
About
AI Developer
2019년에 졸업을 하여 현재 AI분야에 대한 전문가가 되기위하여 노력하고 있는 Programmer입니다.
AI에서도 Vision분야, DeepLearning 분야에 대해 관심이 많고 또한 Workflow 구현을 위한 Infra에 대해서도 관심이 많습니다.
Career
- 한국외국어 대학교 :: 2013. 03. ~ 2020.02.(졸업)
- 클라우드 기반 빅데이터분석 및 자바 딥러닝 개발자(국비교육) :: 2019. 01. ~ 2019. 07.
- 2019 머신러닝 스터디 잼 심화반 :: 2019. 06. ~ 2019. 07.
- PopcornSAR :: 2019. 08. ~ Today.
certificate
- 정보처리기사 [2018/05/25]: 18201230170A
- 정보통신기사 [2018/08/31]: 18-71-0155
- ADSP [2019/05/25]
- TOEIC [ ~ 2021/02/10]: 690
Skill
- Language - JAVA / Python / R
- Database - MySQL / NoSQL(Mongo DB)
- Infra - Docker / Kubernetes / Kubeflow
- AI - Pytorch / Tensorflow(1.x) / Keras / Tensorflow(2.0)
- Vision - OpenCV (Python)
- Windows & Linux Platform
- Web Based Server & Tools - JS / JSP / JQuery / Spring / Django
PROJECT
2020 DREAM_AI Healthcare Hackathon
2020 Dream AI Healthcare Hackathon은 NVIDIA에서 주체한 Hackathon에서 HealthCare부분 Covid19에 대한 의료 진단 챌린지에 참가하게 되었습니다. COVID를 판단할 수 있는 Image와 Audio의 Multimodality Model을 만듦으로서 COVID Prediction의 성능을 올릴 수 있습니다. 해당 Project에서 Modeling을 담당하였습니다.
팀원: 황정용, 김경덕, 김종범
프로젝트 기간: 3주
입상: 4등
Project Directory: https://github.com/wjddyd66/Project/tree/master/COVID
Motivation
현재 전세계적으로 COVID-19로 인해 매우 심각한 위기해 있습니다. COVIDIA는 이 프로젝트에 참여하여 COVID-19를 보다 정확하고 빠르게 진담함으로서 COVID-19예방에 도움이 되고자 참가하였습니다.
Audio Model
Audio Model를 Modeling하기 위한 Dataset은 .wav File -> Spectrum으로 바꿔서 사용하였으며, Unbalanced한 Dataset을 맞추기 위하여, Augmentation을 실시하였으며, 또한 Oversampling을 실시하였습니다.
Dataset
- https://github.com/iiscleap/Coswara-Data
- https://github.com/virufy/covid
- Train: 3108: pos: 508, neg: 2532
- Validation: 220: pos: 110, neg: 110
- Test: 100: pos: 50, neg: 50
Data Preprocessing
Data Preprocessing (1) - Spectrum
.wav sound file -> LobROSA package -> STFT(Short Time Fourier Transform) -> Mel Scale
Data Preprocessing(2) - Signal Clipping
The length of the sound data was different we set the time to 3 seconds, the time when the cough sound was properly mixed.
Data Preprocessing(3) - Data Augmentation
Time Shifting -> Time stretching(speed up) -> Time stretching(speed down) -> Pitch Shifting -> Oversampling
Result of preprocessing
cough sound in corona negative patients

cough sound in corona Positive patients

Audio Model은 Pretrain된 Dense Net을 사용하였으며, Performance는 Test Accuracy: 76%입니다.
Image Model
Contribution
저희 팀은 의사가 환자를 식별하는 것과 동일하게 작동하는 Model을 만들려고 했습니다.
기본적으로 의사는 환자의 COVID CT를 보고 다음과 같은 순서로 판단한다고 생각합니다.
- Check the suspected part of the patient’s CT as COVID.
- Determine whether it is COVID by looking at the progress or characteristics of the part.
1의 과정을 수행하기 위하여, Segmentation Model을 사용하였습니다. FCN, U-net, Inf-Net이 Segmentation Model의 후보가 돠었고, 최종적으로는 Inf-Net이 선택되었습니다.
2의 과정을 수행하기 위하여, Segmentation의 결과를 mask처럼 사용하여 환자 Ct에서 의심되는 부분을 강조 할 수 있는 “Attention”효과를 기대하였다. Classification Model의 후보로는 VGG, ResNet, Densenet이 후보로 선정되었으며, DenseNet이 최종적으로 선택되었습니다.
Appendix. COVID Image Dataset으로서 X-ray와 CT가 많이 사용되지만, Segmentation의 Dataset은 CT밖에 없어, CT를 Dataset으로서 사용하였습니다.
Classification Model
- Paper: COVID-CT-Dataset: A CT Image Dataset about COVID-19 (https://arxiv.org/pdf/2003.13865.pdf)
- Code: COVID-CT (https://github.com/UCSD-AI4H/COVID-CT)
Dataset
The COVID-CT-Dataset has 349 CT images containing clinical findings of COVID-19 from 216 patients.
The images are collected from COVID19-related papers from medRxiv, bioRxiv, NEJM, JAMA, Lancet, etc. CTs containing COVID-19 abnormalities are selected by reading the figure captions in the papers. All copyrights of the data belong to the authors and publishers of these papers.
The dataset details are described in this preprint: COVID-CT-Dataset: A CT Scan Dataset about COVID-19
Model
Paper에서 제공하는 Dataset으로서 Model의 Performance는 다음과 같다.
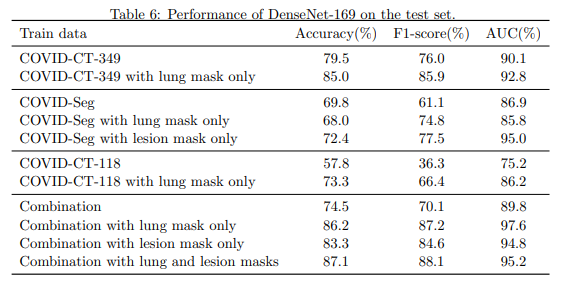
BaseLine’s Model (COVID-CT-349) standard, AUC is 90.1%.
Paper와 동일하게 Dataset을 구축하고, Model을 구축하였을때 위와 같은 결과를 얻었습니다. 하지만, Hyperparameter Tuning을 하는데 Validation Dataset을 사용하지 않았습니다. 따라서 저희는 Validation Dataset을 사용하여 Early Stopping을 사용하였습니다. 또한, Early Stopping을 사용하다 보니, Epoch가 너무빨리 끝나는 것을 알게 되어 Learning Rate를 1e-3 => 1e-6으로 줄인 뒤 Performance는 다음과 같습니다.
- F1: 0.93658
- Accuracy: 0.93596
- AUC: 0.98425
저희는 위의 Performance를 BaseLine Performance로서 잡고 Experiment를 수행하였습니다.
Segmentation Model
- Paper: Inf-Net: Automatic COVID-19 Lung Infection Segmentation from CT Images(https://arxiv.org/pdf/2004.14133.pdf)
- Code: Inf-Net: Automatic COVID-19 Lung Infection Segmentation from CT Images (https://github.com/DengPingFan/Inf-Net)
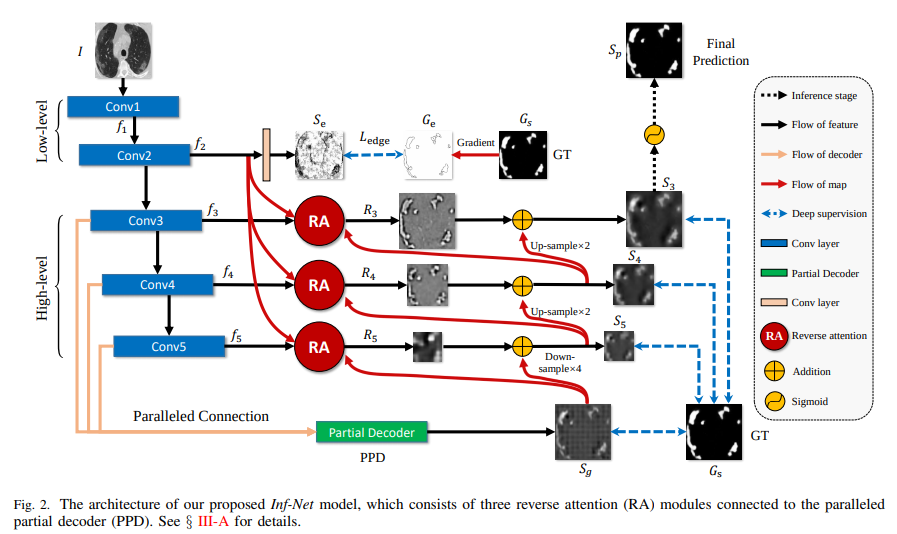
현재 Segmentation Model로 선정 된 InfNet은 다음과 같은 특징을 가지고 있습니다.
Edge Attention
많은 이미지 모델에서 Edge는 중요한 정보가됩니다. 특히 COVID CT를 생각해보면, Back Ground와 Lung을 비교하고 Lung안에서도 COVID로 의심되는 부분을 찾는데 Edge는 중요한 정보가 될 것 이다.
Paralleled partial decoder
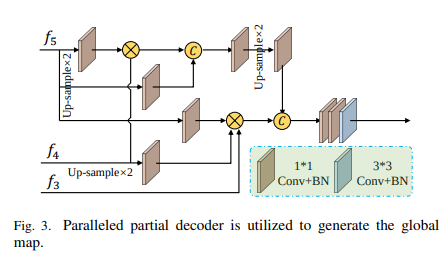
U-Net의 경우 최종 출력이 하나의 Output임을 알 수 있습니다. 즉, Down Sampling이 Up Sampling 결과에 연결되었지만 최종 Output은 하나뿐이므로 Gradient Vanishing이 발생할 수 있다. 그러나 InfNet은 PPD를 사용하여이 문제를 해결했습니다. 위의 그림을 보면 PPD가 Up Sampling을하면서 각 Down Sampling의 결과를 곱하여 전체적으로 Down Sampling의 모든 특성을 추출하는 역할을한다는 것을 알 수 있습니다.
-
\(S_g\) is created by combining the general characteristics of the image and specific characteristics.
-
By adding this \(S_g\) to each downsampling, the overall characteristics and the output characteristics of the convolution layer are all the same.
-
By calculating the loss directly to the output of all downsampling, it can be used more directly for the gradient vanishing and each feature.
Result
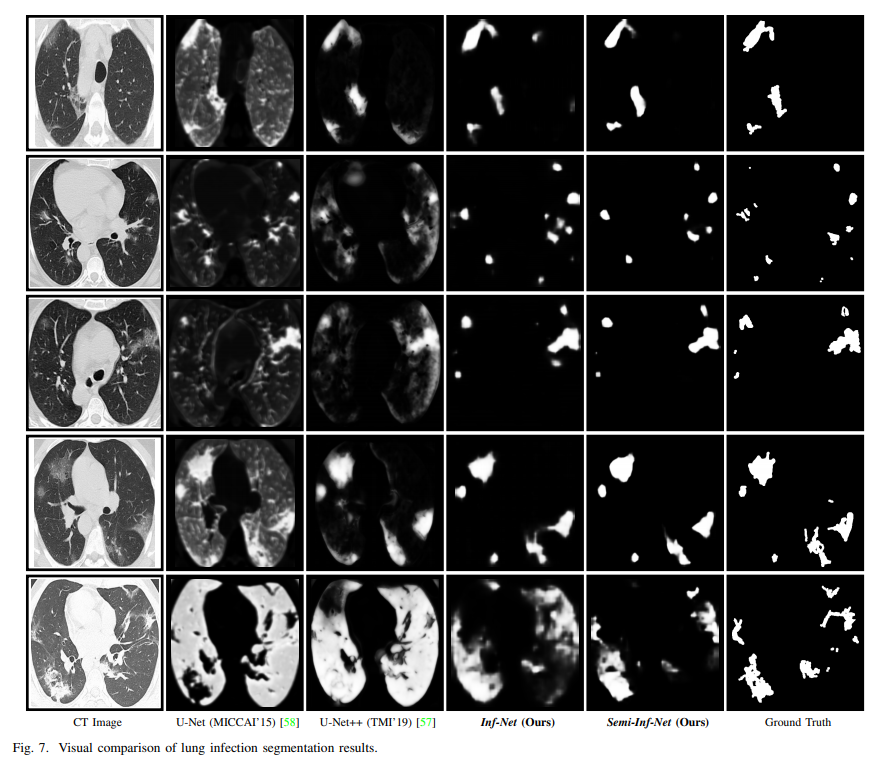
결과를 보면 U-Net보다 더 Sharp하게 Ground Truth를 포착하고 있음을 알 수 있습니다.
실제로 U-Net과 FCN을 학습하고 결과를 확인했을 때 논문에서와 같이 폐를 전체적으로 잡는 결과를 보여, InfNet 모델을 선택했습니다.
Classification with Mask
먼저 InfNet의 Segmentation 결과 Mask를 사용하기 위해서는 다음과 같은 Hyperparameter를 설정해야합니다.
-
위에서 볼 수 있듯이 InfNet의 Output은 5가지 입니다.. Edge(\(S_e\)), Conv3 Output(\(S_3\)), Conv4 Output(\(S_4\)), Conv5 Output(\(S_5\)), PPD Output(\(S_g\)). 만약 \(S_5\) 이 사용된다면, 전체적인 Feature을 사용하게 되고, \(S_3\) 을 사용하게 되면 좀 더 Specific한 Feature를 사용한다.
-
InfNet의 Segmentation 결과 BackGround으로 판단되는 모든 부분은 0 입니다. 이것을 마스크로 사용하면 세분화 모델이 100 % Ground Truth를 캡처해도 문제가 없지만 실제 분류 모델은 어느 정도 주변 정보를 사용합니다. 따라서 분할 결과의 COVID가 아닌 부분을 어느 정도까지 사용할 것인지도 Hyperparameter로 선택해야합니다.
위의 과정을 그림으로 나타내면 다음과 같다.
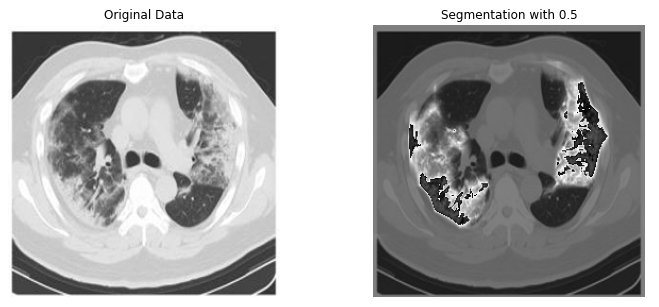
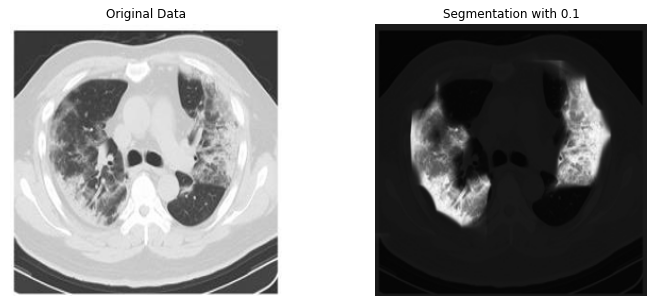
Hyperparameter를 변경하면서, Validation Loss가 가장 낮은 Hyperparameter의 Test Performance를 보면 다음과 같습니다.
- F1: 0.93658 -> 0.94930
- Accuracy: 0.93596 -> 0.94581
- AUC: 0.98425 -> 0.98765
대략적으로, 단순한 Classification Model보다 0.3%성능이 올랐습니다.
Multi Modality Model
Experiment Setting
There is no sample with all modality. = > Make Pair Dataset Randomly
EX) Train Image Random Sampling(500), Train Audio Random Sampling(500)
Num of Multimodality Dataset
- Train: COVID: 500 // Non-COVID: 500
- Validation: COVID: 100 // Non-COVID: 100 -Test: COVID: 100 // Non-COVID: 100
BaseLine-Multi Modality Model
Late Fusion
- DenseNet Feature Extractor Output Shape: 1664
- Input: 1664*2(Concat) → 835 → 100 → 2 → Softmax → Prediction
- Activation Function: ReLU
Result: TP=98, TN=86, FN=2, FP=14
- F1: 92.45
- Accuracy: 92
- AUC: 98.15
Late Fusion의 단점은 Feature Extractor가 Modality Specific하다는 것 이다. 따라서 MFAS로서 Architecture를 Search하여 확인하였다.
MFAS-Multi Modality Model
Configuration
config_1 = [[0,0,1], [0,1,0]]
config_2 = [[2,0,0], [1,1,1], [0,2,0]]
Config_3 = [[0,2,1], [2,0,0], [2,1,1]]
0에 가까울수록, Output단에 가깝다. [Image Feature Extractor, Audio Feature Extractor, Activation Function]
[x,x,0] => Sigmoid // [x,x,1] => ReLU
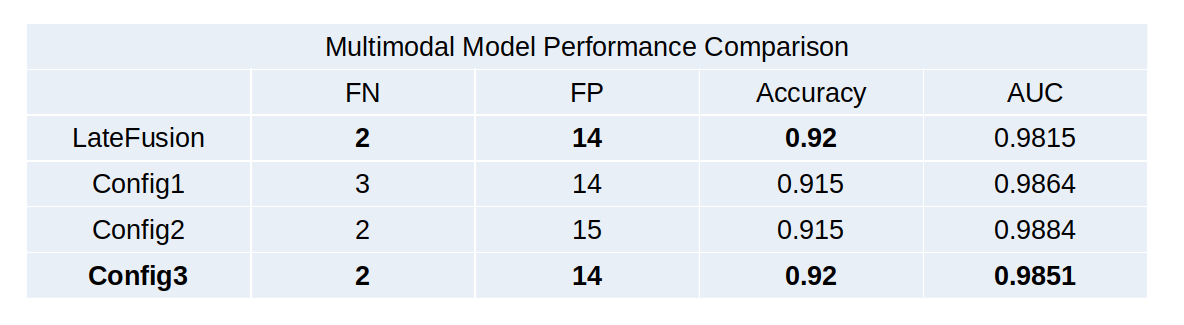
Effect of Multi Modality Model
단순히 Image Model의 성능이 높기 때문에, Multi Modality의 Model의 성능이 높을 수도 있다. 따라서 Hardest Dataset, Convertible Dataset을 구축하고 Multimodality의 효과를 확인한다.
Hardest Dataset: Test samples that were accurate predictioned in the image classification model but with low probability (Pairs for all audio samples with the same label) => Trheshold < 0.7 => Num of Sample: 13
- Late Fusion: 13.91% // - MFAS(Config3): 11.84%
Convertible Dataset: Test samples that were unaccurate predictioned in the image classification model but with high probability (Pairs for all audio samples with the same label) => Trheshold > 0.3
- Late Fusion: 19.38% // - MFAS(Config3): 18.44% => Convert 5 of 6 samples
Result of Convertible Dataset
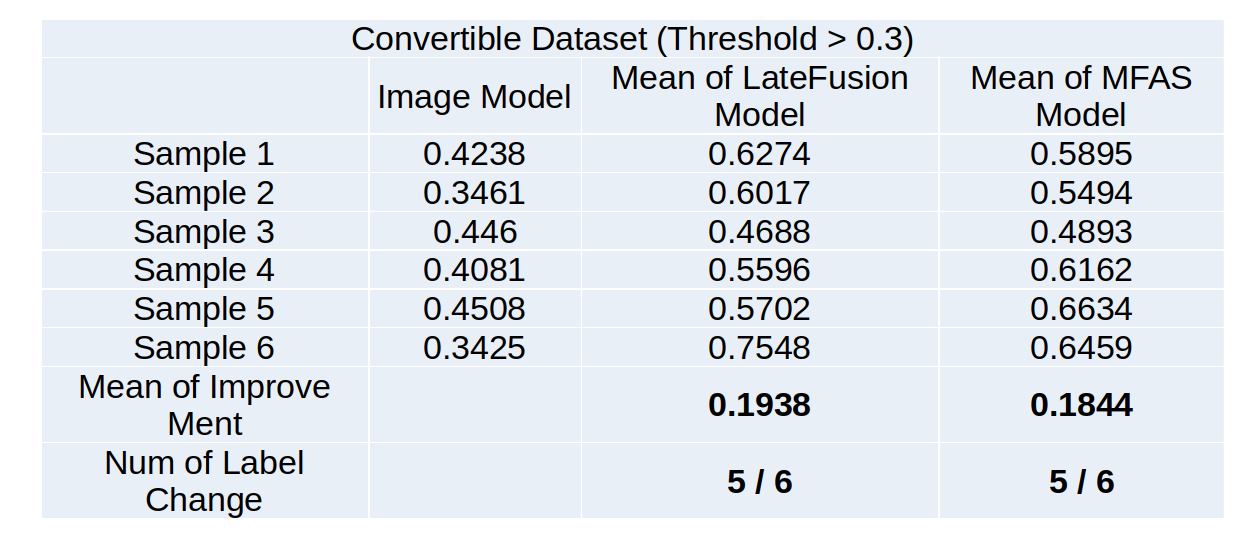
Result
Image Classification Model
The attention effect was expected by using the segmentation model as a mask, and the performance of the classification model was improved.
Audio Classification Model
The unbalanced problem of Audio Dataset was solved by Augmentation and Oversampling.
Multimodality Model
- Through Architecture Search, not just LateFusion, even though the accuracy is the same, we found a model with improved performance based on AUC.
- Hardest Dataset and Convertible Dataset were defined, and the COVID Classification performance improvement was proved as Multimodality in the defined Dataset.
Demo
Flask로서 Web Service단을 개발하였다.
Reference
[1] Paper: Inf-Net: Automatic COVID-19 Lung Infection Segmentation from CT Images(https://arxiv.org/pdf/2004.14133.pdf)
[2] Code: Inf-Net: Automatic COVID-19 Lung Infection Segmentation from CT Images (https://github.com/DengPingFan/Inf-Net)
[3] Paper: COVID-CT-Dataset: A CT Image Dataset about COVID-19 (https://arxiv.org/pdf/2003.13865.pdf)
[4] Code: COVID-CT (https://github.com/UCSD-AI4H/COVID-CT)
[5] Code: BackBone(res2net101_v1b_26w_4s: ‘https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net101_v1b_26w_4s-0812c246.pth)
[6] Audio Dataset: https://github.com/iiscleap/Coswara-Data
[7] Audio Dataset: https://github.com/virufy/covid
[8] Paper: MFAS(Multimodal Fusion Architecture Search) (https://openaccess.thecvf.com/content_CVPR_2019/papers/Perez-
Rua_MFAS_Multimodal_Fusion_Architecture_Search_CVPR_2019_paper.pdf)
[9] Paper: Efficient Progressive Neural Architecture Search (http://www.bmva.org/bmvc/2018/contents/papers/0291.pdf)
따봉 Django Project
따봉 Django Project는 실제 존재하는 따릉이 대여소와 기타 요인간의 상관관계분석을 통한 공공자전거 대여소 설치 구역 추천을 하는 시스템입니다.
팀원: 황정용, 김동혁, 안상민, 장보성, 천지훈, 표종은
프로젝트 기간: 2주
분석배경
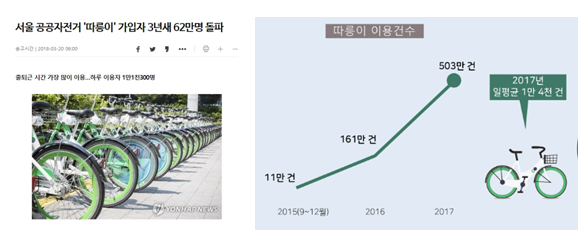
2015년 따릉이 사업 시작 이후로 따릉이 가입자 수가 지속적으로 증가
특히 이용자 수는 2016년 이후로 급증하는 추세를 보임
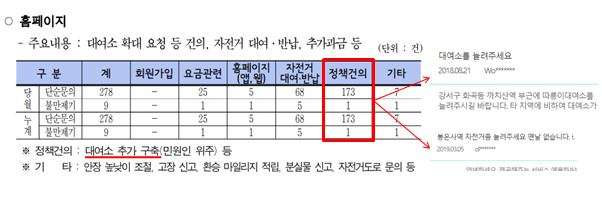
급증하는 이용자 수에 비해 대여소 수가 부족
2017년 기준 대여소 추가 구축 민원 173건
목적

대여소가 부족한 지역을 파악하는 것이 아닌 이용자 수가 많은 대여소를 파악하고 특징을 추출하여 새로운 대여소 설치시 적절한 위치 제안을 하는 것을 목적으로 한다.
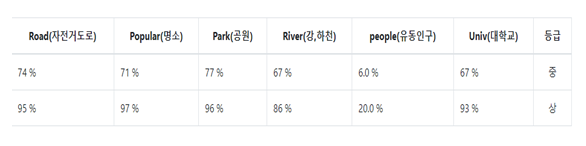
데이터 변수 설정
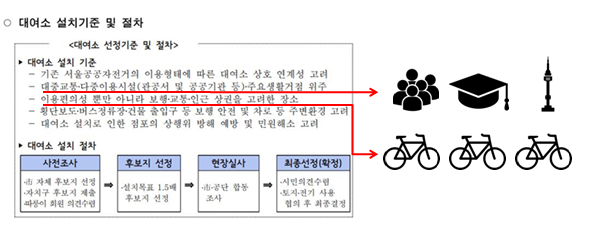
서울 시설공단 공공자전거운영처의 대여소 설치기준을 참고하여 유동인구, 대학교, 관광명소, 자전거도로를 변수로 설정
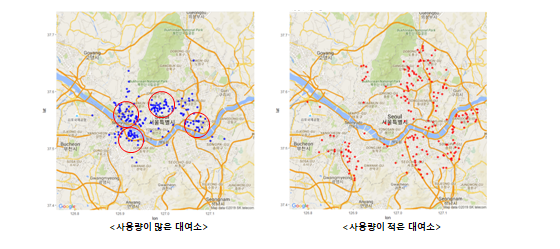
공공자전거 이용자수 상위 100개소를 지도에 표시한 결과 공원, 강 주변에 위치
공원, 강의 위치를 변수로 설정
자세한 내용
데이터 전처리
Euclidean거리 계산 방식 이용
대여소로부터 최단거리의 “대학교, 자전거도로, 관광명소, 공원, 강”까지의 거리를 도출
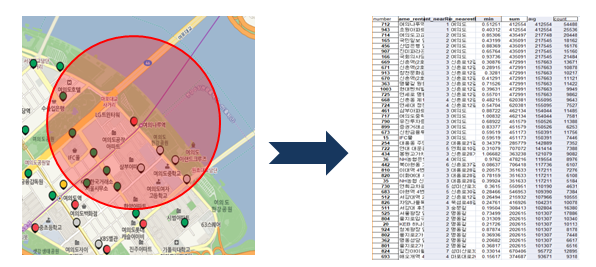
Euclidean거리 계산 방식 이용
대여소로부터 1.5km내, 관측소들의 유동인구 평균을 도출
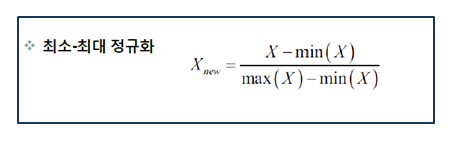
- 연속형, 입력변수에MIN-MAX Normalization를 통해 0~1값으로 치환
- 필요에 따라 연속형 변수 => 범주형 변수로 변경
- 결측치 처리: 구간별 중위수로 대체
최종 데이터
| 변수 | 설명 | 값 |
| Road | 근접 자전거도로 최단거리 | 연속형(0~1) |
| Popular | 근접 명소 최단거리 | 연속형(0~1) |
| Park | 근접 공원 최단거리 | 연속형(0~1) |
| River | 근접 강, 하천 최단거리 | 연속형(0~1) |
| People | 범위 안(1.5 km) 유동인구 평균 | 연속형(0~1) |
| Univ | 근접 대학교 최단거리 | 연속형(0~1) |
| Count | 대여소 이용횟수 | 범주형(1~3) |
Model 선정
| 모델 명 | 정확도(Traing) | 정확도(Test) | 과적합 여부 |
| MLPClassifier | 61.6 % | 61 % | X |
| GradientBoostingClassifie | 54.6 % | 52.2 % | X |
| K-NN | 57 % | 50 % | O |
| Decision Tree | 54 % | 50 % | X |
| SVM | 53 % | 52 % | X |
| Random Forest | 99.2 % | 52 % | O |
정확도가 가장높고, 과적합 하지 않은 모델 선정MLPClassifier가 모델로 선정
MLPClassifier
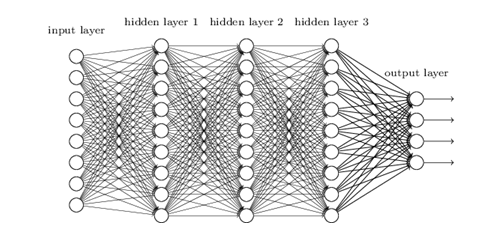
- 모델 구조 및 가정에서 최소의 요구를 가지고 있는 광범위한 예측 모델과 근사
- 모델 해석 가능성이 낮지만 좋은 예측력을 확보할 수 있음
Model Parameter 선택
| Parameter | 설명 | 값 |
| Hidden_Layer_Sizer | Hidden Layer 크기 설정 | (10,10,30) |
| max_iter | 최대 반복 횟수 | 3000 |
| alpha | L2 Regulation penalty | 0.0001 |
| activation | 활성 함수 | relu |
| solver | weight optimizer | adam |
| learning_rate | Schedule for weight updates | adaptive |
MLP Classifer 모델의 Parameter를 반복적으로 변경
최적의 변수 값을 선정 (정확도: 61~72%)
분석결과
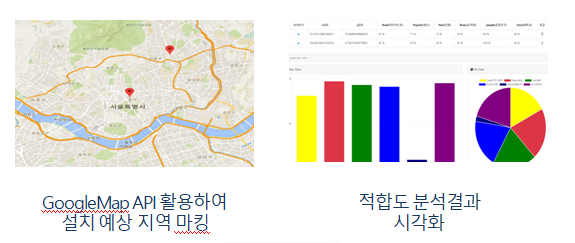
시연영상
결론
- 적합도 상위조건
- 강과 가까울수록 적합도가 높은 경향을 보인다.
- 자전거 도로와 인접할 수록 적합도가 높다.
- 등급분류기준
- 종합적 판정 결과 상위 20% = “상” , 하위 10% = “하”
- ‘상’ 등급 : 지정 위치에 대여소 설치 추천
- ‘중’ 등급: 내부 검토에 의해 설치
- ‘하’ 등급: 설치 지양
개선 방향
- 데이터 확장
- 타 지역으로 확장 시 해당시의 도로, 공원, 유동인구 등의 데이터가 필요
- 운용 가능한 데이터의 다양성 확보 필요
- 사업분야의 확장
- 공공 전동 킥보드 등의 대여 서비스로 확장 & 적용을 기대
- 도로 및 시설물의 인프라 확장에 정보 를 제공
- 기상, 비정량적 데이터 고려
- 시시각각 변하는 기상 데이터와의 연동 시스템 구축
- SNS등을 활용한 대중의 개별적 감정상태 반영
참고 사이트
서울시 열린데이터광장
구글맵
서울시설공단
서울 연구원
서울자전거 따릉이 –무인대여시스템 외 다수
BOM AIR(Best Of Most Airline & Rent Car) Spring Project
BOM AIR Spring Project는 실제 항공사들이 서비스하는 Flight Booking + Car Rent를 목표로 하여 만든 프로젝트 입니다.
팀원: 황정용, 김동혁, 안상민, 장보성, 천지훈, 표종은
프로젝트 기간: 2주
Use Case Diagram
실제 이용자가 사용하는 경우의 순서도를 Use Case Diagram으로 나타내었다.
사용자의 경우 크게 3가지로 나누었다.
| 사용자 | 사용 가능 기능 |
| Login을 하지 않은 사용자 |
|
| Login이 되어있는 사용자 |
|
| 관리자 |
|
각각의 사용자는 Session을 이용하여 판별하였다.
EXERD Diagram
DB는 Maria DB를 사용하였고, 프로젝트를 위한 DB의 설계는 아래의 그림과 같이 설계하였다.
Project Main Page
Project의 Main Page이다.
각각의 사용자를 Session에 이용하여 사용자를 판별하고 특정 사용자(관리자)의 경우 Header에 옵션을 주어 특정 기능이 보이도록 설계하였다.
Main Page에서 바로 최근 공지사항을 보이도록 하였고 공지사향의 내용이 길 경우 앞의 내용만 보이게 하여 화면이 깨지지 않게 구성하였다.
Project의 Main 기능인 항공권 예매와 렌트카 예매의 경우 바로 Main 화면에서 구매 가능하도록 구성하였다.
회원가입
회원 가입 같은 경우 회원의 ID를 Primary Key로서 사용하기 때문에 중복체크를 하여 확인하였다.
주소 입력같은 경우 모든 주소를 DB에 넣는 작업이 커질것을 우려하여 다음 API를 사용하여 주소를 입력하게 하였다.
ID, 비밀번호 찾기
계정의 정보를 잃어버려 ID, 비밀번호 찾기를 해야 하는경우, ID는 바로 보여줘도 상관없지만, 비밀번호 같은 경우 중요한 정보이므로 가입되어있는 Mail로 발송하는 식으로 구현하였다.
공지사항
공지사항인 경우 Main Page에서 보여지는 부분은 Ajax로서 처리하였다.
공지사항은 등록 수정, 삭제의 경우는 Session의 값이 관리자일때만 가능하게 하였다.
사용자의 경우 공지사항을 볼 수 밖에 없게 구성하였다.
공지사항의 보여주는 부분을 일정하게 보여주기 위하여 Pagination을 적용하였다.
많은 공지사항일 경우 원하는 정보를 보기 위하여 검색기능을 넣었다.
렌트카 등록
관리자의 경우 렌트카의 정보를 입력한 뒤 DB에 저장하게 되었다.
렌트카일 경우 차량의 사진을 File Upload하여 실제 저장소에 올라가게 구성하였다.
렌트카 예약
사용자의 경우 관리자가 등록한 렌트카를 예약할 수 있게 구성하였다.
예약을 하고 예약정보를 확인할 수 있게 구성하였다.
관리자- 항공편 등록, 매출 확인
관리자의 경우 게시판에서 특정한 작업원 권한을 부여받을 뿐 아니라, 항공편 생성 및 매출을 확인 가능하다.
매출의 경우 일단위는 달력 UI를 활용하여 한번에 볼 수 있게 구성하였고 매출에 대한 자세한 내용은 직접 들어가서 확인 가능하게 구성하였다.
비행기 예약
관리자가 비행기를 등록하고 나면, 등록되어있는 비행기를 사용자는 예약을 할 수 있다.
비행기의 조회는 Login이 되어있지 않은 사용자도 가능하지만, 예약은 불가능하게 구성하였다.
비행기를 예약하고 나면, 조회를 하여 예약정보를 확인할 수 있고 체크인 기능이 활성화 되도록 구성하였다.
체크인
체크인이란 예약 몇일전에 사용자가 직접 좌석을 고를 수 있는 System이다.
Class(일반, 비지니스, VIP)안에서 좌석을 고를 수 있으면 체크인을 하게 되면 티켓을 확인하여 Print하거나 E-mail로 발송하여 티켓을 확인할 수 있게 구성하였다.
체크인 화면
티켓 확인 환면
스케줄러
비행기의 티켓의 정보는 비행기가 도착하고 나서는 쓸모없는 Data가 된다.
매일매일 생기는 이러한 쓸모없는 많은 정보를 관리자가 삭제하는 것이 아닌 일정 시간기준으로 자동으로 작업을 시키기 위하여 스케줄러를 사용하였다.
Paper
자연어처리 기술을 활용한 생성형 문서요약
Abstract
인터넷과 정보통신 기술이 발달하면서 이제는 누구나 수 많은 정보에 접근 가능하게 되었다. 그러나 정보에 접근하기는 쉬워졌으나 이러한 정보를 잘 이용하는 것은 다른 문제이다. 자신에게 필요하고 유용한 정보만을 적은시간안에 획득하고 이용할 수 있다면 보다 효율적으로 인터넷과 정보통신 기술을 활용할 수 있게 될 것이다.
또한 과거일부의 사람만이 정보의 확산에기여했던것과는 다르게 최근에는 소셜네트워크서비스(SNS, Social Networking Service)의 확산에 따라 정보의 생성 및 전파가 그 어느 때와 다르게 활발하고 다양하게 이루어지고 있다. 이와 같이 누구나 정보의 생산과 전파가 가능하게 되어 많은 장점도 있으나 정제되지 않은 데이터들이 범람하고 있다. 한정된 시간 내에 신뢰성,의미,가치 있는 정보를 찾아내 위해서는 정보의 요약은 반드시 필요하다. 최근 한 조사결과에 따르면 현대인들의 미디어 소비에서 요약형 정보가 훨씬 선호되고 있음을 알 수 있는데 이 결과를 그림 1 를 통해 나타내었다.
그림 1. 현대인들의 미디어 소비
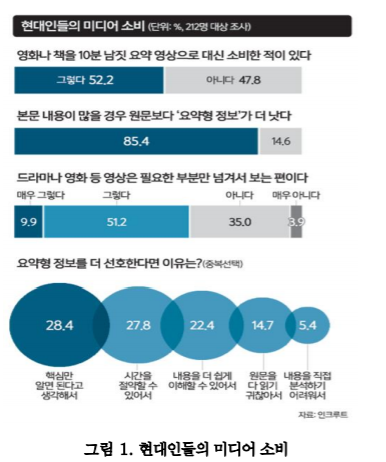
출처: [S 스토리] 핵심만 콕콕! 긴 것은 NO!… ‘요약’에 빠진 현대인들
그림 1 에서 전체 응답자의 85.4% 는 요약형 정보를 선호하는 것으로 나타났고 요약형 정보의 선호 이유로는 핵심만 알면 된다고 생각하는 것과 시간을 절약할 수 있는 것, 내용을 더 쉽게 이해할 수 있는 것 등의 이유를 들었다. 이처럼 요약형 정보는 현대인의 정보 이용에 있어서 중요한 역할을 담당하고 있고, 요구되고 있는 상황이다.
이에 따라서 요약기술 또한 요구 되고 있다. 현재 인터넷 상에서 생산되고 공유되는 정보의 대다수는
텍스트 정보이다. 따라서 많은 줄의 텍스트 데이터의 내용을 파악하고 중복적인 정보를 제거하는 문서요약 기법의 필요성이 대두되고 있으며 중요성 또한 점점 커지고 있다. 본 논문에서는 수 많은 텍스트 정보들을 효율적으로 확보, 이용하기 위한 방법으로 NLP(Natural Language Processing, 자연어 처리)를 활용 하여 텍스트 정보들을 요약하는 방법들에 대해 연구하려 한다.
참조 사항
실제로 논문을 정식 학회에 등록한 것이 아닌 학교 졸업논문을 작성하였습니다.
한국외국어대학교 정보통신학과 홈페이지에 접속하면 확인할 수 있으나 Login해야 하는 번거로움이 있어 다운로드 가능한 링크를 아래 첨부하였습니다.
PaperLink: 자연어처리 기술을 활용한 생성형 문서요약