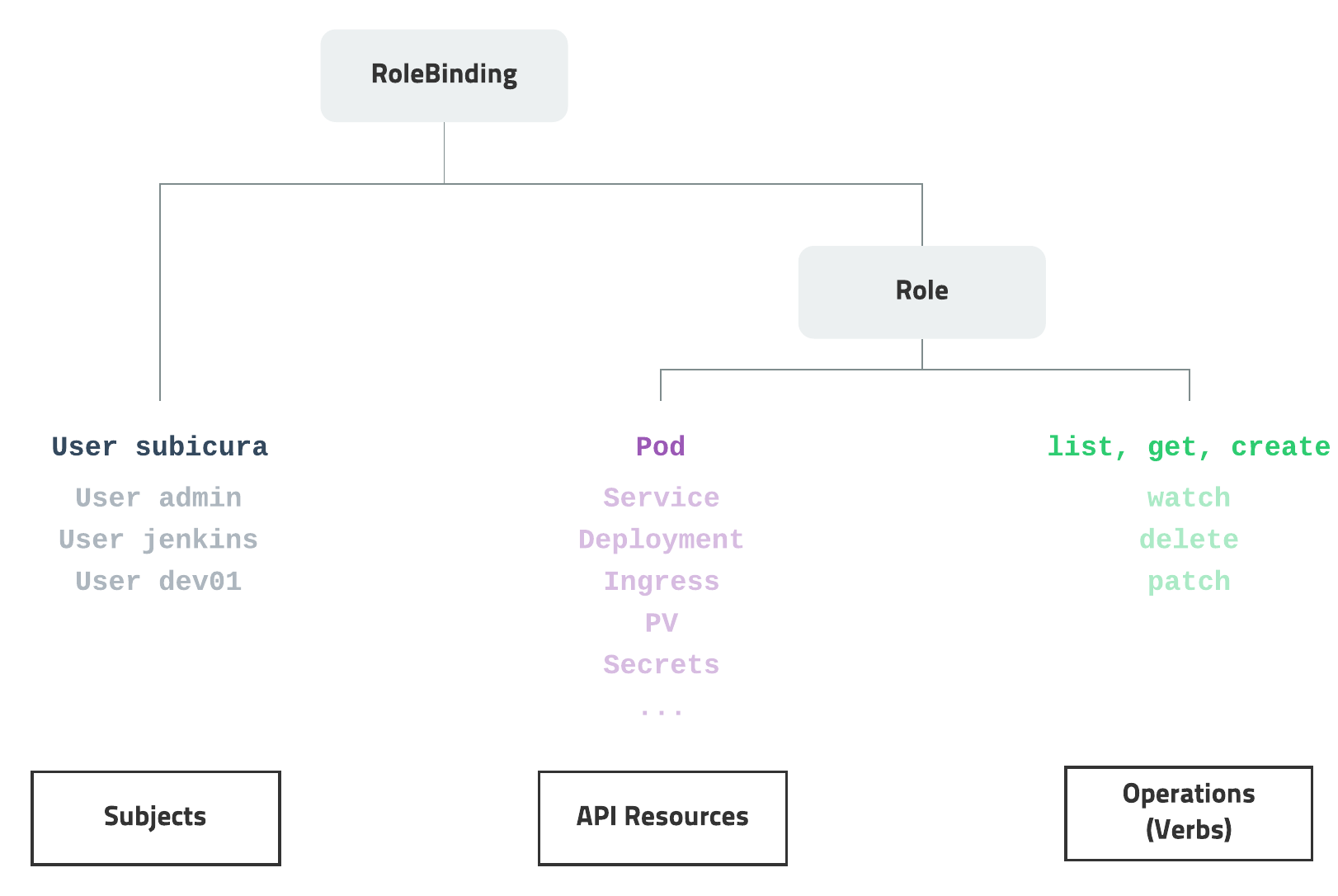
사진 출처: subicura 블로그
접근 권한 시스템을 각각의 리소스에대해 유저별로 권한을 손쉽게 지정할 수 있다.
Namespace, Label로서 적용하거나, 클러스터 전체에 적용할 수 있다.
Auto Scaling
Kubernetes는 CPU, Memory 사용량에 따른 확장은 기본이고 현재 접속자 수와 같은 값을 사용할 수도 있다.
많은 사용자가 사용하는 환경에 알맞는 이유가 이것이 가장 크다고 생각하다.
계속해서 Monitoring하는 것이 아니라 지정한 Scaling의 범위까지 자동으로 늘릴 수 있는 기능이 존재하기 때문이다.
자가 치유 시스템
Kubernetes는 온라인 자가 치유 시스템이다.
요구하는 상태 설정을 받으면 한번에 현재 상태를 요구된 상태와 일치시키려고 하지 않는다.
오히려 현재 상태를 요구된 상태로 일치시키려고 끊임없이 확인한다.
즉, 계속해서 스스로 일정시간마다 확인하고 현재 상태를 요구된 상태와 일치시키려고 노력한다.
Kubernetes Object
쿠버네티스는 상태를 관리하기 위한 대상을 오브젝트로 정의한다.
이러한 Object를 정의하기 위하여 yaml 이나 json파일로 Object Spec을 정의할 수 있다.
Pod
Docker와 달리 Kubernetes는 Pod을 가장 기본적인 배포 단위로 사용한다.
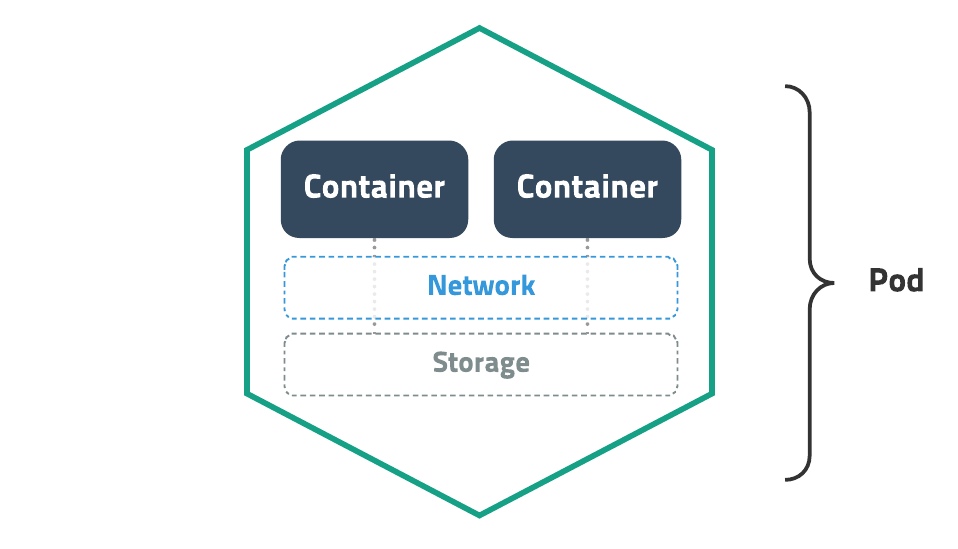
사진 출처: subicura 블로그
위의 그림과 같이 Pod은 여러 Container를 포함시킬 수 있다.
Pod은 다음과 같은 중요한 특징을 2가지 가진다.
- Pod내의 컨테이너는 IP와 Port를 공유한다. 즉, 하나의 Pod안에 있는 Container끼리는 통신이 가능하다.
- Pod내의 배포된 Container간에는 디스크 볼륨을 공유할 수 있다.
Volume
저장소와 관련된 Object이다.
컨테이너의 외장 디스크로 생각하면 된다. Pod이 기동될때 컨테이너에 마운트해서 사용한다.
Service
Network를 관리하는 Object이다.
Pod을 외부 네트워크와 연결해주고 여러개의 Pod을 바라보는 내부 로드 밸런서를 생성할 때 사용한다.
하나의 Pod이아닌 다양한 Pod을 통해 분산환경에서 서비스를 제공하는 경우 로드벨런서를 이용해서 하나의 IP와 Port로 묶어서 서비스를 제공한다.
Namespace & Label
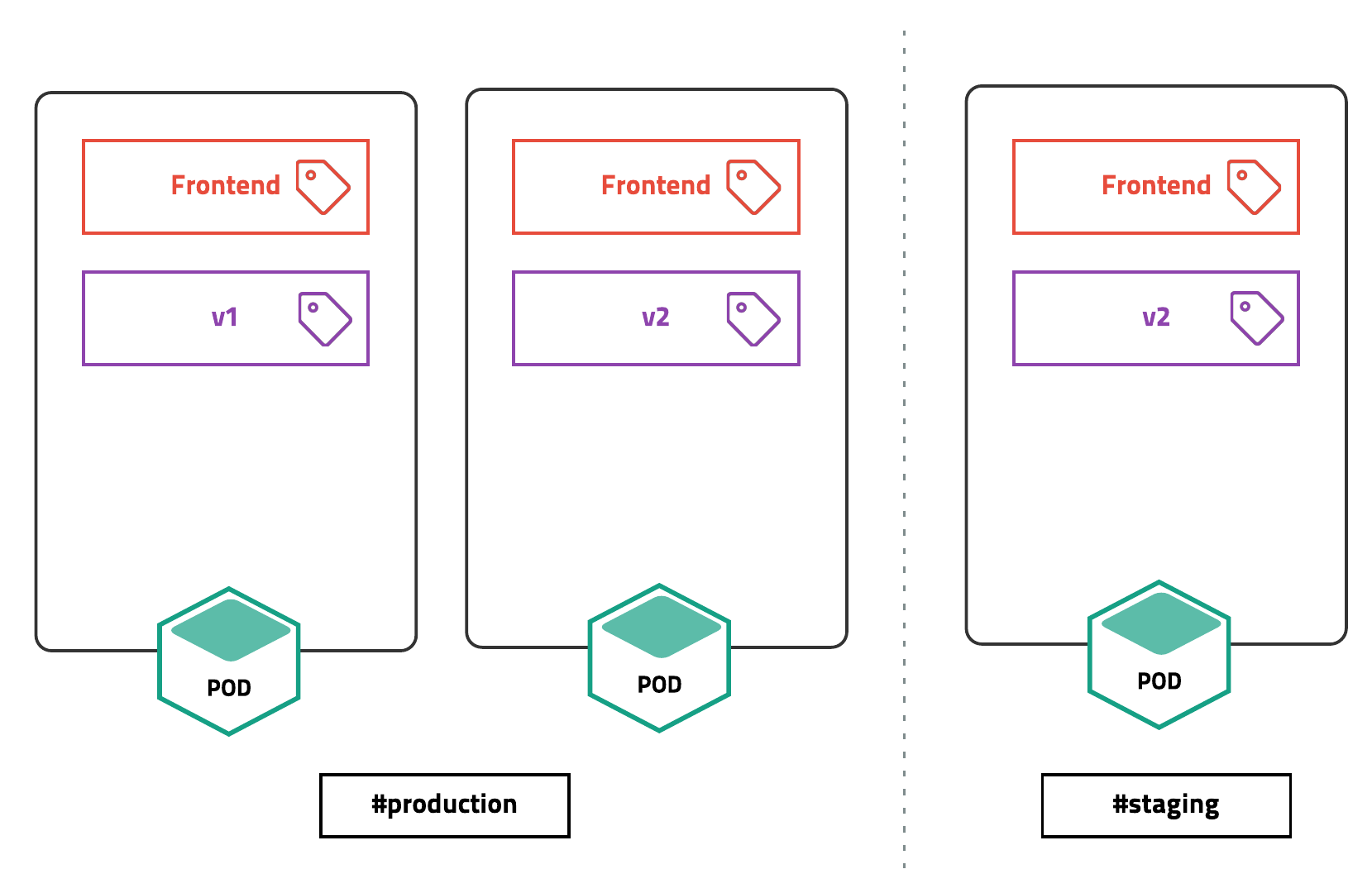
사진 출처: subicura 블로그
Kubernetes는 Namespace와 Label을 사용하여 하나의 클러스터(Node)를 논리적으로 구분하여 사용할 수 있다.
물리적으로 분리하는 것이 아니기 때문에 하나의 Pod안에서의 다른 Namespace간의 통신은 가능하다.
세부적인 설정을 Namespace와 Label을 사용하여 한번에 적용시킬 수 있다.
개인적으로 많이 사용하고 중요하다고 생각하는 것은 네임스페이스 별로 리소스의 쿼타를 지정할 수 있다. 즉, 어떠한 Namespace에서 CPU와 GPU의 할당량을 선언할 수 있다.
ReplicaSet
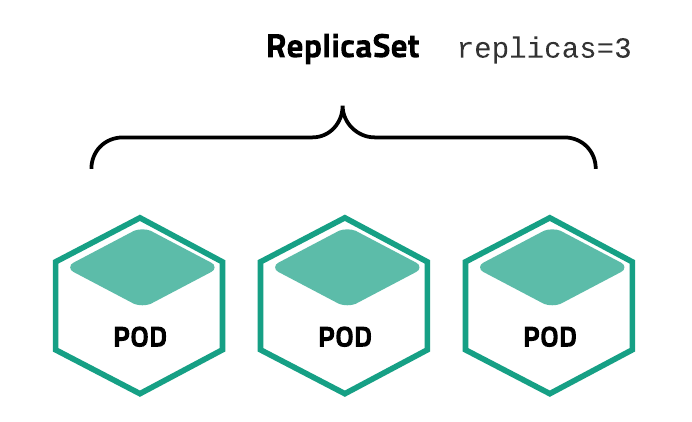
사진 출처: subicura 블로그
Pod을 여러 개 복제하여 관리하는 Object이다.
위에서 언급한 다양한 배포방식에서 ReplicaSet을 통하여 Pod을 새로운 상태로 배포하는 경우 사용된다.
Pod을 생성하고 개수를 유지하려면 반드시 ReplicaSet을 사용해야 한다.
Object Spec
Object Spec이란 Object를 정의하기 위한 내용을 .yaml 파일 형식으로 지정한 것 이다.
아래 예시를 살펴보자.
kind: PersistentVolume
apiVersion: v1
metadata:
name: kubeflow-volume
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/storage/kubeflowstorage"
- kind: Object의 종류를 정의할 수 있다. 여기서는 Volume의 구성요소 중 하나인 PV로서 정의하였다.(PV는 나중에 자세히 알아보자)
- apiVersion: 스크립트를 실행하기 윟나 쿠버네티스 API 버전
- metadata: 각종 메타 데이터, 라벨이나, 리소스의 이름등 각종 메타데이터를 넣는다.
- spec: 리소스에 대한 상세한 스펙을 정의한다.
Kubernetes Architecture
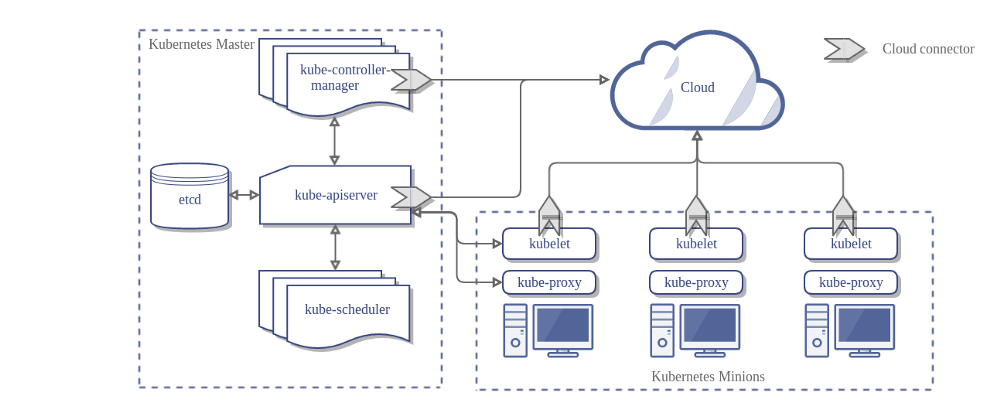
사진 출처: Kubernetes 홈페이지
쿠버네티스는 크게 Master와 Node로서 구분된다.
Master
쿠버네티스 클러스터 전체를 컨트롤하는 시스템으로, Kube-apiserver, Kube-scheduler, Kuber-controller manager, etcd로 구성되어 있다.
- Kube-apiserver: Node와 통신을 하기위한 Server
- etcd: 데이터 베이스 역활로 쿠버네티스 클러스터의 상태나 설정 정보를 저장한다.
- Kube-scheduler: 리소스들을 적절한 노드에 할당한다.
- Kube-controller: Controller를 생성하고 이를 각 노드에 배포하여 이를 관리하는 역할
Node
마스터에 의해 명령을 받고 실제 워크로드를 생성하여 서비스 하는 컴포넌트
- Kubelet: API서버와 통신하면서, 수행해야할 명령을 받고 상태를 Master에게 전달
- Kube-proxy: Node와 Master간에 네트워크 통신을 관리
Kubectl 명령어
위에서 Kubernetes의 구조를 살펴보면서 Master와 Node의 역활가 API Server를 통하여 서로 통신을 하는것을 알 수 있었다.
API통신을 위하여 사용하는 명령줄 도구인 Kubectl을 통하여 Pod, ReplicaSet, Service와 같은 Kubernetes의 Object를 관리하고, 클러스터의 전반적인 상태를 탐색하고 확인하는데 사용한다.
클러스터 상태 확인
Kubectl 버전 확인
kubectl version

Master 확인
kubectl get componentstatus
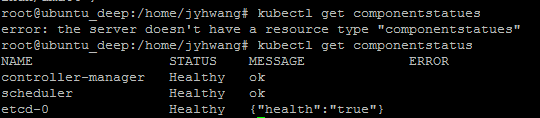
Node 확인
Node 확인
kubectl get nodes

Node 상세 정보 확인
kubectl describe nodes minikube
기본 정보 확인
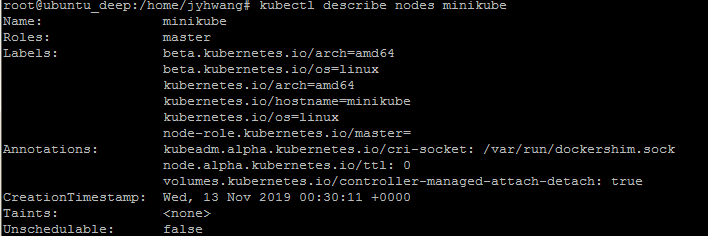
운영 정보 확인
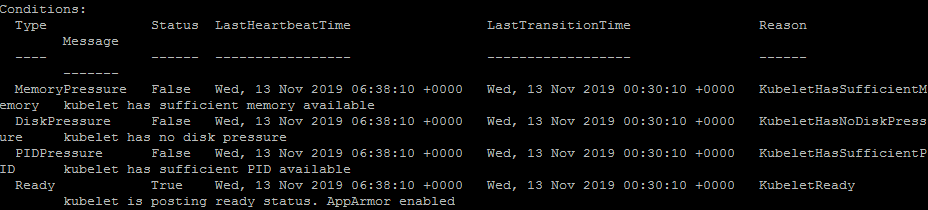
Network 정보 확인
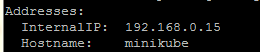
용량 정보 확인
System 정보 확인
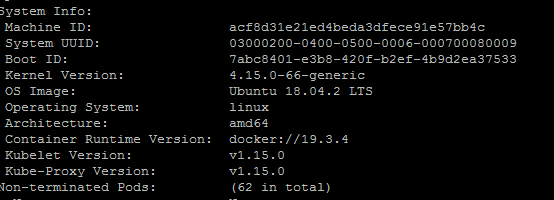
Pod 정보 확인
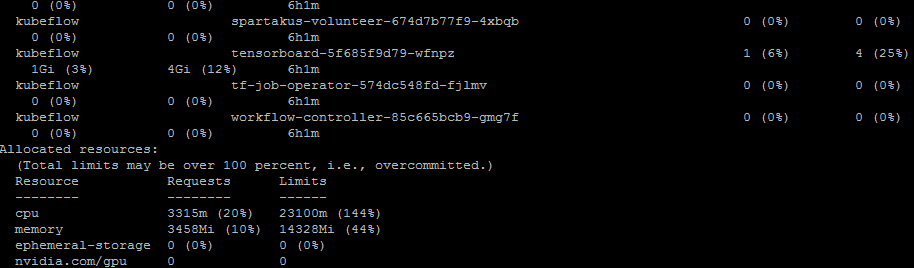
클러스터 구성 요소
Kubenetes proxy
namespace를 사용하여 지정한 namespace에 지정할 수 있는 것을 볼 수 있다.
kubectl get daemonSets --namespace=kube-system kube-proxy

Kubernetes DNS
kubectl get svc --namespace=kube-system kube-dns

Object 생성 업데이트 삭제
- Object 생성
kubectl apply -f <Object Spec(.yaml or .json)> - Object 업데이트
kubectl apply -f <Object Spec(.yaml or .json)> - Object 삭제
kubectl delete -f <Object Spec(.yaml or .json)>
디버깅 명령
컨테이너 로그 확인
describe로서 확인하였으나 더 자세한 내용을 살펴보기 위하여 log 출력
kubectl logs <pod name>

동작 중인 컨테이너에서 다른 명령을 실행
Docker와 같은 방식으로 작동
kubectl exec -it <포드 이름> --bash
컨테이너에서 Local 혹은 컨테이너로 파일 복사
kubectl cp <포드 이름>:/path/to/remote/file /path/to/local/file
명령어 확인
Kubectl 도움말
kubectl help
Kubectl 명령어 도움말
kubectl help <명령 이름>
Volume
Kubernetes는 Stateless Application을 사용한다.
즉, 컨테이너가 죽었을때 현재까지의 데이터가 사라진다는 것을 의미한다.
따라서 Volume을 통하여 Localhost 혹은 Cloud상에 저장소를 만들어두고 저장하는 방식을 사용한다.
또한, Kubernetes는 PV, PVC를 활용하여 자동으로 데이터가 있는 볼륨이 컨테이너가 새로 시작한 노드에 옮겨 붙여서 쌓아뒀던 데이터를 그대로 활용해서 사용할 수 있다.
사용가능한 Volume의 종류는 다음과 같다.
awsElasticBlockStore
azureDisk
azureFile
cephfs
configMap
csi
downwardAPI
emptyDir
fc (fibre channel)
flocker
gcePersistentDisk
gitRepo (deprecated)
glusterfs
hostPath
iscsi
local
nfs
persistentVolumeClaim
projected
portworxVolume
quobyte
rbd
scaleIO
secret
storageos
vsphereVolume
PV(PersistentVolume), PVC(PersistentVolumeClaim)
위에서도 언급하였지만 Kubernetes의 Volume은 크게 PV, PVC로 구성되어 있다.
PV는 Volume그 자체이다.
즉, 실질적으로 Data가 저장되는 물리적 혹은 Cloud상의 저장소이다. 이러한 PV는 클러스터내에서 리소스로 다뤄진다. Pod과 별개로 관리되고 별도의 생명주기를 가지고 있다.
PVC는 사용자가 PV에 하는 요청이다.
만들어진 PV에게 어떻게 사용할지 요청을 하는 방식이다. 사용하고 싶은 용량은 얼마인지 읽기/쓰기는 어떤 모드로 설정하고 싶은지등을 정해서 요청한다.
이러한 PV와 PVC를 분할하여 사용함으로써 각자의 상황에 맞게 다양한 스토리지를 사용할 수 있게 해준다.
Kubernetes는 이러한 PV와PVC를 직접 연결할 수도 있지만, 자동으로 최적의 PV와 PVC로 연결해주는 기능이 존재한다.
PV, PVC 생명 주기
그림 참조: arisu1000 블로그
Provisioning
PV를 만드는 단계이다.
PV를 미리 만들어두고 사용하는 정적(Static) 방법과 요청이 있을때마다 PV를 만드는 동적(dynamic)한 방법이 존재한다.
Binding
작성한 PVC에 알맞는 PV를 할당하는 단계이다.
만약 알맞은 PV가 없으면 요청은 실패하고 계속해서 대기하다가 새로운 PV가 생성되거나 기존에 사용되던 PV가 반납되는 경우 요청에 맞으면 Binding된다.
주의해야하는 점은 PV와 PVC의 매핑은 1대1 관계라는 것 이다.
여러개의 PVC가 여러개의 PV에 바인딩 되는 것은 불가능하다.
Using
Pod에서 PVC를 인식하고 PVC를 Volume으로 인식하여 사용하는 단계이다.
할당된 PVC는 시스템에서 임의로 삭제할 수 없다.
사용자가 임의로 PVC를 삭제하게 되면 Terminating상태가 되지만 이러한 PVC는 삭제되지 않고 남아있는 상태에서 Pod이 사용하지 못하는 상태로 바뀌는 것 이다.
Reclaiming
사용이 끝난 PVC를 삭제하고 PV를 초기화 하는 과정이다. PV초기화 과정은 3가지로 분류된다.

- Retain: PV를 그대로 보존한다.
- Delete: PV를 삭제하고 연계되어있는 외부 스토리지 쪽의 Volume도 삭제한다.
- Recycle: PV를 삭제하고 새로운 PVC에서 사용가능하게 만들어 둔다.
PV
위에서 Volume도 Object의 하나라고 설명하였다. 따라서 PV를 선언하는 경우 Object Spec을 작성하고 kubectl apply -f [object spec(.yaml or .json)]으로서 Object를 생성하게 된다.
PV 작성방법
PV Object를 생성하기 위해 다음과 같이 pv.yaml로서 Object Spec을 정의하였다고 하자.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-hostpath
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
storageClassName: manual
persistentVolumeReclaimPolicy: Delete
hostPath:
path: /tmp/k8s-pv
- kind: Object의 종류 지정 PV를 정의하므로 PersistentVolume으로 지정
- accessMode: Volume의 읽기/쓰기에 관한 옵션 지정
- ReadWriteOnce: 하나의 노드가 볼륨을 읽기/쓰기 가능하게 마운트 가능
- ReadOnlyMany: 여러개의 노드가 읽기 전용으로 마운트 가능
- ReadWriteMany: 여러개의 노드가 읽기/쓰기 가능하게 마운트 가능
- storageClassName: 특정 PV와 PVC를 연결하기 위하여 지정, 같은 Storage끼리 연결
- hostPath: 실제 Volume의 물리적 저장 장소
PV 상태
- Available: PVC에서 사용할 수 있게 준비된 상태
- Bound: 특정 PVC에 연결된 상태
- Released: PVC는 삭제된 상태이고 PV는 아직 초기화 되지 않은 상태
- Failes: 자동 초기화가 실패한 상태
PVC도 PV와 같은 Template로서 지정되나 중요한 것은 PVC는 실질적인 Volume을 의미하는 것이 아니므로 hostpath가 존재하지 않는다.
Service
Object에 관해 설명할때 Service는 Kubernetes의 Network를 관리하는 Object라고 정의하였다.
Service의 역할 중 가장 중요한 것은 개인적으로 여러 Pod에서 같은 Apllication을 운영하는 경우 Pod간의 로드벨런싱이다.
이러한 Service는 여러 Pod를 묶어서 로드 밸런싱이 가능하며, 고유한 DNS이름을 가질 수 있다.
Service Type
Service는 IP주소 할당 방식돠 연동 서비스등에 따라 크게 4가지로 구별할 수 있다.
- ClusterIP: Defualt설정으로, 서비스에 클러스터 IP(내부 IP)를 할당한다. 쿠버네스트 클러스터내에서는 이 서비스에 접근이 가능하지만, 클러스터 외부에서는 외부 IP를 할당 받지 못했기 때문에, 접근이 불가능하다.
- LoadBalancer: 클라우드 벤터에서 제공하는 설정 방식으로, 외부 IP를 가지고 있는 로드밸런서를 할당한다. 외부 IP를 가지고 있기 때문에, 클러스터 외부에서 접근이 가능하다.
- NodePort: 클러스터 IP로만 접근이 가능한 것이 아니라, 모든 노드의 IP와 포트를 통해서도 접근이 가능하다.
- ExternalName: 외부 서비스를 쿠버네티스 내부에서 호출하고자할때 사용할 수 있다. ClusterIP는 외부 IP를 할당받지 못하여 접근할 수 없다. ExternalName을 사용하면 Service로 들어오는 모든 요청을 특정 IP나 DNS로 Forwarding해준다. (일종의 프록시와 같은 역할)
Service 확인
먼저 모든 Service를 확인하여 보자.
kubectl get svc --all-namespaces
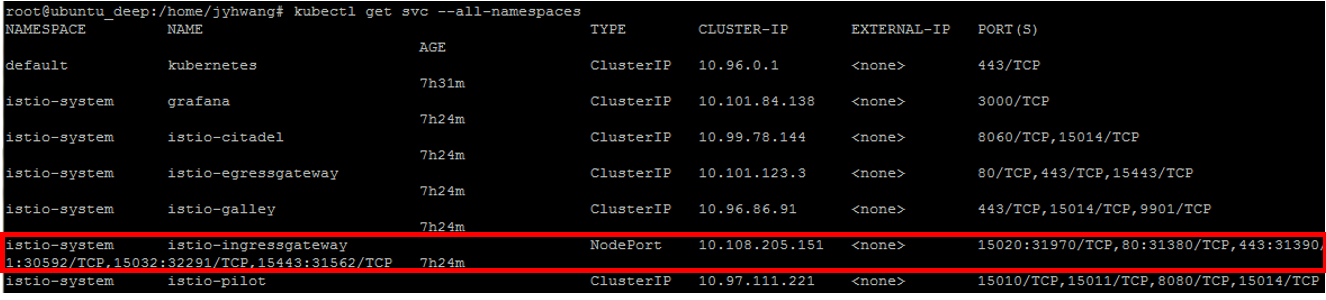
확인 결과 외부에서 접근 가능한 Service는 NodePort인 istio-ingressgateway뿐이다.
따라서 istio-ingressgateway를 살펴보면 다음과 같다.
kubectl describe svc -n istio-system istio-ingressgateway
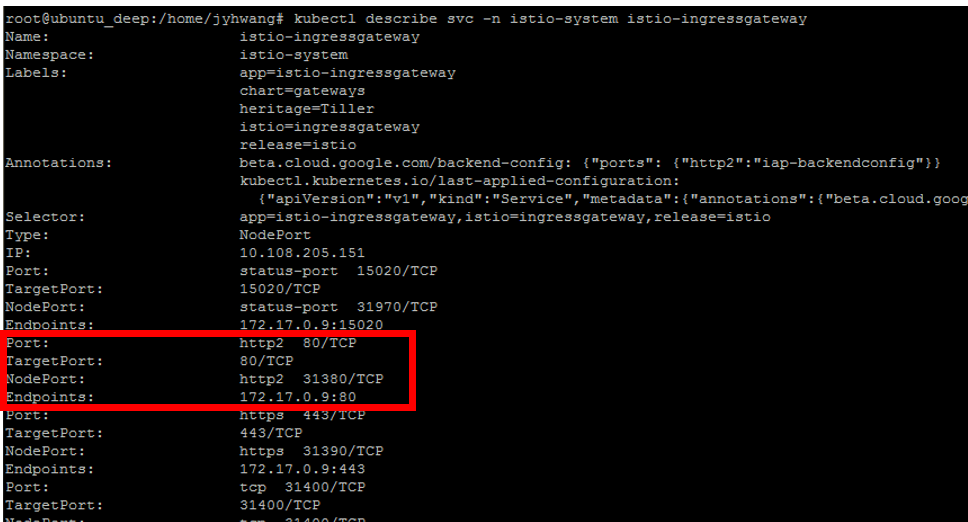
위의 결과에서 빨간색 박스를 친 부분을 확인하면 Nodeport 31380을 통하여 접속을하게 되면 TargetPort인 80번의 ClusterIP로 연결하는 것을 살펴볼 수 있다.
Service중에 ClusterIP이고 80/TCP를 사용하는 Service를 살펴보자
kubectl describe svc --all-namespaces | grep 80/TCP
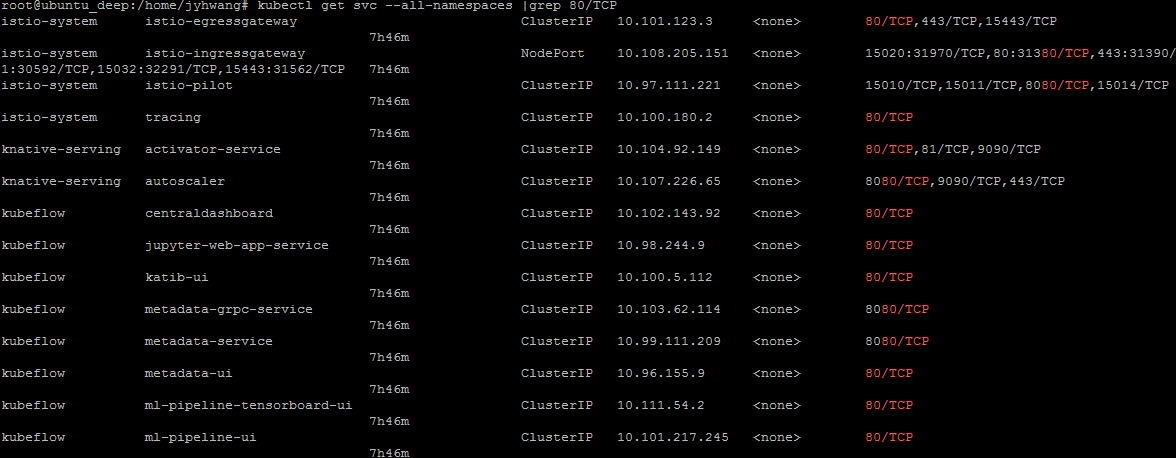
확인결과 많은 UI들이 연결되어 있는 것을 확인할 수 있다.
실제 IP에 접속하면 다음과 같다.
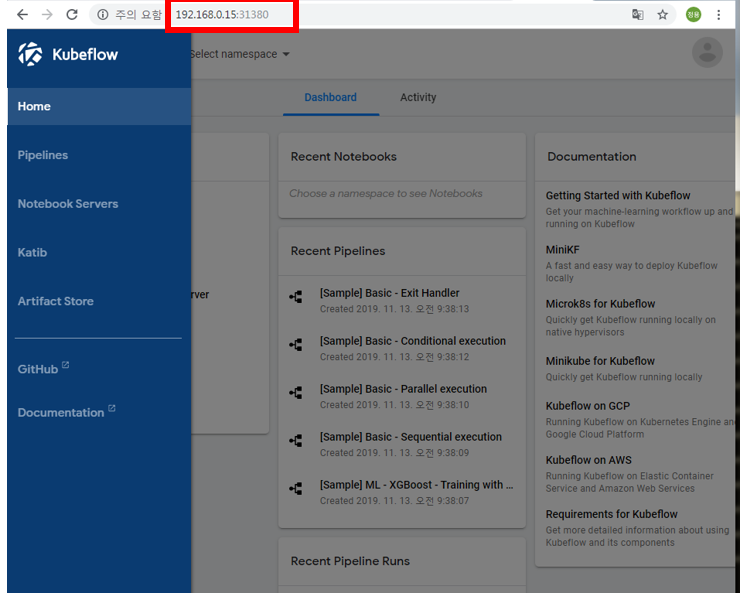
잘 연결되는것을 확인할 수 있다.
해당 Post는 Kubernetes에 관하여 매우 조금만 다루고 있습니다.
Kubeflow가 목적이지 Kubernetes자체가 목적이 아니여서 기본적인 Architecture와 구성요소 및 설치를 위한 사전 지식 정도만 다루고 있습니다.
더욱더 정확하고 많은 정보는 아래 링크를 참조하시면 됩니다.
참조:subicura 블로그
참조:Kubernetes
참조:조대협 블로그
참조:arisu1000 블로그
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment