
Pytorch-U-Net
U-Net
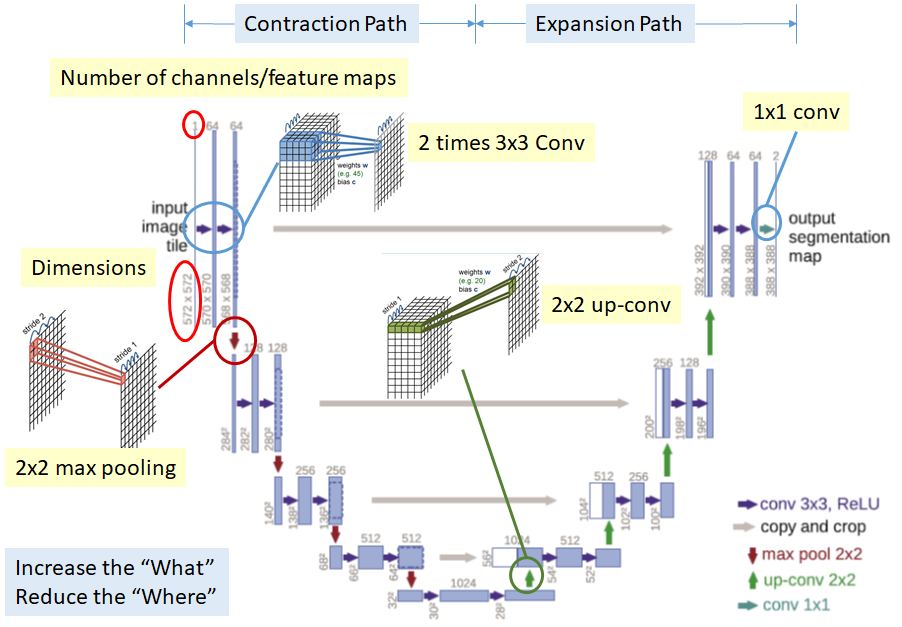
논문 링크: U-net
Semantic Segmentation의 가장 기본적으로 많이 사용하는 Model인 U-Net을 알아보자.
U-Net은 말 그대로 Model의 형태가 U자로 생겨서 U-Net이다.
대표적인 AutoEncoder로 구현한 Model중에 하나이다.
U-Net의 대표적인 특징은 3가지 이다.
- Contraction Path(Encoder)와 Expansion Path(Decoder)로 이루워진 Fully Convolution + Deconvolution의 구조를 가진 AutoEncoder Model이다.
- Expanding Path에서 Upsampling시 좀더 정확한 Localization을 하기 위하여 COntraction Path의 Feature map을 Copy and Crop하는 구조이다.
- Dataset이 적으므로 Trainning의 정확도를 올리기 위하여 Data Augmentaion을 통하여 Dataset을 가공하여 사용하였다.
Overlap Tile Strategy
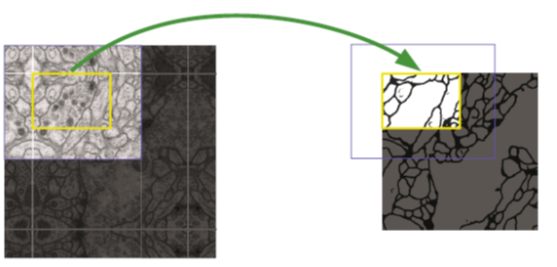
Overlap Tile Strategy는 unpaddes convolution을 실행함으로서 Output Size는 Input Size보다 작아지게 된다.
따라서 DownSizing 과 Upsampling시 Ovelap tile을 사용하게 된다.
Over Lap Tile은 다음과 같은 순서로 진행된다.
Image를 Patch 단위로 가져오기 위해서 가장자리 부분을 Mirroring하여 Padding을 추가한뒤 Patch단위로 자른다..
Mirroring을 자세히 보면 아래 그림과 같다.
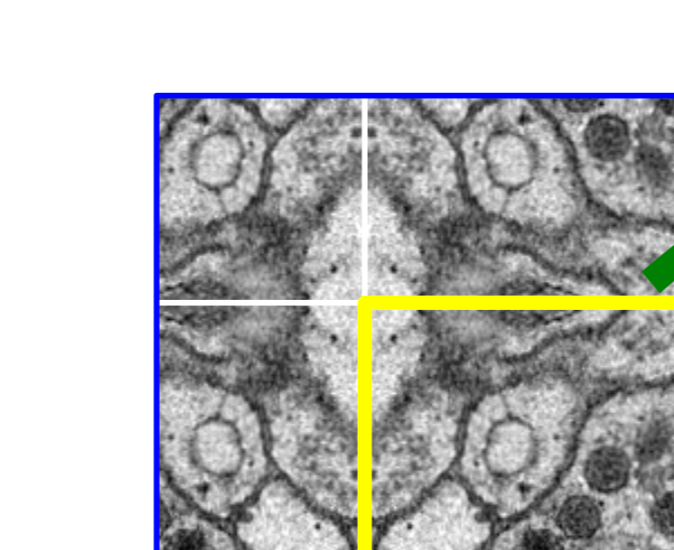
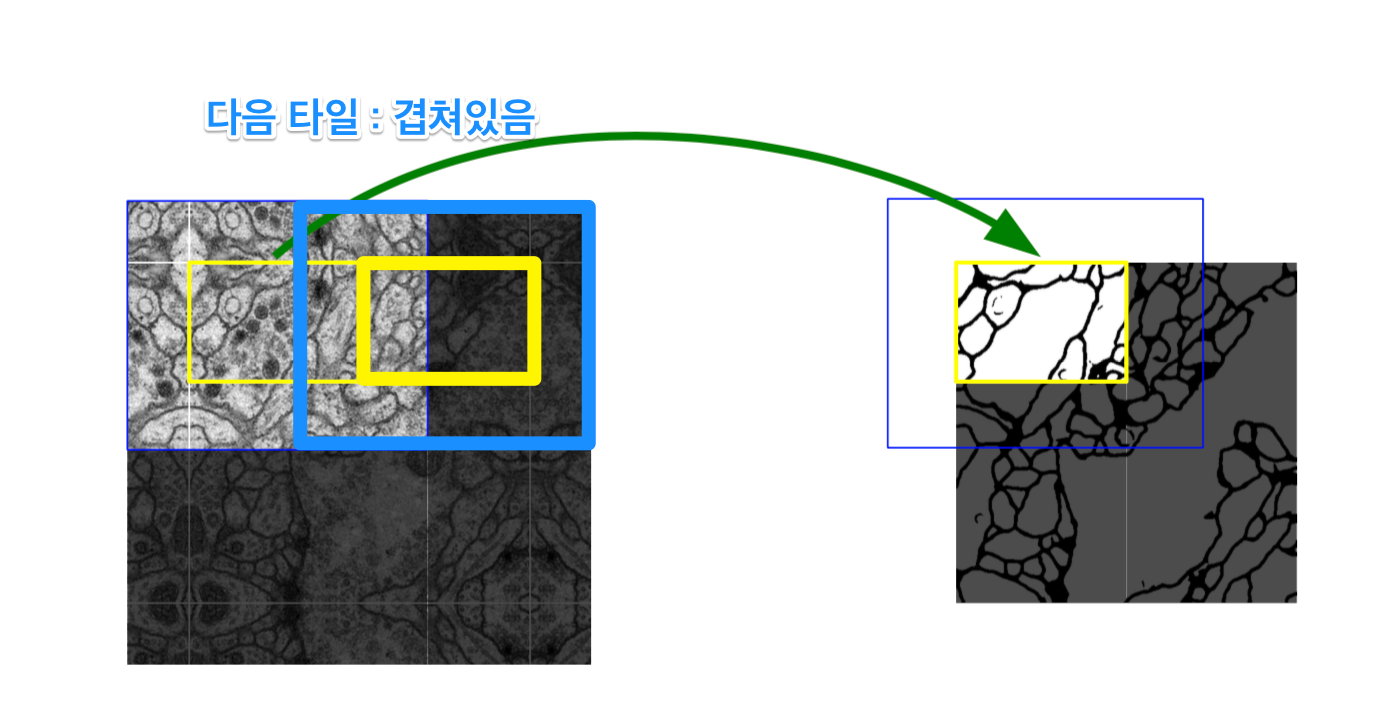
Boundary는 부자연 하므로 Patch에서 일정 부분만 Segmentation으로서 사용한다. 또한 Overlap이라고 불리는 이유는 아래와 같이 Tile이 겹쳐서 뽑아내기 때문이다.
Data Augmentaion
현재 논문에서 강조하는 Model의 성능향상을 종합해보면 크게 2가지라 할 수 있다.
- U-Net구조의 Model사용(Copy and Crop)
- Data Augmentation
이 중 Data Augmentation의 특징을 알아보자
현재 사용하고 있는 Biomedical Data의 경우 전문가에 의해 Annotation되어야 하므로 DataSet의 크기가 작을 수 밖에 없다.
따라서 이러한 부족한 수의 DataSet을 늘리는 방법을 Data Augmentaion이라 한다.
현재 사용하고 있는 Data의 Augmentaion을 Elastic Deformation을 사용하였다.
Elastic Deformation
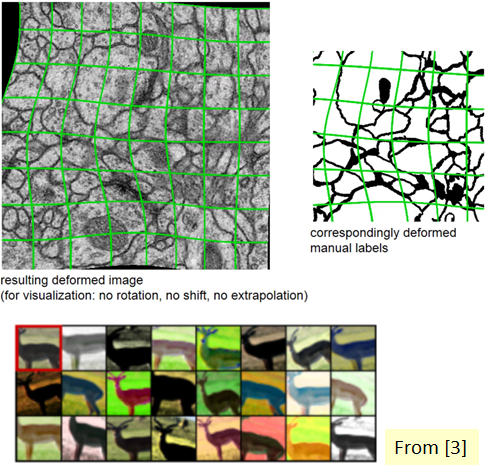
위와 같이 Elastic Deformation을 사용한 이유도 Biomedical Image의 특성때문이다.
Boundary를 직사각형으로 균등하게 자르는 경우 Boundary안에 정확한 Cell이 존재하지 않을 확률이 높다.
따라서 Elastic Deformation을 통하여 Boundary안에 Cell이 최대한 많이 분포하기 위해 처리해주는 과정이다.
Transformation Matrix자세한 내용
현재 전문적인 지식이 필요한 부분으로 인하여 미리 정제되어 있는 DataSet을 가져와 사용하였다.
아래 링크는 Data의 Input 과 Label을 DataAugmentaion을 하여 사용하는 과정까지 자세히 나와있는 링크이다.
아래 링크에서 Data Augmentaion된 Data를 활용하여 Model을 학습하였다.
데이터 출처: zhixuhao Git
필요한 Library Import
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from os import listdir
from os.path import isfile, join
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import torch
from torchvision import transforms, datasets
from torchvision.transforms import ToPILImage
import torch.nn as nn
import torch.utils as utils
import torch.nn.init as init
import torch.utils.data as data
import torchvision.utils as v_utils
import torchvision.datasets as dset
import torchvision.transforms as transforms
DataAugmentation 개수와 GPU 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
files = [f for f in listdir('./Data/aug') if isfile(join('./Data/aug', f))]
test_image_name = [x for x in files if x.find("image") != -1]
mask_image_name = [x for x in files if x.find("mask") != -1]
print('File 개수 확인')
print(len(test_image_name))
print(len(mask_image_name))
print('Deviece 확인')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
loader = transforms.Compose([
transforms.ToTensor()]) # 토치 텐서로 변환
def image_loader(image_name):
image = Image.open(image_name)
image = loader(image).unsqueeze(0)
return image.to(device, torch.float)
train = []
label = []
for i in range(len(test_image_name)):
image = image_loader('./Data/aug/' + test_image_name[i])
train.append(image)
for i in range(len(mask_image_name)):
image = image_loader('./Data/aug/' + mask_image_name[i])
label.append(image)
File 개수 확인
60
60
Deviece 확인
cuda:0
Image를 Tensor로 변환후 정보 확인
1
2
3
4
5
6
7
8
print('Train Image -> Tensor 확인')
print(len(train))
print(train[0].size())
print(train[0])
print('Label Image -> Tensor 확인')
print(len(label))
print(label[0].size())
print(label[0])
Train Image -> Tensor 확인
60
torch.Size([1, 1, 256, 256])
tensor([[[[0.8471, 0.6863, 0.6196, ..., 0.3882, 0.6196, 0.6078],
[0.8078, 0.7843, 0.6745, ..., 0.3608, 0.5059, 0.5922],
[0.7804, 0.8706, 0.7882, ..., 0.3725, 0.2941, 0.5373],
...,
[0.7647, 0.8157, 0.9020, ..., 0.3137, 0.2549, 0.3333],
[0.7176, 0.6824, 0.8000, ..., 0.2902, 0.3686, 0.2902],
[0.6588, 0.8667, 0.8039, ..., 0.2353, 0.3765, 0.5098]]]],
device='cuda:0')
Label Image -> Tensor 확인
60
torch.Size([1, 1, 256, 256])
tensor([[[[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.],
[0., 0., 0., ..., 1., 1., 1.]]]], device='cuda:0')
Tensor로 변환한 Image출력
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
unloader = transforms.ToPILImage()
def imshow(tensor, title=None):
image = tensor.cpu().clone() # 텐서의 값에 변화가 적용되지 않도록 텐서를 복제합니다
image = image.squeeze(0) # 페이크 배치 차원을 제거 합니다
image = unloader(image)
plt.imshow(image)
test_image_example = plt.subplot(1,2,1)
test_image_example.set_title('Test Image Example')
imshow(train[0])
label_image_example = plt.subplot(1,2,2)
label_image_example.set_title('Label Image Example')
imshow(label[0])
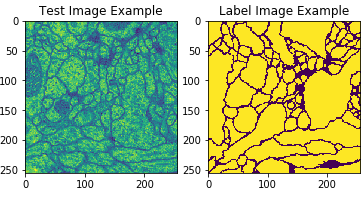
Batch처리를 위하여 Data를 BatchSize = 2 로서 묶는 과정
1
2
3
4
5
6
7
8
9
10
11
train_batch = []
label_batch = []
batch_size = 2
for i in range(0,len(train),batch_size):
train_batch.append(torch.cat([train[i],train[i+1]]))
for i in range(0,len(label),2):
try:
label_batch.append(torch.cat([label[i],label[i+1]]))
except:
pass
최종 Train에 사용할 Data 정보 확인
1
2
3
4
5
print('Batch 개수 확인')
print(len(train_batch))
print(len(label_batch))
print('Batch Tensor 정보 확인')
print(label_batch[0].size())
Batch 개수 확인
30
30
Batch Tensor 정보 확인
torch.Size([2, 1, 256, 256])
Model
Model을 단순하게 살펴보면 다음과 같다.
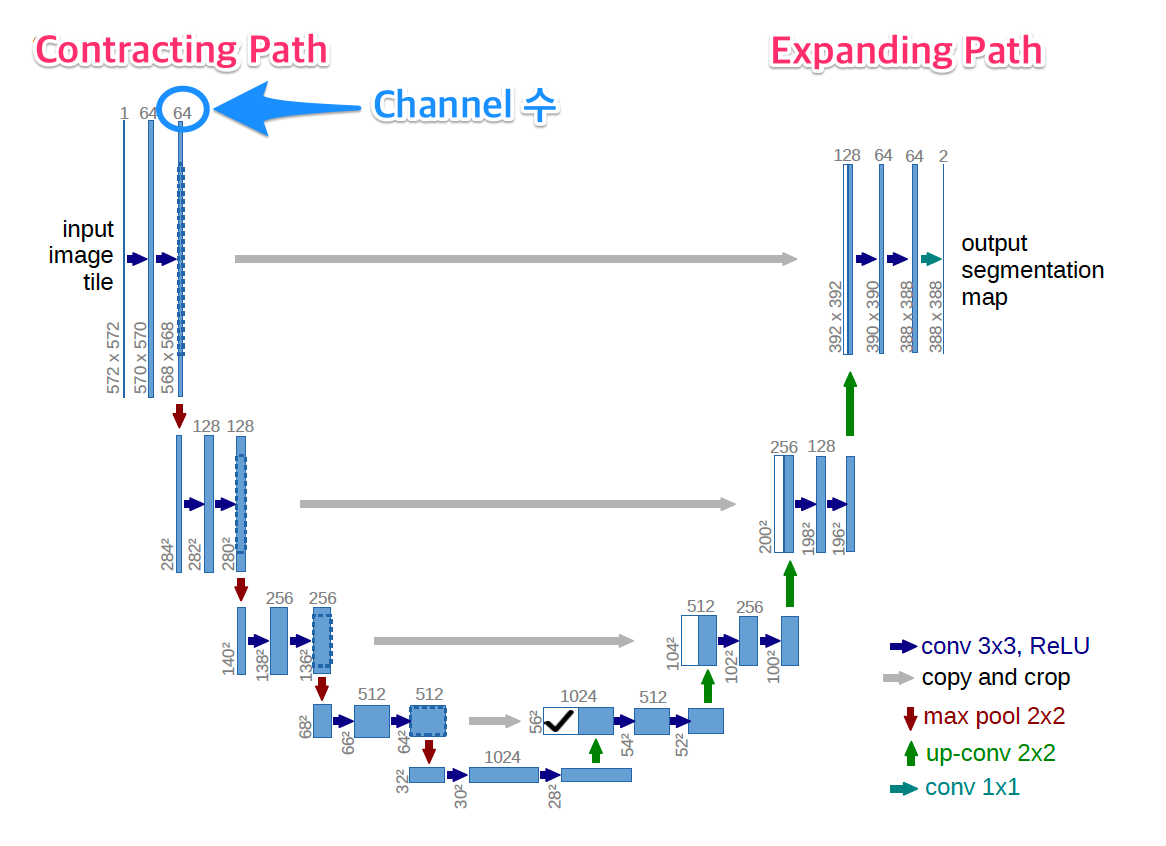
Model의 Encoder부분인 Contracting Path와 Decoder부분인 Expanding Path부분으로 크게 두가지고 나눌 수 있다. 각각의 특징을 살펴보면 다음과 같다.
Contracting Path
- Fully Connected Convolution Networ구조
- 3 x 3 Convolution을 반복 수행
- Activation Function: ReLU
- 2 x 2 Max Pooling: Stride 2를 사용하여 1/2로 Scaling
- Downsampling 시에는 2배의 Feature Channel사용
Contracting Path로 인하여 64 Channel의 Input Image는 1024의 Channel로서 향상 될 수 있다.
이러한 늘어난 Encoder의 Output만을 사용하는 것은 전체적인 Image의 Feature를 가져올 수 없다는 단점이 생기게 된다.
따라서 Upsampling시 Copy and Crop을 사용하여 같은 Channel인 Contracting Path의 Feature Map을 붙여서 Input으로 활용하는 것을 알 수 있다.
One important modification in our architecture is that in the upsampling part we have also a large number of feature channels, which allow the network to propagate context information to higher resolution layers. As a consequence, the expansive path is more or less symmetric to the contracting path, and yields a u-shaped architecture
Expanding Path
- 2 x 2 convolution(up-convolution)
- Feature channel을 반으로 줄여서 사용
- Contracting Path에서 Max-Pooling 되기 전의 Feature map을 Crop하여 Up-Convolution할 때 Concatenation을 수행
- 3 x 3 Convolution 반복
- ReLu사용
여기서 가장 중요한 것은 AutoEncoder의 구조이지만 Input Image의 전체적인 특성을 가져오기 위하여 Contracting Path의 중간중가 결과물인 Feature Map을 Copy and Crop한다는 것 이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 자주 쓰는 연산들과 항상 세트로 쓰는 연산들은 편의를 위해 함수로 정의해 놓습니다.
def conv_block(in_dim,out_dim,act_fn):
model = nn.Sequential(
nn.Conv2d(in_dim,out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def conv_trans_block(in_dim,out_dim,act_fn):
model = nn.Sequential(
nn.ConvTranspose2d(in_dim,out_dim, kernel_size=3, stride=2, padding=1,output_padding=1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def maxpool():
pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
return pool
def conv_block_2(in_dim,out_dim,act_fn):
model = nn.Sequential(
conv_block(in_dim,out_dim,act_fn),
nn.Conv2d(out_dim,out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),
)
return model
Copy and Crop
개인적으로 U-net에서 가장 중요한 부분이다.
U-net에서 가장 중요한 부분인 Copy and Crop을 다음과 같이 구현하였다.
concat_1 = torch.cat([trans_1,down_4],dim=1)
up_1 = self.up_1(concat_1)
위의 Code를 보게 되면 Contraction Path에서 뽑아낸 Feature Map을 합쳐서 Input으로 들어가는 것을 확인할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
class UnetGenerator(nn.Module):
def __init__(self,in_dim,out_dim,num_filter):
super(UnetGenerator,self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.num_filter = num_filter
act_fn = nn.LeakyReLU(0.2, inplace=True)
print("\n------Initiating U-Net------\n")
self.down_1 = conv_block_2(self.in_dim,self.num_filter,act_fn)
self.pool_1 = maxpool()
self.down_2 = conv_block_2(self.num_filter*1,self.num_filter*2,act_fn)
self.pool_2 = maxpool()
self.down_3 = conv_block_2(self.num_filter*2,self.num_filter*4,act_fn)
self.pool_3 = maxpool()
self.down_4 = conv_block_2(self.num_filter*4,self.num_filter*8,act_fn)
self.pool_4 = maxpool()
self.bridge = conv_block_2(self.num_filter*8,self.num_filter*16,act_fn)
self.trans_1 = conv_trans_block(self.num_filter*16,self.num_filter*8,act_fn)
self.up_1 = conv_block_2(self.num_filter*16,self.num_filter*8,act_fn)
self.trans_2 = conv_trans_block(self.num_filter*8,self.num_filter*4,act_fn)
self.up_2 = conv_block_2(self.num_filter*8,self.num_filter*4,act_fn)
self.trans_3 = conv_trans_block(self.num_filter*4,self.num_filter*2,act_fn)
self.up_3 = conv_block_2(self.num_filter*4,self.num_filter*2,act_fn)
self.trans_4 = conv_trans_block(self.num_filter*2,self.num_filter*1,act_fn)
self.up_4 = conv_block_2(self.num_filter*2,self.num_filter*1,act_fn)
self.out = nn.Sequential(
nn.Conv2d(self.num_filter,self.out_dim,3,1,1),
nn.Tanh(), #필수는 아님
)
def forward(self,input):
down_1 = self.down_1(input)
pool_1 = self.pool_1(down_1)
down_2 = self.down_2(pool_1)
pool_2 = self.pool_2(down_2)
down_3 = self.down_3(pool_2)
pool_3 = self.pool_3(down_3)
down_4 = self.down_4(pool_3)
pool_4 = self.pool_4(down_4)
bridge = self.bridge(pool_4)
trans_1 = self.trans_1(bridge)
concat_1 = torch.cat([trans_1,down_4],dim=1)
up_1 = self.up_1(concat_1)
trans_2 = self.trans_2(up_1)
concat_2 = torch.cat([trans_2,down_3],dim=1)
up_2 = self.up_2(concat_2)
trans_3 = self.trans_3(up_2)
concat_3 = torch.cat([trans_3,down_2],dim=1)
up_3 = self.up_3(concat_3)
trans_4 = self.trans_4(up_3)
concat_4 = torch.cat([trans_4,down_1],dim=1)
up_4 = self.up_4(concat_4)
out = self.out(up_4)
return out
Loss and Optimizer
Optimizer
Optimizer의 경우 SGD를 사용하고 Batch size를 크게해서 학습시키는 것 보다 Input Tile의 size를 크게 주는 방법을 선택하였다.
이에 관련된 이유는 Image를 일정 크기(Patch)로서 자르게 되는데 너무 작게 자르게 되는 경우 Image자체의 Context의 의미가 없어지므로 이러한 선택을 하였다.
이러한 Batch Size가 작기 때문에, 이를 보안하고자 momentum의 값을 0.99를 주어서 과거의 겂들을 더 많이 반영하게 하여 학습이 진행하도록 하였다.
Loss Function
Biomedical Image의 특성상 Cell이 서로 인접하여서 구분하기 힘든 특징이 있다.
각각의 Cell과 배경은 잘 구분되는 특징은 있지만, 각각의 Cell이 구분되지 않는 특징이 존재하게 된다.
이러한 특성 때문에 서로 붙어있는 물체를 쉽게 합치고 떨어뜨리기 위하여, Weight map을 추가하여 Network의 Output을 결정하게 된다.
- \(d_1(x)\): 가장 근접한 Cell의 경계와의 거리
- \(d_2(x)\): 두번째로 근접한 Cell의 경계와의 거리 \(w(x) = w_c(x) + w_0 * exp(-\frac{(d_1(x) + d_2(x))^2}{2\alpha^2})\)
이러한 Weight Map을 통하여 Loss Function을 정의하게 되면 Cross Entropy를 사용할 시 다음과 같이 나타낼 수 있다. \(E = \sum_{x \in \Omega}w(x)log(p_{l(x)}(x))\)
위와 같은 결과로서 얻는 Image의 변환은 아래와 같다.

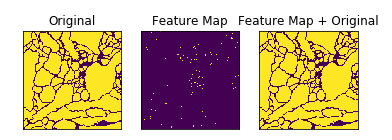
위의 사진에서도 알 수 있듯이 Cell이 인접해 있으면, 각 셀과 배경을 구분하도록 둘 사이에 배경으로 인식할 틈을 만들겠다는 의미이다.
간단한 w_c(x) 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def imshow2(tensor, title=None):
image = tensor.cpu().clone() # 텐서의 값에 변화가 적용되지 않도록 텐서를 복제합니다
image = image.squeeze(0) # 페이크 배치 차원을 제거 합니다
image = unloader(image)
return image
img = imshow2(label[0])
img_numpy = np.array(img)
print('img_numpy Check')
print(img_numpy)
kernel = np.ones((3,3),np.uint8)
result = cv2.morphologyEx(img_numpy/255, cv2.MORPH_TOPHAT, kernel)
print('After Kernel Check')
print(result)
plt.subplot(131),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(132),plt.imshow(result),plt.title('Feature Map')
plt.xticks([]), plt.yticks([])
plt.subplot(133),plt.imshow(img+result),plt.title('Feature Map + Original')
plt.xticks([]),plt.yticks([])
plt.show()
img_numpy Check
[[255 255 255 ... 255 255 255]
[255 255 255 ... 255 255 255]
[255 255 255 ... 255 255 255]
...
[255 0 0 ... 255 255 255]
[ 0 0 0 ... 255 255 255]
[ 0 0 0 ... 255 255 255]]
After Kernel Check
[[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[1. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]
Hyper Parameter 및 Model, Loss 선언
원래 Loss는 아래와 같다. Weight Map
- \(d_1(x)\): 가장 근접한 Cell의 경계와의 거리
- \(d_2(x)\): 두번째로 근접한 Cell의 경계와의 거리
Loss Function
이러한 Weight Map을 통하여 Loss Function을 정의하게 되면 Cross Entropy를 사용할 시 다음과 같이 나타낼 수 있다.
\(E = \sum_{x \in \Omega}w(x)log(p_{l(x)}(x))\)
현재 Weight Map에서 가장 인접한 Cell과의 거리를 어떻게 해야할 지 몰라서 간단한 Weight Map만 구하였다.
즉 식은 아래와 같이 바뀌게 된다.
\(w(x) = w_c(x) + w_0 * exp(-\frac{(d_1(x) + d_2(x))^2}{2\alpha^2})\)
또한 Loss Function도 MSE를 사용하여 아래와 같이 식이 변하게 된다.
\(E = \sum{(y - (\hat{y} + w_c(x)))^2}\)
나중에 OpenCV를 공부후 각각의 Cell사이의 거리를 구할 수 있게 되면 다시 구현하는 것을 목표로 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
img_size = 256
in_dim = 1
out_dim = 1
num_filters = 64
num_epoch = 3000
lr = 0.001
# 앞서 정의한대로 vGG 클래스를 인스턴스화 하고 지정한 장치에 올립니다.
model = model = UnetGenerator(in_dim=in_dim,out_dim=out_dim,num_filter=num_filters).to(device)
# 손실함수 및 최적화함수를 설정합니다.
loss_func = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.99)
------Initiating U-Net------
Model Trainning
1
2
3
4
5
6
7
8
9
10
11
12
13
14
for i in range(num_epoch):
for j in range(len(train_batch)):
x = train_batch[j]
y_= label_batch[j]
optimizer.zero_grad()
output = model.forward(x)
loss = loss_func(output,y_)
loss.backward()
optimizer.step()
if i % 100 ==0:
print(loss.item())
0.3214595317840576
0.07401763647794724
0.03947801887989044
...
0.0001458041660953313
0.00013882409257348627
0.0001401940535288304
Test 결과 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
test = []
output = []
for i in range(30):
image = image_loader('./Data/test/' + str(i) + '.png')
test.append(image)
with torch.no_grad():
for i in range(len(test)):
output.append(model.forward(test[i]))
if i % 10 == 0:
print(loss.item())
for i in range(5):
test_image_example = plt.subplot(1,2,1)
test_image_example.set_title('Test Image: ' + str(i))
imshow(test[i])
result_image_example = plt.subplot(1,2,2)
result_image_example.set_title('Result Image: ' + str(i))
imshow(output[i])
plt.show()
0.0001578749215696007
0.0001578749215696007
0.0001578749215696007
...
0.003879855154082179
0.0062858411110937595
0.01764284074306488
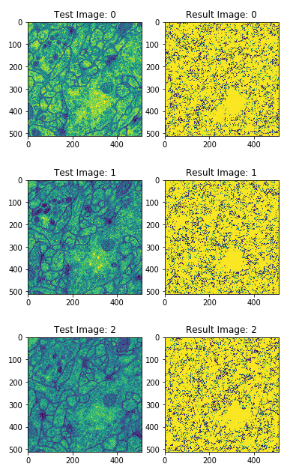
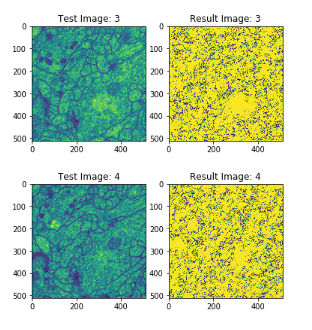
현재 U-Net의 Loss Function을 논문에서 제시한 Weight Cross Entropy가 아닌 MSE로 구현하였기 때문에 Loss는 적어도 만족하지 못한 결과를 얻었다.
OpenCv를 공부 후 Image처리를 통하여 다시 Loss Function을 구현 후 확인해 봐야하는 사항이다.
참조: 원본코드
참조: U-Net: Convolutional Networks for Biomedical Image Segmentaion
참조: Openresearch.ai
참조: Towardsdatascience
참조: 모두의 연구소
참조: 파이토치 첫걸음
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment