
SSD(Code-Dataset,Utils)
SSD 구현 (Dataset, Utils)
코드 참조: ChunML GitHub
위의 Code를 참조하여 수정한 SSD의 현재 Directory의 구조는 다음과 같습니다.(위의 Code는 SSD 300,512를 둘 다 구현하였지만, 현재 Code는 논문에서 예제로 보여준 SSD300을 고정으로서 사용하였습니다.)
- Training Data
- data/train/JPEGImages
- data/train/Annotations
- Test Data
- data/test/JPEGImages
- data/test/Annotations
- preprocess_test.py: Test Dataset을 사용하기 위하여 데이터 전처리
- data/preprocessing_test/JPEGImages: 실제 Test에 사용할 Image Directory
- data/preprocessing_test/Annotations: 실제 Test에 사용할 Label Directory
- Dataset(Dataset의 Batch처리를 위한 Code)
- voc_data.py: Data Batch 처리
- Utils(전체적인 Code의 utils를 모아둔 Code)
- config.yml: 미리 Image Size, ratios, scales, fm_size(Feature Map의 크기)를 정의
- anchor.py: Default Box를 생성
- box_utils.py: IOU측정등 box를 위한 utils
- image_utils.py: 논문에서 제시한 Data Augmentation, ImageVisualization을 정의
- Model(SSD의 Model을 위한 Code)
- layers.py: SSD의 Layer를 선언
- network.py: SSD의 Network를 선언
- losses.py: SSD의 Loss를 선언
- Train & Test(Model의 Train 및 Test를 위한 Code)
- train.py: Model의 Train을 위한 Code
- test.py: Model의 Output을 위한 Code
사전사항 1(requirement)
실제 SSD를 구현하기 위하여 필요한 사전설치사항은 requirement.txt에 저장해두었다.
!pip install -r requirements.txt
사전사항 2(Dataset-Trainning, Validation)
사용한 Data는 YOLO와 SSD에서 공통적으로 사용한 PASCAL 2012 Data를 사용하였다.
Directory의 Size는 2GB로서 다음링크에서 다운받을 수 있다.
참조: PASCAL 2012 DataSet
해당 링크에서 Data를 다운로드 받으면 다음과 같이 되어있다.
- VOCdevkit/VOC2012
- Annotations
- ImageSets
- JPEGImages
- SegmentationClass
- SegmentationObject
위의 5개의 Directory에서 2가지만 사용한다.
- JPEGImages: .jpg Image가 들어있다.
- Annotation: .xml형식으로 해당 Image에 대한 Box의 위치가 적혀있다. (xmin,ymin,xmax,ymax)로서 구성되어있다.

사전사항 3(Dataset-Test)
사용한 Data는 YOLO와 SSD에서 공통적으로 사용한 PASCAL 2012 Test Data를 사용(PASCAL 2012 Test DataSet)하였다.
Directory의 Size는 500MB이고 위에서 다운받은 링크에서 회원가입을 해야지 다운받을 수 있다.
해당 링크에서 회원가입 후 Data를 다운로드 받으면 다음과 같이 되어있다.
- VOCdevkit/VOC2012
- Annotations
- ImageSets
- JPEGImages
위의 3개의 Directory에서 2가지만 사용한다.
- JPEGImages: .jpg Image가 들어있다.
- Annotation: .xml형식으로 해당 Image에 대한 Box의 위치가 적혀있다. (xmin,ymin,xmax,ymax)로서 구성되어있다.
현재 TestDataset을 다운받아 사용하면 문제점이 Image File인 .jpg와 Label File인 .xml의 수가 일치하지 않는다는 것 이다. 따라서 아래의 Code를 통하여 서로 Mapping되는 File만을 preprocessing_test Directory에 위치하게 한다.
preprocess_tesy.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import os
import shutil
os.chdir('./data/test')
image_dir = './JPEGImages/'
ano_dir ='./Annotations/'
preprocessing_dir = '../preprocessing_test'
preprocessing_image = preprocessing_dir+'/JPEGImages/'
preprocessing_ano = preprocessing_dir+'/Annotations/'
def make_dir(dir_path):
if not os.path.isdir(dir_path):
os.mkdir(dir_path)
else:
pass
make_dir(preprocessing_dir)
make_dir(preprocessing_image)
make_dir(preprocessing_ano)
image_file = list(map(lambda x: x[:-4], os.listdir(image_dir)))
ano_file = list(map(lambda x: x[:-4], os.listdir(ano_dir)))
for image in image_file:
for ano in ano_file:
if image == ano:
shutil.move(image_dir+image+'.jpg',preprocessing_image)
shutil.move(ano_dir+ano+'.xml',preprocessing_ano)
Utils
config.yaml
기본적인 SSD300에 대한 Parameter를 미리 정의한다.
SSD300:
ratios: [[2], [2, 3], [2, 3], [2, 3], [2], [2]]
scales: [0.1, 0.2, 0.375, 0.55, 0.725, 0.9, 1.075]
fm_sizes: [38, 19, 10, 5, 3, 1]
image_size: 300
- image_size: 해당 논문과 동일하게 300 x 300 pixel Size로서 선언하였다.
- ratiosn: Aspect Rations는 \(1,2,3,\frac{1}{2},\frac{1}{3}\)으로서 선언되었다. 1인경우에 특별한 \(s_k^{'}=\sqrt{s_k s_{k+1}}\)이 적용되어야 하므로 따로 anchor.py에서 추가적인 작업을 한다.
- scales: \(m=6, s_{min}=0.1, s_{max}=0.9\), \(s_k = s_{min}+\frac{s_{max}-s_{min}}{m}(k-1) \rightarrow 0.1+\frac{0.8}{5}(k-1)\)로서 값을 대입하여 계산하였다.
- fm_size: 해당 논문의 Model구조에 맞는 Feature Map의 Size를 정의하였다.
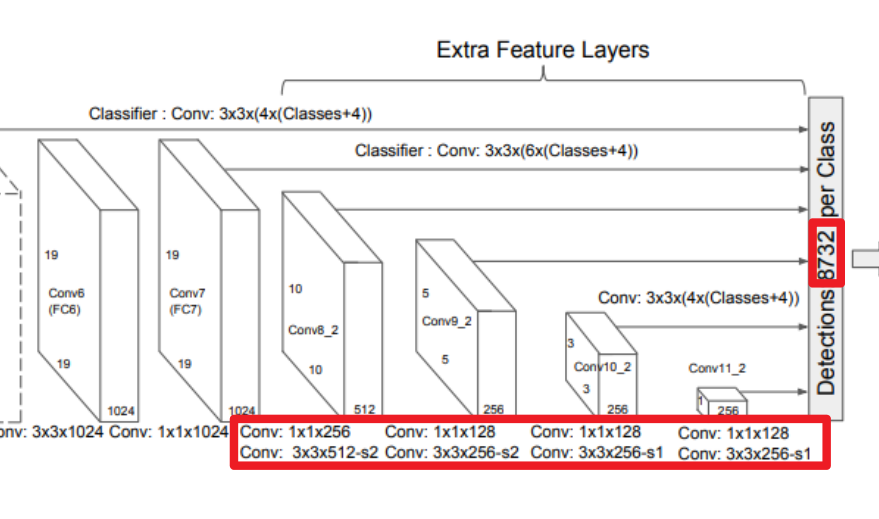
조심하여야 하는 부분이다. 제일 이해가 되지 않고 많이 해매었던 부분이기도 하다. 위의 Network의 결과로서 8732 Dimension의 Tensor가 나오게 된다. 각각의 Featuremap의 결과를 합치면 다음과 같이 나오게 되어야 한다. 하지만 Aspect Rations는 \(1,2,3,\frac{1}{2},\frac{1}{3}\)를 전부 다 적용하면 11640 Dimension의 결과가 나오게 된다.(\(11640=(38*38*6)+(19*19*6)+(10*10*6)+(5*5*6)+(3*3*6)+(1*1*6)\)) 논문을 자세히 보면 각각의 Featurmap의 결과에 \(s_k\)로서 표시한 것을 볼 수 있다. 이것이 의미하는 것은 Scale의 개수를 의미하는 것으로 다음과 같이 정리될 수 있다.
- \(s_1 = 1,2,\frac{1}{2}\)
- \(s_2 = 1,2,\frac{1}{2},3,\frac{1}{3}\)
따라서 위의 ratios처럼 정의하게 되면 최종적으로 8738(=\((38*38*4)+(19*19*6)+(10*10*6)+(5*5*6)+(3*3*4)+(1*1*4)\))를 얻을 수 있다.
anchor.py
Default Box를 정의하는 곳 이다.
각각의 Default Box는 Feature Map에 따라서 Ratios와 Scale을 변화시키면서 (cx,cy,w,h)를 생성하게 된다.
$$a_r \in {1,2,3,\frac{1}{2},\frac{1}{3}} (w_k^a = s_k\sqrt{a_r}) (h_k^a = s_k/\sqrt{a_r})$$
$$s_k^{'}=\sqrt{s_k s_{k+1}}\text{, }a_r=1 \text{ 인 경우}$$
$$(cx,cy) = (\frac{i+0.5}{|f_k|},\frac{j+0.5}{|f_k|}), f_k\text{는 k번째 Feature Map의 크기}$$
위의 식을 그대로 적용한 것을 알 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
import itertools
import math
import tensorflow as tf
def generate_default_boxes(config):
""" Generate default boxes for all feature maps
Args:
config: information of feature maps
scales: boxes' size relative to image's size
fm_sizes: sizes of feature maps
ratios: box ratios used in each feature maps
Returns:
default_boxes: tensor of shape (num_default, 4) with format (cx, cy, w, h)
"""
# Config를 Argument로 받아 미리 지정되어있는 config.yaml File의 Parameter값을 가져오게 된다.
default_boxes = []
scales = config['scales']
fm_sizes = config['fm_sizes']
ratios = config['ratios']
for m, fm_size in enumerate(fm_sizes):
for i, j in itertools.product(range(fm_size), repeat=2):
# cx, cy 정의
cx = (j + 0.5) / fm_size
cy = (i + 0.5) / fm_size
# Aspect ratio가 1인경우
default_boxes.append([
cx,
cy,
scales[m],
scales[m]
])
default_boxes.append([
cx,
cy,
math.sqrt(scales[m] * scales[m + 1]),
math.sqrt(scales[m] * scales[m + 1])
])
# Aspect ratio가 1이 아닌경우 (2,3)
for ratio in ratios:
r = math.sqrt(ratio)
default_boxes.append([
cx,
cy,
scales[m] * r,
scales[m] / r
])
default_boxes.append([
cx,
cy,
scales[m] / r,
scales[m] * r
])
# Defult Boxes는 N*(cx,cy,w,h)로서 정의되게 된다.
default_boxes = tf.constant(default_boxes)
# 0~1 사이의 값으로서 정규화
default_boxes = tf.clip_by_value(default_boxes, 0.0, 1.0)
return default_boxes
box_utils.py
실제 Box에 관한 Utils를 모아두는 곳 이다. 다양한 Function이 존재하게 된다.
1) transform_corner_to_center(boxes)
원래 Label Dataset Format을 논문에서의 Format으로 바꾼다. (xmin,ymin,xmax,ymax) -> (cx,cy,w,h)
2) transform_center_to_corner(boxes)
논문에서의 Format을 원래 Label Dataset Format으로 바꾼다. (cx,cy,w,h) -> (xmin,ymin,xmax,ymax)
3) compute_area(top_left,bot_right)
iou를 계산하기 위해서 (top_left(x_min,y_min),bot_right(x_max,y_max))를 통하여 Bounding Box의 width, height를 통하여 Area를 구하는 과정이다.
4) compute_iou(boxes_a,boxes_b)
실제 Ground Truth Box와 Predicted Box를 jaccard overlap을 통하여 Matching strategy를 계산하는 과정이다.
$$J(A,B) = \frac{|A \cap B|}{|A \cup B|} = \frac{|A \cap B|}{|A|+|B|-|A \cap B|}$$
5) encode(default_boxes, boxes)
Localization Loss를 위하여 식을 좌표를 변경하는 단계이다.
$$\hat{g}_j^{cx}=(g_j^{cx}-d_i^{cx})/d_i^w, \hat{g}_j^{cy}=(g_j^{cy}-d_i^{cy})/d_i^h$$
$$\hat{g}_j^{w} = log(\frac{g_j^w}{d_i^w}), \hat{g}_j^{h} = log(\frac{g_j^h}{d_i^h})$$
6) decode(default_boxes, locs)
Encode의 반대 과정
7) compute_target(default_boxes, gt_boxes,gt_labels,iou_threshold=0.5)
2가지의 Confidence Loss와 Localization Loss를 위한 과정이다.
현재 Function의 절차는 다음과 같다.
- Matching strategy를 계산
- 가장 iou가 높은 best_default_iou, best_gt_iou를 계산한다.
- 가장 iou가 높은 Ground Truth Box의 Class를 측정한다.
- Ground Truth Box의 Classify의 Label중 해당 Box에 대한 Class를 구한다. Threshold(논문과 같은 0.5의 값)를 적용하여 해당 클래스를 구한다.(gt_confs=\(x_{ij}^p log(\hat{c}_i^p)\))
- Default Box에서 가장 IOU가 높은 Ground Truth Box의 좌표를 Encode를 통하여 논문에 맞게 식을 변형한다.(gt_locs= GroundTruthBox(\((\hat{g}_j^{cx},\hat{g}_j^{cy},\hat{g}_j^{w},\hat{g}_j^{h})\)))
$$ x_{ij}^p= \begin{cases} 1, & \mbox{if } IOU > 0.5 \mbox{ between default box i and ground true box j on class p} \\ 0, & \mbox{otherwise} \end{cases} $$
8) compute_nms(boxes, scores, nms_threshold, limit=200)
일정영역 이상의 겹친 Boxes를 제거하는 부분이다. 가장 많이 겹친 부분만 살려둔다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
import tensorflow as tf
# iou를 계산하기 위해서 (top_left(x_min,y_min),bot_right(x_max,y_max))를 통하여
# Bounding Box의 width, height를 통하여 Area를 구하는 과정이다.
def compute_area(top_left, bot_right):
""" Compute area given top_left and bottom_right coordinates
Args:
top_left: tensor (num_boxes, 2)
bot_right: tensor (num_boxes, 2)
Returns:
area: tensor (num_boxes,)
"""
# top_left: N x 2
# bot_right: N x 2
hw = tf.clip_by_value(bot_right - top_left, 0.0, 300.0)
area = hw[..., 0] * hw[..., 1]
return area
# 실제 Ground Truth Box와 Predicted Box를 jaccard overlap을 통하여 Matching strategy를 계산하는 과정이다.
def compute_iou(boxes_a, boxes_b):
""" Compute overlap between boxes_a and boxes_b
Args:
boxes_a: tensor (num_boxes_a, 4)
boxes_b: tensor (num_boxes_b, 4)
Returns:
overlap: tensor (num_boxes_a, num_boxes_b)
"""
# boxes_a => num_boxes_a, 1, 4
boxes_a = tf.expand_dims(boxes_a, 1)
# boxes_b => 1, num_boxes_b, 4
boxes_b = tf.expand_dims(boxes_b, 0)
top_left = tf.math.maximum(boxes_a[..., :2], boxes_b[..., :2])
bot_right = tf.math.minimum(boxes_a[..., 2:], boxes_b[..., 2:])
overlap_area = compute_area(top_left, bot_right)
area_a = compute_area(boxes_a[..., :2], boxes_a[..., 2:])
area_b = compute_area(boxes_b[..., :2], boxes_b[..., 2:])
overlap = overlap_area / (area_a + area_b - overlap_area)
return overlap
# 2가지의 Confidence Loss와 Localization Loss를 위한 과정이다.
def compute_target(default_boxes, gt_boxes, gt_labels, iou_threshold=0.5):
""" Compute regression and classification targets
Args:
default_boxes: tensor (num_default, 4)
of format (cx, cy, w, h)
gt_boxes: tensor (num_gt, 4)
of format (xmin, ymin, xmax, ymax)
gt_labels: tensor (num_gt,)
Returns:
gt_confs: classification targets, tensor (num_default,)
gt_locs: regression targets, tensor (num_default, 4)
"""
# Convert default boxes to format (xmin, ymin, xmax, ymax)
# in order to compute overlap with gt boxes
transformed_default_boxes = transform_center_to_corner(default_boxes)
# Matching strategy를 계산
iou = compute_iou(transformed_default_boxes, gt_boxes)
# 가장 iou가 높은 best_default_iou, best_gt_iou를 계산한다.
best_gt_iou = tf.math.reduce_max(iou, 1)
best_gt_idx = tf.math.argmax(iou, 1)
best_default_iou = tf.math.reduce_max(iou, 0)
best_default_idx = tf.math.argmax(iou, 0)
best_gt_idx = tf.tensor_scatter_nd_update(
best_gt_idx,
tf.expand_dims(best_default_idx, 1),
tf.range(best_default_idx.shape[0], dtype=tf.int64))
# Normal way: use a for loop
# for gt_idx, default_idx in enumerate(best_default_idx):
# best_gt_idx = tf.tensor_scatter_nd_update(
# best_gt_idx,
# tf.expand_dims([default_idx], 1),
# [gt_idx])
best_gt_iou = tf.tensor_scatter_nd_update(
best_gt_iou,
tf.expand_dims(best_default_idx, 1),
tf.ones_like(best_default_idx, dtype=tf.float32))
# Ground Truth Box의 Classify의 Label중 해당 Box에 대한 Class를 구한다.
# Threshold(논문과 같은 0.5의 값)를 적용하여 해당 클래스를 구한다.
gt_confs = tf.gather(gt_labels, best_gt_idx)
gt_confs = tf.where(
tf.less(best_gt_iou, iou_threshold),
tf.zeros_like(gt_confs),
gt_confs)
# Default Box에서 가장 IOU가 높은 Ground Truth Box의
# 좌표를 Encode를 통하여 논문에 맞게 식을 변형한다.
gt_boxes = tf.gather(gt_boxes, best_gt_idx)
gt_locs = encode(default_boxes, gt_boxes)
return gt_confs, gt_locs
# Localization Loss를 위하여 식을 좌표를 변경하는 단계이다.
def encode(default_boxes, boxes):
""" Compute regression values
Args:
default_boxes: tensor (num_default, 4)
of format (cx, cy, w, h)
boxes: tensor (num_default, 4)
of format (xmin, ymin, xmax, ymax)
variance: variance for center point and size
Returns:
locs: regression values, tensor (num_default, 4)
"""
# Convert boxes to (cx, cy, w, h) format
transformed_boxes = transform_corner_to_center(boxes)
locs = tf.concat([
(transformed_boxes[..., :2] - default_boxes[:, :2]
) / (default_boxes[:, 2:]),
tf.math.log(transformed_boxes[..., 2:] / default_boxes[:, 2:])],
axis=-1)
return locs
# Encode의 반대 과정
def decode(default_boxes, locs):
""" Decode regression values back to coordinates
Args:
default_boxes: tensor (num_default, 4)
of format (cx, cy, w, h)
locs: tensor (batch_size, num_default, 4)
of format (cx, cy, w, h)
variance: variance for center point and size
Returns:
boxes: tensor (num_default, 4)
of format (xmin, ymin, xmax, ymax)
"""
locs = tf.concat([
locs[..., :2] *
default_boxes[:, 2:] + default_boxes[:, :2],
tf.math.exp(locs[..., 2:]) * default_boxes[:, 2:]], axis=-1)
boxes = transform_center_to_corner(locs)
return boxes
# 원래 Label Dataset Format을 논문에서의 Format으로 바꾼다. (xmin,ymin,xmax,ymax) -> (cx,cy,w,h)
def transform_corner_to_center(boxes):
""" Transform boxes of format (xmin, ymin, xmax, ymax)
to format (cx, cy, w, h)
Args:
boxes: tensor (num_boxes, 4)
of format (xmin, ymin, xmax, ymax)
Returns:
boxes: tensor (num_boxes, 4)
of format (cx, cy, w, h)
"""
center_box = tf.concat([
(boxes[..., :2] + boxes[..., 2:]) / 2,
boxes[..., 2:] - boxes[..., :2]], axis=-1)
return center_box
# 논문에서의 Format을 원래 Label Dataset Format으로 바꾼다. (cx,cy,w,h) -> (xmin,ymin,xmax,ymax)
def transform_center_to_corner(boxes):
""" Transform boxes of format (cx, cy, w, h)
to format (xmin, ymin, xmax, ymax)
Args:
boxes: tensor (num_boxes, 4)
of format (cx, cy, w, h)
Returns:
boxes: tensor (num_boxes, 4)
of format (xmin, ymin, xmax, ymax)
"""
corner_box = tf.concat([
boxes[..., :2] - boxes[..., 2:] / 2,
boxes[..., :2] + boxes[..., 2:] / 2], axis=-1)
return corner_box
# 일정영역 이상의 겹친 Boxes를 제거하는 부분이다. 가장 많이 겹친 부분만 살려둔다.
def compute_nms(boxes, scores, nms_threshold, limit=200):
""" Perform Non Maximum Suppression algorithm
to eliminate boxes with high overlap
Args:
boxes: tensor (num_boxes, 4)
of format (xmin, ymin, xmax, ymax)
scores: tensor (num_boxes,)
nms_threshold: NMS threshold
limit: maximum number of boxes to keep
Returns:
idx: indices of kept boxes
"""
if boxes.shape[0] == 0:
return tf.constant([], dtype=tf.int32)
selected = [0]
idx = tf.argsort(scores, direction='DESCENDING')
idx = idx[:limit]
boxes = tf.gather(boxes, idx)
iou = compute_iou(boxes, boxes)
while True:
row = iou[selected[-1]]
next_indices = row <= nms_threshold
# iou[:, ~next_indices] = 1.0
iou = tf.where(
tf.expand_dims(tf.math.logical_not(next_indices), 0),
tf.ones_like(iou, dtype=tf.float32),
iou)
if not tf.math.reduce_any(next_indices):
break
selected.append(tf.argsort(
tf.dtypes.cast(next_indices, tf.int32), direction='DESCENDING')[0].numpy())
return tf.gather(idx, selected)
image_utils.py
Image에 관련된 Utils모아둔 Code이다.
1) class ImageVisualizer(object)
Model이 Predicted한 Object Class와 Box Localization, Image를 입력받아 해당되는 Image에 Box를 표시한 뒤, Class를 표시하고 저장한다.
2) horizontal_flip(img, boxes, labels)
Data Augmentation방법이다. 논문에서는 다음과 같이 3가지 방법을 사용하였다.
- Use the original
- Using Patch(Sample a patch with IOU of 0.1, 0.3, 0.5, 0.7 or 0.9)
- Resize and flipped with probablity of 0.5
논문의 방식대로 3가지로 진행하려고 하였으나, IOU가 0.1, 0.3, 0.5 에 맞게 계속해서 무한루프를 돌게되는 경우 많은 시간을 소비하여 제외하고 Original, Flipped의 2가지 방법을 사용하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
import os
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import random
import numpy as np
import tensorflow as tf
from box_utils import compute_iou
# Model이 Predicted한 Object Class와 Box Localization,
# Image를 입력받아 해당되는 Image에 Box를 표시한 뒤, Class를 표시하고 저장한다.
class ImageVisualizer(object):
""" Class for visualizing image
Attributes:
idx_to_name: list to convert integer to string label
class_colors: colors for drawing boxes and labels
save_dir: directory to store images
"""
def __init__(self, idx_to_name, class_colors=None, save_dir=None):
self.idx_to_name = idx_to_name
if class_colors is None or len(class_colors) != len(self.idx_to_name):
self.class_colors = [[0, 255, 0]] * len(self.idx_to_name)
else:
self.class_colors = class_colors
if save_dir is None:
self.save_dir = './'
else:
self.save_dir = save_dir
os.makedirs(self.save_dir, exist_ok=True)
def save_image(self, img, boxes, labels, name):
""" Method to draw boxes and labels
then save to dir
Args:
img: numpy array (width, height, 3)
boxes: numpy array (num_boxes, 4)
labels: numpy array (num_boxes)
name: name of image to be saved
"""
plt.figure()
fig, ax = plt.subplots(1)
ax.imshow(img)
save_path = os.path.join(self.save_dir, name)
for i, box in enumerate(boxes):
idx = labels[i] - 1
cls_name = self.idx_to_name[idx]
top_left = (box[0], box[1])
bot_right = (box[2], box[3])
ax.add_patch(patches.Rectangle(
(box[0], box[1]),
box[2] - box[0], box[3] - box[1],
linewidth=2, edgecolor=(0., 1., 0.),
facecolor="none"))
plt.text(
box[0],
box[1],
s=cls_name,
color="white",
verticalalignment="top",
bbox={"color": (0., 1., 0.), "pad": 0},
)
plt.axis("off")
plt.savefig(save_path, bbox_inches="tight", pad_inches=0.0)
plt.close('all')
# Image를 Flipped한 뒤 Box의 위치를 조정한다.
def horizontal_flip(img, boxes, labels):
""" Function to horizontally flip the image
The gt boxes will be need to be modified accordingly
Args:
img: the original PIL Image
boxes: gt boxes tensor (num_boxes, 4)
labels: gt labels tensor (num_boxes,)
Returns:
img: the horizontally flipped PIL Image
boxes: horizontally flipped gt boxes tensor (num_boxes, 4)
labels: gt labels tensor (num_boxes,)
"""
img = img.transpose(Image.FLIP_LEFT_RIGHT)
boxes = tf.stack([
1 - boxes[:, 2],
boxes[:, 1],
1 - boxes[:, 0],
boxes[:, 3]], axis=1)
return img, boxes, labels
Dataset
voc_data.py
실질적인 Dataset을 Training Data와 Validation Data로서 나눈 뒤, Batch 처리까지하여 Model에 넣을 수 있게 하는 Preprocessing 단계이다.
1) init():
Data초기에 필요한 Argument들을 정의하는 부분이다.
- idx_to_name: 미리 정해져있는 20개의 Label을 정의한 것
- name_to_idx: {‘aeroplane’: 0, ‘bicycle’: 1,…} 형식으로 Label의 이름과 Index를 Dict Type으로 선언
- image_dir: Image 경로
- anno_dir: Annotations(Bounding Box의 Label 및 (xmin,ymin,xmax,ymax)) 경로
- ids: Image와 해당되는 Annotation이 맞는지 확인하기 위한 것.
- image_dir_example: 2008_000200.jpg
- anno_dir_example: 2008_000200.xml
- default_boxes: 입력 받는 Default Boxes
- new_size: Model Input으로 들어가는 Image의 Size
- train_ids: Trainning Dataset, 전체 Dataset의 75%
- val_ids: Validation Dataset, 전체 Dataset의 25%
- augmentation: 위의 image_utils.py를 활용하여 Dataset을 원래대로 사용할지 Flip한 Dataset을 사용할지 결정하기 위해서
2) len(): 전체 데이터의 개수 파악
3) get_image(): 해당되는 Index의 Image를 반환
4) get_annotation(): 해당되는 Index의 Annotation.xml을 통하여 Label,(xmin, ymin, xmax, ymax)을 반환-> 0~1사이의 값으로서 정규화
5) generate()
- Input Image의 Size를 받는다.
- get_annotation()을 통하여 Label과 Bounding Box의 Location을 입력받는다.
- Random하게 Original Image를 사용할지 Flip을 실행할 Image를 사용할지 결정한다.
- Image의 Size를 Model Input에 맞게 (300,300)으로 바꾼뒤 0 ~ 1 사이의 값으로서 정규화를 한다.
- Utils -> box_utils -> compute_target를 통하여 실제 Label을 Model에 맞는 Label로서 변경한다.
- Filename, Image, Ground Truth Label, Ground Truth Location을 반환한다. 6) create_batch_generator(): Batch_Size를 입력받아 Dataset을 생성한다. 만약 아래 Code가 이해되지 않으면 링크 참조
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
import tensorflow as tf
import os
import numpy as np
import xml.etree.ElementTree as ET
from PIL import Image
import random
from box_utils import compute_target
from image_utils import horizontal_flip
from functools import partial
# 실질적인 Dataset을 Training Data와 Validation Data로서 나눈 뒤,
# Batch 처리까지하여 Model에 넣을 수 있게 하는 Preprocessing 단계이다.
# Data초기에 필요한 Argument들을 정의하는 부분이다.
class VOCDataset():
def __init__(self, data_dir, default_boxes,num_examples=-1):
super(VOCDataset, self).__init__()
# 미리 정해져있는 20개의 Label을 정의한 것
self.idx_to_name = [
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor']
# {'aeroplane': 0, 'bicycle': 1,...} 형식으로 Label의 이름과 Index를 Dict Type으로 선언
self.name_to_idx = dict([(v, k)
for k, v in enumerate(self.idx_to_name)])
# Image 경로
self.image_dir = data_dir+'/JPEGImages'
# Annotations(Bounding Box의 Label 및 (xmin,ymin,xmax,ymax)) 경로
self.anno_dir = data_dir+'/Annotations'
# Image와 해당되는 Annotation이 맞는지 확인하기 위한 것.
self.ids = list(map(lambda x: x[:-4], os.listdir(self.image_dir)))
# 입력 받는 Default Boxes
self.default_boxes = default_boxes
# Model Input으로 들어가는 Image의 Size
self.new_size = 300
if num_examples != -1:
self.ids = self.ids[:num_examples]
# Trainning Dataset, 전체 Dataset의 75%
self.train_ids = self.ids[:int(len(self.ids) * 0.75)]
# Validation Dataset, 전체 Dataset의 25%
self.val_ids = self.ids[int(len(self.ids) * 0.75):]
# 위의 image_utils.py를 활용하여 Dataset을 원래대로 사용할지 Flip한 Dataset을 사용할지 결정하기 위해서
self.augmentation = ['original','flip']
# 전체 데이터의 개수 파악
def __len__(self):
return len(self.ids)
# 해당되는 Index의 Image를 반환
def _get_image(self, index):
""" Method to read image from file
then resize to (300, 300)
then subtract by ImageNet's mean
then convert to Tensor
Args:
index: the index to get filename from self.ids
Returns:
img: tensor of shape (3, 300, 300)
"""
filename = self.ids[index]
img_path = os.path.join(self.image_dir, filename + '.jpg')
img = Image.open(img_path)
return img
# 해당되는 Index의 Annotation.xml을 통하여
# Label,(xmin, ymin, xmax, ymax)을 반환-> 0~1사이의 값으로서 정규화
def _get_annotation(self, index, orig_shape):
""" Method to read annotation from file
Boxes are normalized to image size
Integer labels are increased by 1
Args:
index: the index to get filename from self.ids
orig_shape: image's original shape
Returns:
boxes: numpy array of shape (num_gt, 4)
labels: numpy array of shape (num_gt,)
"""
h, w = orig_shape
filename = self.ids[index]
anno_path = os.path.join(self.anno_dir, filename + '.xml')
objects = ET.parse(anno_path).findall('object')
boxes = []
labels = []
for obj in objects:
name = obj.find('name').text.lower().strip()
bndbox = obj.find('bndbox')
xmin = (float(bndbox.find('xmin').text) - 1) / w
ymin = (float(bndbox.find('ymin').text) - 1) / h
xmax = (float(bndbox.find('xmax').text) - 1) / w
ymax = (float(bndbox.find('ymax').text) - 1) / h
boxes.append([xmin, ymin, xmax, ymax])
labels.append(self.name_to_idx[name] + 1)
return np.array(boxes, dtype=np.float32), np.array(labels, dtype=np.int64)
# 실질적인 Dataset 생성을 위하여 필요
def generate(self, subset=None):
""" The __getitem__ method
so that the object can be iterable
Args:
index: the index to get filename from self.ids
Returns:
img: tensor of shape (300, 300, 3)
boxes: tensor of shape (num_gt, 4)
labels: tensor of shape (num_gt,)
"""
# 만약 Train인 경우 File적용 Test라면 Filp 적용 X
if subset == 'train':
indices = self.train_ids
# 3. Random하게 Original Image를 사용할지 Flip을 실행할 Image를 사용할지 결정한다.
augmentation_method = np.random.choice(self.augmentation)
if augmentation_method == 'flip':
img, boxes, labels = horizontal_flip(img, boxes, labels)
elif subset == 'val':
indices = self.val_ids
else:
indices = self.ids
for index in range(len(indices)):
# img, orig_shape = self._get_image(index)
filename = indices[index]
img = self._get_image(index)
# 1. Input Image의 Size를 받는다.
w, h = img.size
# 2. get_annotation()을 통하여 Label과 Bounding Box의 Location을 입력받는다.
boxes, labels = self._get_annotation(index, (h, w))
boxes = tf.constant(boxes, dtype=tf.float32)
labels = tf.constant(labels, dtype=tf.int64)
# 4. Image의 Size를 Model Input에 맞게 (300,300)으로 바꾼뒤 0 ~ 1 사이의 값으로서 정규화를 한다.
img = np.array(img.resize(
(self.new_size, self.new_size)), dtype=np.float32)
img = (img / 127.0) - 1.0
img = tf.constant(img, dtype=tf.float32)
# 5. Utils -> box_utils -> compute_target를 통하여 실제 Label을 Model에 맞는 Label로서 변경한다.
gt_confs, gt_locs = compute_target(
self.default_boxes, boxes, labels)
# 6. Filename, Image, Ground Truth Label, Ground Truth Location을 반환한다
# Generator로서 특정 Index후 다음 Index로 반환하기 위하여 Return 값을 yield로서 선언
yield filename, img, gt_confs, gt_locs
# create_batch_generator(): Batch_Size를 입력받아 Dataset을 생성한다.
def create_batch_generator(data_dir,default_boxes,batch_size, num_batches,
mode):
num_examples = batch_size * num_batches if num_batches > 0 else -1
voc = VOCDataset(data_dir,default_boxes,num_examples)
info = {
'idx_to_name': voc.idx_to_name,
'name_to_idx': voc.name_to_idx,
'length': len(voc),
'image_dir': voc.image_dir,
'anno_dir': voc.anno_dir
}
if mode == 'train':
train_gen = partial(voc.generate, subset='train')
train_dataset = tf.data.Dataset.from_generator(
train_gen, (tf.string, tf.float32, tf.int64, tf.float32))
val_gen = partial(voc.generate, subset='val')
val_dataset = tf.data.Dataset.from_generator(
val_gen, (tf.string, tf.float32, tf.int64, tf.float32))
train_dataset = train_dataset.shuffle(40).batch(batch_size)
val_dataset = val_dataset.batch(batch_size)
return train_dataset.take(num_batches), val_dataset.take(-1), info
else:
dataset = tf.data.Dataset.from_generator(
voc.generate, (tf.string, tf.float32, tf.int64, tf.float32))
dataset = dataset.batch(batch_size)
return dataset.take(num_batches), info
참조: 원본코드
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment