
Tensorflow-AutoEncoder
AutoEncoder
AutoEncoder 은 아래의 그림과 같이 단순히 입력을 출력으로 복사하는 신경 망(비지도 학습) 이다.

Hidden Layer의 뉴런 수를 Input Layer 와 Output Layer의 뉴런 수보다 적게 설정하여 입력받은 원본 데이터에서 불필요한 특징들을 제거한 압축된 특징을 학습하게 되는것이 특징이다.
즉, Trainning 과정에서 불필요한 특징들을 자동적으로 제거하고 필요한 특징들만 남아있게 된다.
이러한 AutoEncoder의 특징으로 인하여 AutoEncoder의 핵심은 재구축된 출력층의 출력값이 아니라, 은닉층의 출력값 이다.
이번 Post에서 구현한 AutoEncoder의 경우 크게 두가지로 구별할 수 있게 된다.
Stacked AutoEncoder
Stacked AutoEncoder는 여러개의 히든 레이어를 가지는 Auto Encoder이며, 레이어를 추가할수록 AutoEncoder가 더 복잡한 코딩을 학습할 수 있다.
Stacked AutoEncoder는 아래의 그림과 같이 가운데 히든레이어를 기준으로 대칭인 구조를 가진다.
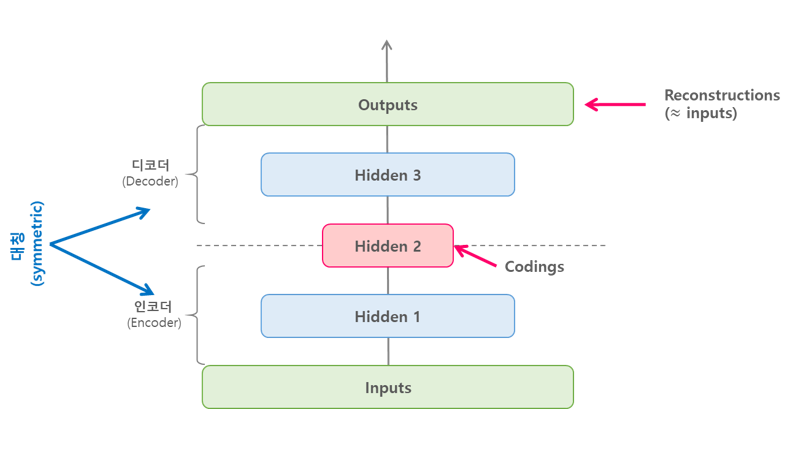
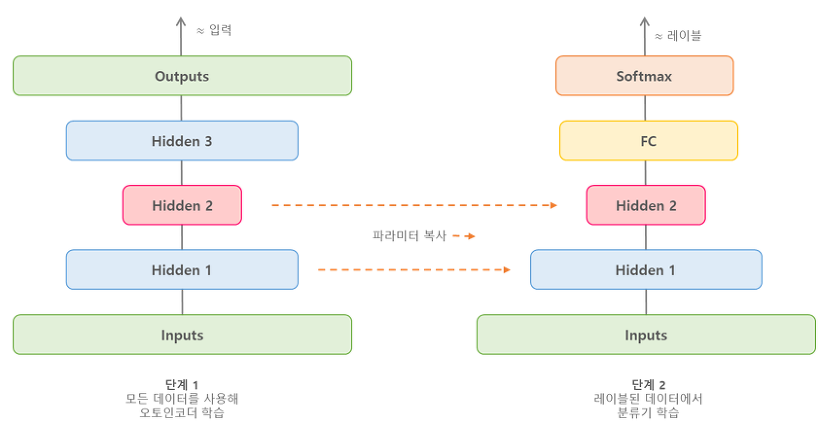
Stacked AutoEncoder를 이용한 비지도 사전학습
먼저 전체 데이터를 사용해 Stacked AutoEncoder를 학습시킨다.
그런 다음 AutoEncoder의 하위 레이어를 재사용해 분류와 같은 실제 문제를 해결하기 위한 신경망을 만들고 레이블된 데이터를 사용해 학습시킬 수 있다.
이러한 학습된 Layer에 parameter를 복사하여 사용하는 기술을 파이튜닝(Fine-Tuning) 혹은 전이학습(Transfer learning)이라고 불린다.
그외에 다양한 AutoEncoder에 관한 자세한 내용은 아래 링크를 참조
AutoEncoder 의 종류과 설명
Stacked AutoEncoder 구현
Stacked AutoEncoder 또한 앞선 Post에서 다룬 내용과 같이 MNIST Data를 분리하는 예제를 사용한다.
필요한 라이브러리를 import
1
2
3
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
학습에 사용할 MNIST 데이터를 다운받고 불러온다.(One-Hot-Encoding O)
1
2
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
학습을 위한 Parameter 선언
- training_epochs: 반복 횟수
- batch_size: 배치 개수
- display_step: 손실 함수 출력 주기
- examples_to_show: 보여줄 MNIST Reconstruction 이미지 개수
1
2
3
4
5
6
7
8
learning_rate = 0.02
training_epochs = 50
batch_size = 256
display_step = 5
examples_to_show = 10
input_size = 784
hidden1_size = 256
hidden2_size = 128
입력값과 출력값을 받기 위해 Placeholder 선언
출력값의 경우 입력값과 같으므로 따로 선언할 필요가 없다.(비지도 학습)
1
x = tf.placeholder(tf.float32, shape = [None, input_size])
Stacked AutoEncoder Model 정의
- input(784) -> Encoder(hidden1: 256 -> hidden2: 128) -> Decoder(hidden3: 256) -> output(784)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def build_autoencoder(x):
#Encoding: 784 -> 256 -> 128
W1 = tf.Variable(tf.random_normal(shape = [input_size, hidden1_size]))
b1 = tf.Variable(tf.random_normal(shape =[hidden1_size]))
H1_output = tf.nn.sigmoid(tf.matmul(x,W1)+b1)
W2 = tf.Variable(tf.random_normal(shape = [hidden1_size,hidden2_size]))
b2 = tf.Variable(tf.random_normal(shape =[hidden2_size]))
H2_output = tf.nn.sigmoid(tf.matmul(H1_output,W2)+b2)
#Decoding: 128 -> 256 -> 784
W3 = tf.Variable(tf.random_normal(shape = [hidden2_size, hidden1_size]))
b3 = tf.Variable(tf.random_normal(shape =[hidden1_size]))
H3_output = tf.nn.sigmoid(tf.matmul(H2_output,W3)+b3)
W4 = tf.Variable(tf.random_normal(shape = [hidden1_size,input_size]))
b4 = tf.Variable(tf.random_normal(shape =[input_size]))
reconstructed_x = tf.nn.sigmoid(tf.matmul(H3_output,W4)+b4)
return reconstructed_x
실제 AutoEncoder Model 선언
Target Data선언(input data와 같다.)
1
2
y_pred = build_autoencoder(x)
y_true = x
- Loss Function: MSE
- Optimazer: RMSProp
1
2
loss = tf.reduce_mean(tf.pow(y_true - y_pred,2))
train_step = tf.train.RMSPropOptimizer(learning_rate).minimize(loss)
세션 생성 및 실행
Model 성능 Test
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
with tf.Session() as sess:
#변수 초기화
sess.run(tf.global_variables_initializer())
#지정한 횟수만큼 최적화 수행
for epoch in range(training_epochs):
total_batch = int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_,current_loss = sess.run([train_step, loss],feed_dict={x:batch_xs})
#지정한 epoch마다 학습결과 출력
if epoch % display_step == 0:
print('반복(Epoch): %d, 손실함수(Loss): %f' % (epoch, current_loss))
print('Trainning Finish')
# 테스트 데이터로 Reconstruction을 수행합니다.
reconstructed_result = sess.run(y_pred, feed_dict={x: mnist.test.images[:examples_to_show]})
# 원본 MNIST 데이터와 Reconstruction 결과를 비교합니다.
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(reconstructed_result[i], (28, 28)))
f.savefig('reconstructed_mnist_image.png') # reconstruction 결과를 png로 저장합니다.
f.show()
결과
반복(Epoch): 0, 손실함수(Loss): 0.181670
반복(Epoch): 5, 손실함수(Loss): 0.093784
반복(Epoch): 10, 손실함수(Loss): 0.076891
...
반복(Epoch): 26, 손실함수(Loss): 0.3990266389692753
반복(Epoch): 27, 손실함수(Loss): 0.3039966435727189
반복(Epoch): 35, 손실함수(Loss): 0.047211
반복(Epoch): 40, 손실함수(Loss): 0.045349
반복(Epoch): 45, 손실함수(Loss): 0.044621
Trainning Finish
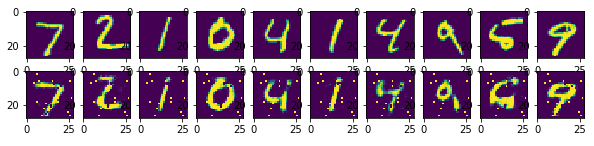
AutoEncoder가 원본 데이터를 완벽히 재현해내지 못했기 때문에 구축된 MNIST 이미지에 약간 노이즈가 포함되어 있다.
Stacked AutoEncoder를 이용한 비지도 사전학습(전이학습)
Stacked AutoEncoder를 이용한 비지도 사전학습(전이학습) 또한 앞선 Post에서 다룬 내용과 같이 MNIST Data를 분리하는 예제를 사용한다.
Stacked AutoEncoder에서 학습된 Parameter를 활용하여 Decoder를 거치는 것이 아니라 Encoder의 특징을 Softmax 로서 Classifier를 하여 좀 더 분류를 잘 할 수 있게 설계하는 것이 목표이다.
학습을 위한 Parameter 선언 이전과 달라진 점은 다음과 같다.
- Decoder Layer 선언 X
- Layer 를 위한 Learging Rate 2개 선언
1
2
3
4
5
6
7
8
learning_rate_RMSProp = 0.02
learning_rate_GradientDescent = 0.5
num_epochs = 100
batch_size = 256
display_step = 5
input_size = 784
hidden1_size = 128
hidden2_size = 64
인풋 데이터와 타겟 데이터를 받을 플레이스홀더를 정의
1
2
x = tf.placeholder(tf.float32, shape=[None, input_size])
y = tf.placeholder(tf.float32, shape = [None, 10])
Model 선언
- AutoEncoder: 784 -> 128 -> 64(압축된 특징)
- SoftmaxClassifier: 64(압축된 특징) -> 10(MNIST 숫자 개수)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#AutoEncoder 선언
def build_autoencoder(x):
#Encoding: 784 -> 128 -> 64
Wh_1 = tf.Variable(tf.random_normal(shape = [input_size, hidden1_size]))
bh_1 = tf.Variable(tf.random_normal(shape =[hidden1_size]))
H1_output = tf.nn.sigmoid(tf.matmul(x,Wh_1)+bh_1)
Wh_2 = tf.Variable(tf.random_normal(shape = [hidden1_size,hidden2_size]))
bh_2 = tf.Variable(tf.random_normal(shape =[hidden2_size]))
H2_output = tf.nn.sigmoid(tf.matmul(H1_output,Wh_2)+bh_2)
#Decoding: 64 -> 128 -> 784
Wh_3 = tf.Variable(tf.random_normal(shape = [hidden2_size, hidden1_size]))
bh_3 = tf.Variable(tf.random_normal(shape =[hidden1_size]))
H3_output = tf.nn.sigmoid(tf.matmul(H2_output,Wh_3)+bh_3)
Wo = tf.Variable(tf.random_normal(shape = [hidden1_size,input_size]))
bo = tf.Variable(tf.random_normal(shape =[input_size]))
X_reconstructed = tf.nn.sigmoid(tf.matmul(H3_output,Wo)+bo)
return X_reconstructed, H2_output
#Softmax Classifier 선언
def build_softmax_classifier(x):
W_softmax = tf.Variable(tf.zeros([hidden2_size,10]))
b_softmax = tf.Variable(tf.zeros([10]))
y_pred = tf.nn.softmax(tf.matmul(x, W_softmax)+b_softmax)
return y_pred
AutoEncoder + Softmax Classifier 를 통하여 실제 Model 생성
1
2
3
4
5
#AutoEncoder를 통한 결과 출력
y_pred, extracted_features = build_autoencoder(x)
y_true = x
#AutoEncoder의 출력을 활용한 Softmax Classifier
y_pred_softmax = build_softmax_classifier(extracted_features)
- LossFunction: MSE, CrossEntropy
- Optimizer: RMSProp, GradientDescent
1
2
3
4
5
6
7
8
# Pre-Training: MNIST 데이터 재구축을 목적으로 하는 손실함수와 옵티마이저를 정의
pretraining_loss = tf.reduce_mean(tf.pow(y_true - y_pred,2))
pretraining_train_step = tf.train.RMSPropOptimizer(learning_rate_RMSProp).minimize(pretraining_loss)
#Fine-Tuning: MNIST 데이터 분류를 목적으로 하는 손실 함수와 옵티마이저를 정의
finetuning_loss = tf.reduce_mean(-tf.reduce_sum(y*tf.log(y_pred_softmax), reduction_indices=[1]))
finetuning_train_step = tf.train.GradientDescentOptimizer(learning_rate_GradientDescent).minimize(finetuning_loss)
세션을 열어서 그래프를 실행하고 학습된 모델의 정확도를 출력
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
with tf.Session() as sess:
#변수들의 초기값을 할당
sess.run(tf.global_variables_initializer())
#전체 배치 개수를 불러오기
total_batch = int(mnist.train.num_examples/batch_size)
#Step1: MNIST 데이터 재구축을 위한 오토인코더 최적화(Pre-Trainning)
for epoch in range(num_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_,pretraining_loss_print = sess.run([pretraining_train_step,pretraining_loss],feed_dict={x:batch_xs})
if epoch % display_step ==0:
print('반복(Epoch): %d, Pre-Trainning 손실 함수(pretraining_loss): %f'%(epoch, pretraining_loss_print))
print('Step1: MNIST 데이터 재구축을 위한 오토인코더 최적화 완료(Pre-Training)')
#Step2: MNIST 데이터 분류를 위한 오토인코더 + Softmax 분류기 최적화(Fine-tunning)
for epoch in range(num_epochs+100):
#모든 배치들에 대해서 최적화를 수행
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_,finetuning_loss_print = sess.run([finetuning_train_step,finetuning_loss],feed_dict={x:batch_xs, y:batch_ys})
#지정된 epoch마다 학습결과를 출력
if epoch % display_step == 0:
print('반복(Epoch): %d, Fine-Tuning 손실 함수(Fine-Tuning_loss): %f'%(epoch, finetuning_loss_print))
print('Step2: MNIST 데이터 분류를 위한 오토인코더 + Softmax 분류기 최적화 완료')
#최종 Model에 대한 성능 평가
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_pred_softmax,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print('정확도(오토인코더 + Softmax 분류기): %f'%sess.run(accuracy,feed_dict={x:mnist.test.images, y:mnist.test.labels}))
결과
반복(Epoch): 0, Pre-Trainning 손실 함수(pretraining_loss): 0.188704
반복(Epoch): 5, Pre-Trainning 손실 함수(pretraining_loss): 0.072182
반복(Epoch): 10, Pre-Trainning 손실 함수(pretraining_loss): 0.048455
반복(Epoch): 15, Pre-Trainning 손실 함수(pretraining_loss): 0.041352
반복(Epoch): 20, Pre-Trainning 손실 함수(pretraining_loss): 0.039895
...
반복(Epoch): 180, Fine-Tuning 손실 함수(Fine-Tuning_loss): 0.008362
반복(Epoch): 185, Fine-Tuning 손실 함수(Fine-Tuning_loss): 0.011292
반복(Epoch): 190, Fine-Tuning 손실 함수(Fine-Tuning_loss): 0.012895
반복(Epoch): 195, Fine-Tuning 손실 함수(Fine-Tuning_loss): 0.017129
Step2: MNIST 데이터 분류를 위한 오토인코더 + Softmax 분류기 최적화 완료
정확도(오토인코더 + Softmax 분류기): 0.961600
참조: 원본코드
참조:excelsior-cjh 블로그
참조: 텐서플로로 배우는 딥러닝
문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment