
R-시각화 심화
데이터 시각화 심화
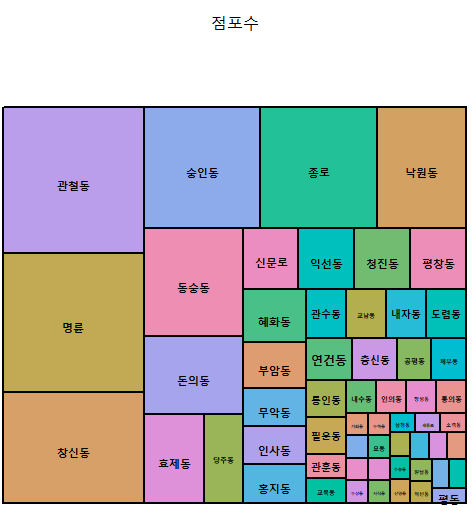
이미지맵: 데이터의 크기에 따라 크기를 달리하여 표현하는 방법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#엑셀자료 가공 후 동별 호프통닭집 건수로 이미지맵 출력
install.packages("readxl")
library(readxl)
ck<-read_excel("C:/git/R/Data/Restaurant.xlsx")
ck
typeof(ck) #"list"
ck<-as.data.frame(ck)
ck
class(ck) #"data.frame"
head(ck) #1~6행까지만 출력
addr<-substr(ck$주소3,1,3)
head(addr) #"창신동" "동숭동" "관수동" "관철동" "관철동" "명륜2"
addr<-gsub("[0-9]","",addr) #숫자제거
addr<-gsub(" ","",addr) #공백제거
head(addr)
str(addr)
library(dplyr)
addr_count<-addr%>%table()%>%data.frame() #table(): 빈도수 표현
addr_count
class(addr_count)
colnames(addr_count)<-c("동이름","점포수")
head(addr_count)
install.packages("treemap")
library(treemap)
treemap(addr_count, index="동이름", vSize="점포수")
arrange(addr_count, desc(점포수))%>%head(10)
출력결과
워드클라우드: 핵심단어를 시각화 하는 기법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#wordcloud
Sys.setenv(JAVA_HOME="C:/Program Files/Java/jre1.8.0_181")
library(rJava)
library(KoNLP)
library(tm)
install.packages("wordcloud")
data<-readLines("C:/git/R/Data/wordclo.txt")
data
data2<-sapply(data,extractNoun,USE.NAMES = F)
data2
typeof(data2) #"list"
data3<-unlist(data2)
data3
typeof(data3) #"character"
head(data3)
data3<-gsub('[~!@#$%^&*()_+=-<>?]','',data3)
data3<-gsub('\\d+','',data3)
data3<-gsub('-','',data3)
data3<-gsub(' ','',data3)
data3<-base::Filter(function(x){nchar(x)>=2},data3)
data3
typeof(data3) #"character"
write(data3,"testdata/wordclo_my.txt")
data4<-read.table("testdata/wordclo_my.txt")
head(data4)
word<-table(data4)
head(sort(word,decreasing = T))
data4<-gsub('서울시','',data4)
library(wordcloud)
display.brewer.all()
pal<-brewer.pal(9,"Set3")
windowsFonts(font=windowsFont("돋움"))
wordcloud(names(word),freq = word
,min.freq=1,max.words = 50,
random.order = F,random.color = T,colors = pal)
출력결과

Twitter API: 트위터 API를 활용하여 크롤링한 내용을 워드클라우드로 나타내기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
install.packages("twitteR")
library(twitteR)
ConsumerAPIkey="m2PXgAaSzuzqUPyQ4CquzkxHV"
ConsumerAPIsecretkey="wMTUWgTe2cWyQL7CZ5oFQDzZhKvDL6ZNbakH5MCzp2DYBqbuWS"
Accesstoken="129432628-LOU1w4ge22Jy3uCtDk40nYn5T5f8pElr3va29Tam"
Accesstokensecret="WMBnj0rXiUXhgP1KejMRUp1EVxdkSzNXL3Rnejh4qVitl"
setup_twitter_oauth(ConsumerAPIkey,ConsumerAPIsecretkey,Accesstoken,Accesstokensecret)
keyword <- enc2utf8("막걸리") #검색어 넣기
keyword
bigdata <- searchTwitter(keyword, n=100, lang="ko")
head(bigdata) #메시지 내용 그대로 읽어들이기
bigdata_df<-twListToDF(bigdata)
head(bigdata_df,3)
str(bigdata_df)
bigdata_txt<-bigdata_df$text
head(bigdata_txt,3)
library(KoNLP)
bigdata_noun<-sapply(bigdata_txt, extractNoun, USE.NAMES = F)
bigdata_noun<-unlist(bigdata_noun)
head(bigdata_noun)
#제거할 문자열
bigdata_noun<-gsub('[~!@#$%^&*()_+=-<>?]','',bigdata_noun)
bigdata_noun<-gsub('\\d+','',bigdata_noun)
bigdata_noun<-gsub('(ㅠ|ㅜ|ㅋ|ㅎ)+','',bigdata_noun)
bigdata_noun<-gsub('-','',bigdata_noun)
bigdata_noun<-gsub(' ','',bigdata_noun)
bigdata_noun<-base::Filter(function(x){nchar(x)>=2},bigdata_noun)
head(bigdata_noun) #단어 추출
word_table<-table(bigdata_noun)
word_table #단어 추출하여 wordtable로 출력하기
install.packages("wordcloud2")
library(wordcloud2)
wordcloud2(word_table,size=5,color="random-light",backgroundColor = 'black')
출력결과

참조: 원본코드
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment