
Estimators
Estimators
Tensorflow 2.0에 맞게 다시 Tensorflow를 살펴볼 필요가 있다고 느껴져서 Tensorflow 정식 홈페이지에 나와있는 예제부터 전반적인 Tensorflow 사용법을 먼저 익히는 Post가 된다.
필요한 Library Import
1
2
3
4
5
6
7
8
9
10
11
from __future__ import absolute_import, division, print_function, unicode_literals
import os
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import clear_output
from six.moves import urllib
import tensorflow.compat.v2.feature_column as fc
import tensorflow as tf
import tensorflow_datasets as tfds
What is Estimators?
추상화(abstraction) 이란 코드를 특정한 목적으로 일반화하여 기존 코드 ‘위에 올라가는’ 코드의 계층을 의미한다. 관련있는 High-Level 기능을 묶는 방식의 재구성을 통해 코드를 감싸서 추상화한다. 따라서 쉽게 코딩할 수 있고, 가독성이 좋으며, 코드가 간소화된다.
이러한 추상화 라이브러리를 살펴보면 다음과 같은 종류들이 존재한다.
- tf.estimator
- TFLearn
- TF-Slim
- Keras
tf.estimator또한 Keras와 같이 관련있는 High-Level 기능을 묶는 방식의 재구성을 통해 Code를 추상화하는 방법이다.
익숙한 Keras를 예를 들어 설명하면 tf.keras.Model또한 model-level abstraction이다.
출처: excelsior-cjh 블로그
이러한 High-Level Tensorflow API인 tf.estimator는 다음과 같은 기능들을 포함하고 있습니다.
- training
- evaluation
- prediction
- export for serving
이러한 Estimator는 미리 만들어진 것을 사용하거나 사용자가 직접 정의하여 Customizing한 것을 사용할 수 있다.
Estimators Capabilities
Estimators에 대한 장점을 다음과 같이 설명하고 있다.
- Model을 변경하지 않고 호스트 또는 분산 다중 서버 환경에서 Estimator 기반 모델을 실행할 수 있다. 또한 모델을 코딩하지 않고도 CPU, GPU 또는 TPU에서 Estimator 기반 모델을 실행 할 수 있다.
- Estimator는 다음과 같은 safe distributed training loop를 제공한다.
- load data
- handel exceptions
- create checkpoint files and recover from failures
- save summaries for TensorBoard
Premade Estimators
이미 정의 되어있는 Estimators를 활용하여 Iris Classification Problem을 해결한다.
또한 Estimators를 Programming하는 방법으로는 다음과 같이 설명하고 있다.
- Create one or more input function
- Define the model’s feature columns
- Instantiate an Estimator, specifying the feature columns and various hyperparameters.
- Call one or more methods on the Estimator object, passing the appropriate input function as the source of the data.
위와 같이 정의된 Estimaros에 대하여 학습 데이터를 사용해 모델을 학습(Training): model.(train) -> 학습된 모델을 평가(evaluate): model.evaluate() -> 테스트 데이터를 이용해 결과를 예측(predict): model.predict()는 기존의 Model들과 동일하다.
참고사항으로, Tensorflow 2.0에서도 Keras API에서도 같은 수행을 할 수 있는 것이 많다고 한다. 새로 시작하는 사람들은 Keras로 시작하는 것을 추천하고 있다.
Iris Dataset 준비
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
CSV_COLUMN_NAMES = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']
SPECIES = ['Setosa', 'Versicolor', 'Virginica']
train_path = tf.keras.utils.get_file(
"iris_training.csv", "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv")
test_path = tf.keras.utils.get_file(
"iris_test.csv", "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv")
train = pd.read_csv(train_path, names=CSV_COLUMN_NAMES, header=0)
test = pd.read_csv(test_path, names=CSV_COLUMN_NAMES, header=0)
print(train.head())
train_y = train.pop('Species')
test_y = test.pop('Species')
SepalLength SepalWidth PetalLength PetalWidth Species
0 6.4 2.8 5.6 2.2 2
1 5.0 2.3 3.3 1.0 1
2 4.9 2.5 4.5 1.7 2
3 4.9 3.1 1.5 0.1 0
4 5.7 3.8 1.7 0.3 0
Create input functions
- input_evaluation_set(): 초기 자료값 선언
- input_fn(): features(Data), labels를 받아서 Tensor로 바꾸는 작업 각각의 Feature들은 Dict Type으로서 형성되고 labels들은 Tensor로서 선언된다. 아래 Code의 주석을 해제하고 실행하게 되면 다음과 같은 결과를 얻게 된다.
{'SepalLength': <tf.Tensor: id=1938, shape=(3,), dtype=float64, numpy=array([6.4, 5. , 4.9])>, 'SepalWidth': <tf.Tensor: id=1939, shape=(3,), dtype=float64, numpy=array([2.8, 2.3, 2.5])>, 'PetalLength': <tf.Tensor: id=1936, shape=(3,), dtype=float64, numpy=array([5.6, 3.3, 4.5])>, 'PetalWidth': <tf.Tensor: id=1937, shape=(3,), dtype=float64, numpy=array([2.2, 1. , 1.7])>}
tf.Tensor([2 1 2], shape=(3,), dtype=int32)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def input_evaluation_set():
features = {'SepalLength': np.array([6.4, 5.0]),
'SepalWidth': np.array([2.8, 2.3]),
'PetalLength': np.array([5.6, 3.3]),
'PetalWidth': np.array([2.2, 1.0])}
labels = np.array([2, 1])
return features, labels
def input_fn(features, labels, training=True, batch_size=256):
"""An input function for training or evaluating"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle and repeat if you are in training mode.
if training:
dataset = dataset.shuffle(1000).repeat()
return dataset.batch(batch_size)
'''
# input_fn 확인
example = input_fn(train[0:3],train_y[0:3],training=False,batch_size=3)
for train,label in example:
print(train)
print(label)
'''
Define the feature columns
Model에서 Data로 들어오는 것에서의 특정 Feature를 찾는 단계이다.
tf.feature_column.numeric_column(key=key)를 통하여 Input으로 들어오는 Dict Type{‘feature’: Tensor}중 Numeric Type의 Tensor에 대한 정보를 my_feature_columns에 추가한다.
위와 같은 tf.feature_column.numeric_column()을 사용하게 되면 다양한 형태의 Data를 쉽게 변환 가능하다.
예를 들어 범주형(categorical) 데이터를 Sparse Vector 즉, one-hot 인코딩 해주며, 또는 수치형 데이터를 구간별로 버킷화 한 뒤 더미 인코딩을 실시한다.
categorical_column_with_vocabulary_list() 사용예시
위의 Code는 범주형(categorical) 변수를 one-hot Vector로서 Mapping하는데 사용된다.
사진 출처: excelsior-cjh 블로그
자세한 사항은 다음 Post에서 다룬다.
참조: tf.feature_column.numeric_column() 설명서

1
2
3
4
5
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
print(my_feature_columns)
[NumericColumn(key='SepalLength', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None), NumericColumn(key='SepalWidth', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None), NumericColumn(key='PetalLength', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None), NumericColumn(key='PetalWidth', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)]
Instantiate an estimator
미리 정의되어 있는 tf.estimator.DNNClassifier()를 통하여 Estimator Object를 선언한다. 각각의 Argument는 다음의 의미를 가지고 있다.
- feature_columns: 사용할 Feature
- hidden_uints: Hidden Layer 선언 ex)
hidden_units=[30, 10]를 Diemnsion관점으로 살펴보게 되면 Input -> Dense(30) -> Dense(10)으로서 선언된다. - n_classes: 최종적인 Output의 Dimension(현재 Species가 3개이므로 3으로서 선언한다.)
1
2
3
4
5
6
7
# Build a DNN with 2 hidden layers with 30 and 10 hidden nodes each.
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 30 and 10 nodes respectively.
hidden_units=[30, 10],
# The model must choose between 3 classes.
n_classes=3)
INFO:tensorflow:Using default config.
WARNING:tensorflow:Using temporary folder as model directory: /tmp/tmp7eot2fe3
INFO:tensorflow:Using config: {'_model_dir': '/tmp/tmp7eot2fe3', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_session_creation_timeout_secs': 7200, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7f9779081110>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
Train, Evaluate, and Predict
위에서 선언한 Estimater를 활용하여 실제 Model을 구성하고 Train 및 Prediction까지 실시한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# Train the Model.
classifier.train(input_fn=lambda: input_fn(train, train_y, training=True),steps=5000)
# Evaluate the trained model
eval_result = classifier.evaluate(input_fn=lambda: input_fn(test, test_y, training=False))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
# Making predictions (inferring) from the trained model
# Generate predictions from the model
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
def input_fn(features, batch_size=256):
"""An input function for prediction."""
# Convert the inputs to a Dataset without labels.
return tf.data.Dataset.from_tensor_slices(dict(features)).batch(batch_size)
predictions = classifier.predict(
input_fn=lambda: input_fn(predict_x))
for pred_dict, expec in zip(predictions, expected):
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print('Prediction is "{}" ({:.1f}%), expected "{}"'.format(
SPECIES[class_id], 100 * probability, expec))
Call initializer instance with the dtype argument instead of passing it to the constructor
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Create CheckpointSaverHook.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Saving checkpoints for 0 into /tmp/tmp7eot2fe3/model.ckpt.
INFO:tensorflow:loss = 1.6977032, step = 0
INFO:tensorflow:global_step/sec: 340.353
...
Test set accuracy: 0.833
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/tmp7eot2fe3/model.ckpt-5000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
Prediction is "Setosa" (68.4%), expected "Setosa"
Prediction is "Virginica" (45.0%), expected "Versicolor"
Prediction is "Virginica" (60.6%), expected "Virginica"
Build a linear model with Estimators
Estimators를 활용하여 Linear한 Model을 Build하는 과정이다.
하나의 end-to-end wlakthrough trains a logistic regression model을 Build하는 과정이라고 생가하면 된다.
Load he titanic dataset
Titanid dataset을 다운받고 확인한다.
1
2
3
4
5
6
7
# Load dataset.
dftrain = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/train.csv')
dfeval = pd.read_csv('https://storage.googleapis.com/tf-datasets/titanic/eval.csv')
# Label 설정
y_train = dftrain.pop('survived')
y_eval = dfeval.pop('survived')
Explore the Data
Pandas로 이루워진 Dataset에 대한 전반적인 정보를 확인하는 방법에 대해서 알아본다.
.head(): 상위 몇 개에 대한 Dataset을 확인한다..describe(): Numberic Feature들의 상세 정보를 출력해준다..shape(): Dataset의 Shape를 출려한다..hist(), .plot(): Matplotlib형식 으로서 결과를 Visualization한다..value_counts(): Data의 Value별로 Counts를 계산한다.
Pandas란 파이썬에서 사용하는 데이터 분석 라이므러리로서 꼭 알고 지나가야하는 도구 입니다.
Pandas에 대하여 사전지식이 없으신 분들은 아래 링크를 참조하시길 바랍니다.
참조: Pandas
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# Dataset 확인
print('Dataset 확인')
print(dftrain.head())
print()
# Label 확인
print('Label 확인')
print(y_train.head())
print()
# Dataset 상세 정보 확인(Numberic Feature들의 상세 정보를 출력해준다.)
print('Dataset 상세 정보 확인')
print(dftrain.describe())
print()
# Dataset Shape 확인
print('Datase Shape 확인')
print('Train Data Shape', dftrain.shape)
print('Test Data Shape', dfeval.shape)
print()
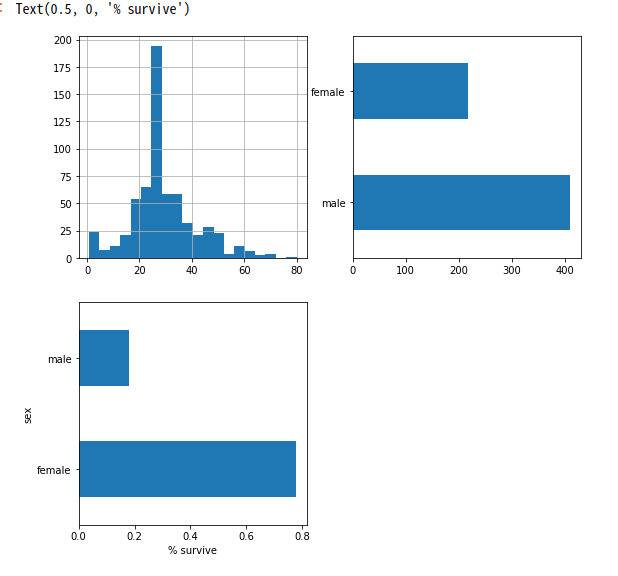
plt.figure(figsize=(9,9))
# Histogram 그리기
plt.subplot(221)
print('Age Histogram')
dftrain['age'].hist(bins=20)
# Plt 그리기
plt.subplot(222)
print('Sex Plot')
dftrain.sex.value_counts().plot(kind='barh')
# 조건으로서 Data Select하기
plt.subplot(223)
print('Selected Data Visualization')
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')
Dataset 확인
sex age n_siblings_spouses parch fare class deck \
0 male 22.0 1 0 7.2500 Third unknown
1 female 38.0 1 0 71.2833 First C
2 female 26.0 0 0 7.9250 Third unknown
3 female 35.0 1 0 53.1000 First C
4 male 28.0 0 0 8.4583 Third unknown
embark_town alone
0 Southampton n
1 Cherbourg n
2 Southampton y
3 Southampton n
4 Queenstown y
Label 확인
0 0
1 1
2 1
3 1
4 0
Name: survived, dtype: int64
Dataset 상세 정보 확인
age n_siblings_spouses parch fare
count 627.000000 627.000000 627.000000 627.000000
mean 29.631308 0.545455 0.379585 34.385399
std 12.511818 1.151090 0.792999 54.597730
min 0.750000 0.000000 0.000000 0.000000
25% 23.000000 0.000000 0.000000 7.895800
50% 28.000000 0.000000 0.000000 15.045800
75% 35.000000 1.000000 0.000000 31.387500
max 80.000000 8.000000 5.000000 512.329200
Datase Shape 확인
Train Data Shape (627, 9)
Test Data Shape (264, 9)
Age Histogram
Sex Plot
Selected Data Visualization
Base Feature Columns
위에서 언급한 Feature Columns와 Input Function을 정의한다.
크게 다음과 같은 2가지 방식으로서 Ipnput Data를 변형 시킨뒤 사용한다.
tf.feature_column.numeric_column(): Numeric Data는 tf.feature_column.numeric_columns를 활용하여 사용한다.tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary): Categorical Data는 One-Hot-Encoding으로서 변경한 뒤 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# Feature_columns 설정
CATEGORICAL_COLUMNS = ['sex', 'n_siblings_spouses', 'parch', 'class', 'deck',
'embark_town', 'alone']
NUMERIC_COLUMNS = ['age', 'fare']
feature_columns = []
for feature_name in CATEGORICAL_COLUMNS:
vocabulary = dftrain[feature_name].unique()
feature_columns.append(tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary))
for feature_name in NUMERIC_COLUMNS:
feature_columns.append(tf.feature_column.numeric_column(feature_name, dtype=tf.float32))
# Feature_columns 확인
print('Feature Columns')
for f_c in feature_columns:
print(f_c)
print()
# Input Function 선언 => Batch + Epoch만큼 Dataset을 가져온다.
def make_input_fn(data_df, label_df, num_epochs=10, shuffle=True, batch_size=32):
def input_function():
ds = tf.data.Dataset.from_tensor_slices((dict(data_df), label_df))
if shuffle:
ds = ds.shuffle(1000)
ds = ds.batch(batch_size).repeat(num_epochs)
return ds
return input_function
train_input_fn = make_input_fn(dftrain, y_train)
eval_input_fn = make_input_fn(dfeval, y_eval, num_epochs=1, shuffle=False)
# Input Function Check
ds = make_input_fn(dftrain, y_train, batch_size=10)()
print('Input Function Check')
for feature_batch, label_batch in ds.take(1):
print('Some feature keys:', list(feature_batch.keys()))
print()
print('A batch of class:', feature_batch['class'].numpy())
print()
print('A batch of Labels:', label_batch.numpy())
print()
# Check Numeric Data Format After Data Preprocessing
print('Check Numeric Data(Age) Format After Data Preprocessing')
age_column = feature_columns[7]
print(tf.keras.layers.DenseFeatures([age_column])(feature_batch).numpy())
print()
# Check Categorical Data Format After Data Preprocessing
print('Check Categorical Data(Gender) Format After Data Preprocessing')
gender_column = feature_columns[0]
tf.keras.layers.DenseFeatures([tf.feature_column.indicator_column(gender_column)])(feature_batch).numpy()
Feature Columns
VocabularyListCategoricalColumn(key='sex', vocabulary_list=('male', 'female'), dtype=tf.string, default_value=-1, num_oov_buckets=0)
VocabularyListCategoricalColumn(key='n_siblings_spouses', vocabulary_list=(1, 0, 3, 4, 2, 5, 8), dtype=tf.int64, default_value=-1, num_oov_buckets=0)
VocabularyListCategoricalColumn(key='parch', vocabulary_list=(0, 1, 2, 5, 3, 4), dtype=tf.int64, default_value=-1, num_oov_buckets=0)
VocabularyListCategoricalColumn(key='class', vocabulary_list=('Third', 'First', 'Second'), dtype=tf.string, default_value=-1, num_oov_buckets=0)
VocabularyListCategoricalColumn(key='deck', vocabulary_list=('unknown', 'C', 'G', 'A', 'B', 'D', 'F', 'E'), dtype=tf.string, default_value=-1, num_oov_buckets=0)
VocabularyListCategoricalColumn(key='embark_town', vocabulary_list=('Southampton', 'Cherbourg', 'Queenstown', 'unknown'), dtype=tf.string, default_value=-1, num_oov_buckets=0)
VocabularyListCategoricalColumn(key='alone', vocabulary_list=('n', 'y'), dtype=tf.string, default_value=-1, num_oov_buckets=0)
NumericColumn(key='age', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='fare', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
Input Function Check
Some feature keys: ['sex', 'age', 'n_siblings_spouses', 'parch', 'fare', 'class', 'deck', 'embark_town', 'alone']
A batch of class: [b'First' b'Third' b'Third' b'First' b'Third' b'Third' b'First' b'Third'
b'Third' b'Third']
A batch of Labels: [0 1 0 1 0 0 1 0 1 1]
Check Numeric Data(Age) Format After Data Preprocessing
[[65. ]
[ 3. ]
[40.5]
[28. ]
[28. ]
[28. ]
[35. ]
[ 9. ]
[17. ]
[20. ]]
Check Categorical Data(Gender) Format After Data Preprocessing
array([[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[1., 0.],
[0., 1.],
[0., 1.],
[0., 1.],
[1., 0.]], dtype=float32)
Model 생성 및 결과 확인
tf.estimator.LinearClassifier()를 활용하여 Model을 생성하고 결과를 확인한다.
1
2
3
4
5
6
linear_est = tf.estimator.LinearClassifier(feature_columns=feature_columns)
linear_est.train(train_input_fn)
result = linear_est.evaluate(eval_input_fn)
clear_output()
print(result)
{'accuracy': 0.77272725, 'accuracy_baseline': 0.625, 'auc': 0.8375268, 'auc_precision_recall': 0.7885603, 'average_loss': 0.47647125, 'label/mean': 0.375, 'loss': 0.4674509, 'precision': 0.7241379, 'prediction/mean': 0.33631855, 'recall': 0.6363636, 'global_step': 200}
Create an Estimator form a Keras model
위에서 Estimator의 종류 중 하나로서 Keras Model도 소개하였다.
이러한 Keras또한 Tensorflow에서 지원하는 tf.estimator를 사용하여 구성할 수 있다.
Create a simple Keras model
간단한 Keras Model을 구성한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
def create_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(16, activation='relu', input_shape=(4,)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='categorical_crossentropy', optimizer='adam')
return model
model = create_model()
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 16) 80
_________________________________________________________________
dropout (Dropout) (None, 16) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 97
Trainable params: 97
Non-trainable params: 0
_________________________________________________________________
create an input function
Iris Dataset을 다운받고 Dict Type으로서 설정하는 과정을 거친다.
1
2
3
4
5
6
7
8
9
10
11
def input_fn():
split = tfds.Split.TRAIN
dataset = tfds.load('iris', split=split, as_supervised=True)
dataset = dataset.map(lambda features, labels: ({'dense_input':features}, labels))
dataset = dataset.batch(32).repeat()
return dataset
# Chek Data
for features_batch, labels_batch in input_fn().take(1):
print(features_batch)
print(labels_batch)
{'dense_input': <tf.Tensor: id=6964, shape=(32, 4), dtype=float32, numpy=
array([[6.1, 2.8, 4.7, 1.2],
[5.7, 3.8, 1.7, 0.3],
[7.7, 2.6, 6.9, 2.3],
[6. , 2.9, 4.5, 1.5],
[6.8, 2.8, 4.8, 1.4],
[5.4, 3.4, 1.5, 0.4],
[5.6, 2.9, 3.6, 1.3],
[6.9, 3.1, 5.1, 2.3],
[6.2, 2.2, 4.5, 1.5],
[5.8, 2.7, 3.9, 1.2],
[6.5, 3.2, 5.1, 2. ],
[4.8, 3. , 1.4, 0.1],
[5.5, 3.5, 1.3, 0.2],
[4.9, 3.1, 1.5, 0.1],
[5.1, 3.8, 1.5, 0.3],
[6.3, 3.3, 4.7, 1.6],
[6.5, 3. , 5.8, 2.2],
[5.6, 2.5, 3.9, 1.1],
[5.7, 2.8, 4.5, 1.3],
[6.4, 2.8, 5.6, 2.2],
[4.7, 3.2, 1.6, 0.2],
[6.1, 3. , 4.9, 1.8],
[5. , 3.4, 1.6, 0.4],
[6.4, 2.8, 5.6, 2.1],
[7.9, 3.8, 6.4, 2. ],
[6.7, 3. , 5.2, 2.3],
[6.7, 2.5, 5.8, 1.8],
[6.8, 3.2, 5.9, 2.3],
[4.8, 3. , 1.4, 0.3],
[4.8, 3.1, 1.6, 0.2],
[4.6, 3.6, 1. , 0.2],
[5.7, 4.4, 1.5, 0.4]], dtype=float32)>}
tf.Tensor([1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0], shape=(32,), dtype=int64)
Create an Estimator form the tf.keras model
Keras Model을 tf.keras.estimator.model_to_estimator를 통하여 tf.estimator로서 변경하여 결과를 확인한다.
결과 Directory를 확인하면 다음과 같다.
./Model/tfkeras_example/
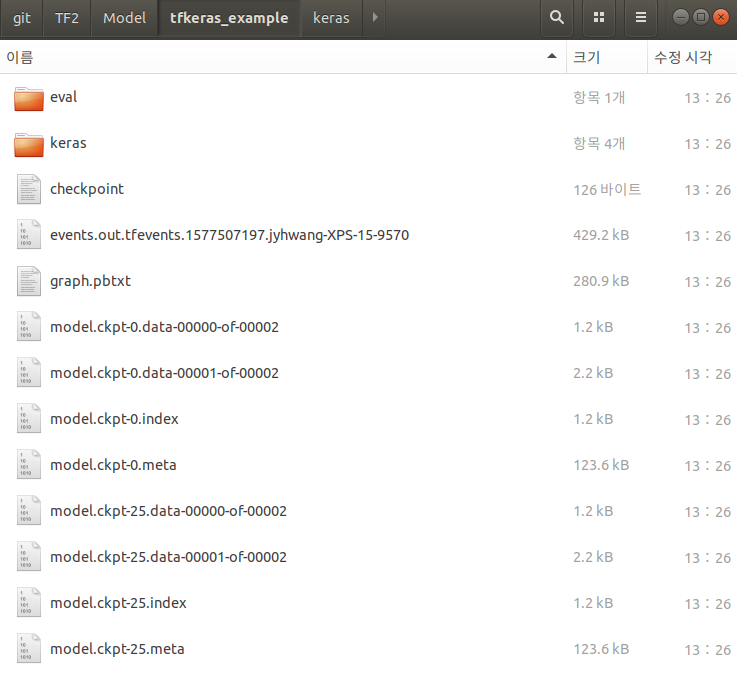
./Model/tfkeras_example/Keras
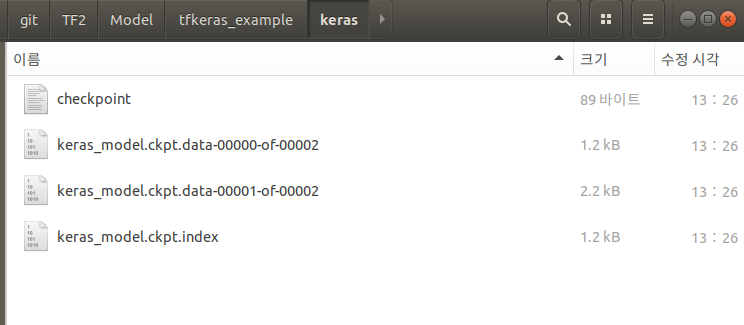
위에서 Keras -> Estimator로서 변경하였으므로 Keras Model을 사용할 수 있는 Folder와 Data 전처리 + Keras Model 인 Estimator를 사용할 수 있다.
1
2
3
4
5
6
7
model_dir = "./Model/tfkeras_example/"
keras_estimator = tf.keras.estimator.model_to_estimator(
keras_model=model, model_dir=model_dir)
keras_estimator.train(input_fn=input_fn, steps=25)
eval_result = keras_estimator.evaluate(input_fn=input_fn, steps=10)
print('Eval result: {}'.format(eval_result))
...
INFO:tensorflow:Evaluation [10/10]
INFO:tensorflow:Finished evaluation at 2019-12-28-13:48:31
INFO:tensorflow:Finished evaluation at 2019-12-28-13:48:31
INFO:tensorflow:Saving dict for global step 75: global_step = 75, loss = 100.03222
INFO:tensorflow:Saving dict for global step 75: global_step = 75, loss = 100.03222
INFO:tensorflow:Saving 'checkpoint_path' summary for global step 75: ./Model/tfkeras_example/model.ckpt-75
INFO:tensorflow:Saving 'checkpoint_path' summary for global step 75: ./Model/tfkeras_example/model.ckpt-75
Eval result: {'loss': 100.03222, 'global_step': 75}
Estimator 사용 결과 Keras에 익숙해져 있어서 인지 Keras가 더 편하고 자주 사용할 거이라고 생각된다…
참조: 원본코드
참조: excelsior-cjh 블로그
참조: Estimator
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment