
R-군집화
군집화(Clustering)
비슷한 개체끼리 한 그룹으로, 다른 개체는 다른 그룹으로 묶어서 구분하는 것을 의미한다.
Unsupervised Learning.
- 계층적 군집분석
거리로서 군집을 분류하며 거리를 어떻게 연결하냐에 따라 단일연결법, 완전연결법, 평균연결법으로 나누어지게 된다.
- 단일연결법: 두 집단간의 최단거리 사용
- 완전연결법: 두 집단간의 최장거리 사용
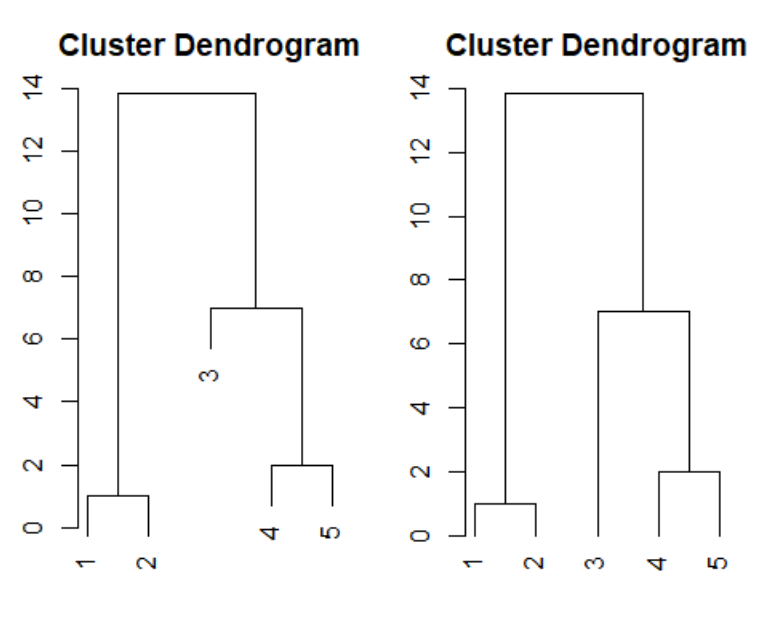
- 평균연결법: 두 집단간의 모든 개체들 사이의 거리의 평균을 사용
- 비계층적 군집분석: K-means Clustering
대량의 자료를 빠르게 분류할 수 있으나 군집의 수를 미리 정해주어야 한다.
계층적 군집분석
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#Clustering
#데이터 생성
x<-c(1,2,2,4,5)
y<-c(1,1,4,3,4)
xy<-data.frame(cbind(x,y))
#단일 연결법
hc_sl<-hclust(dist(xy)^2,method = 'single')
plot(hc_sl)
#완전 연결법
hc_cl<-hclust(dist(xy)^2,method = 'complete')
plot(hc_cl)
par(oma=c(3,1,1,0))
par(mfrow=c(1,2))
plot(hc_cl)
plot(hc_cl,hang = -1)
#평균 연결법
hc_avg<-hclust(dist(xy)^2,method = 'average')
plot(hc_avg)
par(oma=c(3,1,1,0))
par(mfrow=c(1,2))
plot(hc_avg)
plot(hc_avg,hang = -1)
결과-단일연결법:
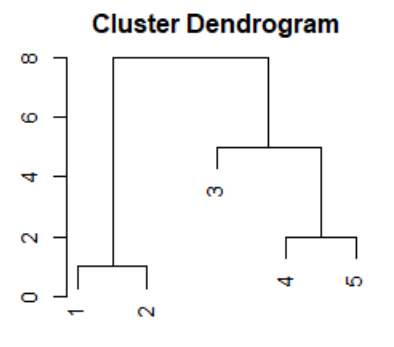
결과-완전연결법:
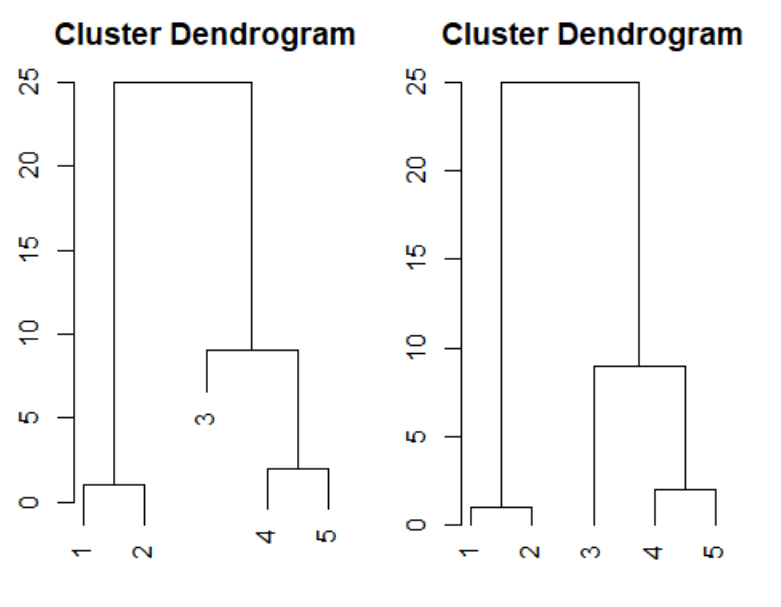
결과-평균연결법:
K-Means-Clustering
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#K-Means-Clustering
#데이터 만들기
install.packages("NbClust")
library(NbClust)
iris_s<-scale(iris[-5])
#Model 만들기
iris_k<-kmeans(iris_s,centers=3,iter.max = 100)
iris_k
#Model 시각화 하기
library(cluster)
iris_p<-pam(iris_s,3)
names(iris_p)
table(iris_p$clustering)
clusplot(iris_p)
결과-Model:

결과-Model 시각화:
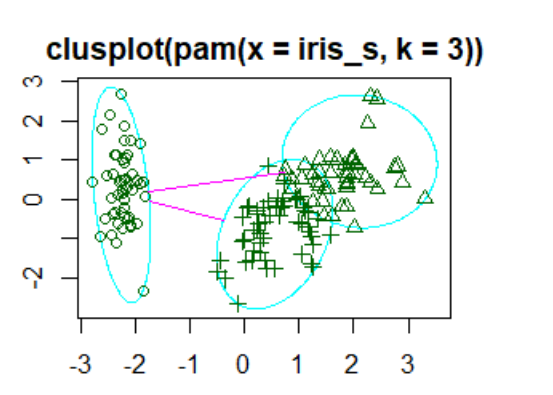
참조: 원본코드
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment