
Paper04. MFAS(Multimodal Fusion Architecture Search)
MFAS
MFAS: Multimodal Fusion Architecture Search (https://openaccess.thecvf.com/content_CVPR_2019/papers/Perez-Rua_MFAS_Multimodal_Fusion_Architecture_Search_CVPR_2019_paper.pdf)
Efficient Progressive Neural Architecture
Search (http://www.bmva.org/bmvc/2018/contents/papers/0291.pdf)
Abstract
We tackle the problem of finding good architectures for multimodal classification problems. We propose a novel and generic search space that spans a large number of possible fusion architectures.
In order to find an optimal architecture for a given dataset in the proposed search space, we leverage an efficient sequential model-based exploration approach that is tailored for the problem.
We demonstrate the value of posing multimodal fusion as a neural architecture search problem by extensive experimentation on a toy dataset and two other real multimodal datasets.
We discover fusion architectures that exhibit state-of-the-art performance for problems with different domain and dataset size, including the NTU RGB+D dataset, the largest multimodal action recognition dataset available.
Abstract를 살펴보게 되면, Multimodal Fusion Model은 다양한 형태가 있고, 그에 따른 Architecture가 다양하다.
대표적인 Multimodal Fusion Model의 Architecture를 살펴보면 다음과 같다.
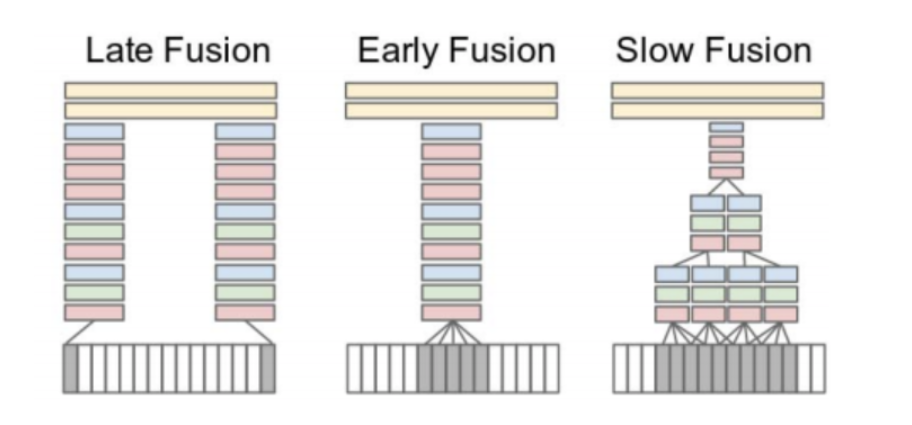
다양한 Architecture가 존재하게 되고, Multimodal Fusion Model또한 어떻게 Architecture를 구성하냐가 중요하다.
또한 여기서 강조하고 있는것은 NASnet 혹은 Unet과 마찬가지고 LateFusion이 아닌 서로 다른 PreTrain된 Feature Extractor의 Hidden Layer의 Combination으로서 Architecture를 구성하고, 이러한 Architecture의 Performance가 더 좋을 수 있다고 가정하는 것이다.
Define Search Space
해당 Paper에서 중요한 점은 Multimodal Fusion Model에서 Search Space를 정의하였다는 것 이다.
아래 그림은 해당 Paper에서 설명하는 예제이다. PreTrain 된 Feature Extractor가 2개 존재한다는 가정하에 다음과 같이 Search Space를 구성할 수 있다.
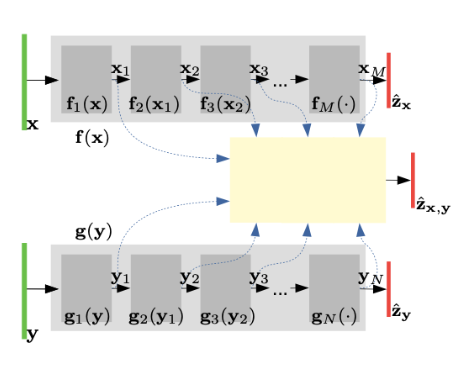
\(\gamma_l = (\gamma_l^m, \gamma_l^n, \gamma_l^p)\)
- Term1: L번째 Fusion Layer에서 들어오는 첫번째 Modality의 Feature
- Term2: L번째 Fusion Layer에서 들어오는 두번째 Modality의 Feature
- Term3: Fusion Layer의 Activation Function
즉, PreTrain된 Feature Extractor가 이미 존재한다고 가정하였을 때, ANN으로서 Classification Model로서 Prediction을 한다고 할 때, 위와 같이 Search Space를 정할 수 있다.
위와 같이 Search Space를 대략적으로 구성하고 ANN으로서 Classification Model을 선정하면 각각의 Hidden Layer는 다음과 같이 정의할 수 있다.
$$h_1 = \sigma_{\gamma_1^p} w_1 \begin{bmatrix} x_{\gamma_1^m} \\ y_{\gamma_1^n} \end{bmatrix}$$
$$h_l = \sigma_{\gamma_l^p} w_l \begin{bmatrix} x_{\gamma_l^m} \\ y_{\gamma_l^n} \\ h_{l-1} \end{bmatrix}$$
Paper에 Example로 든 Search Space를 예를 들면 다음과 같다.
- 첫 번째 Modality의 Feature Extractor의 Hidden Layer 갯수: M = 16
- 두 번째 Modality의 Feature Extractor의 Hidden Layer 갯수: N = 16
- ANN Classifier의 Activation Function 갯수: P = 2
- ANN Classifier의 최대 Layer 개수: L = 5
- Search Space ~ \((M x N x P)^L = 3,51 x 10^{13}\)
다음과 같이 Exponential하게 증가하는 Search Space를 모두 확인할 수 없으므로 Surrogate를 활용하여 Search Space를 Prediction하는 Model을 Training하여, Search Space를 모두 확인하지 않고, 일부 확인한 것을 토대로 나머지 Search Space를 Prediction하여 시간을 단축하였다.
Search Algorithm
Paper에서 언급하는 Search Algorithm은 다음과 같다.

Search Algorithm에서 Surrogate Model부분을 Efficient Progressive Neural Architecture Search Paper에서 살펴보면 다음과 같이 나타낼 수 있다.
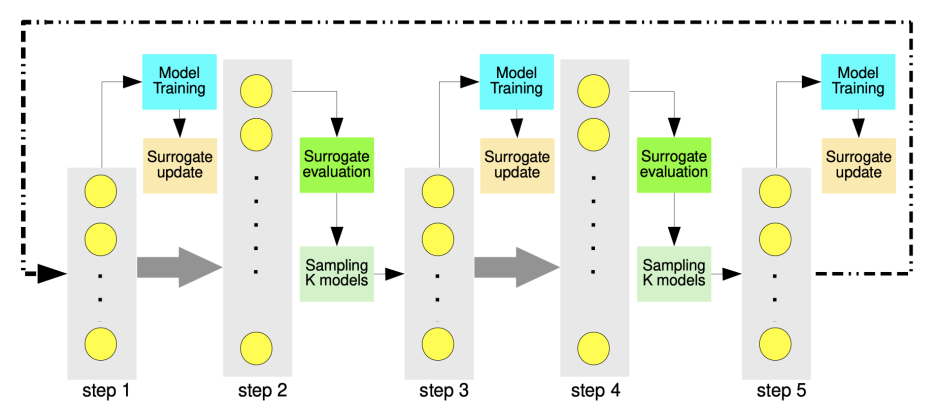
Algorhtim의 순서도를 파악하면 다음과 같다.
- Surrogate Model에서 1 Hidden Layer (L=1)에 대하여 모두 Training하여 결과 확인
- L=1에서 성능에 대하여 Temperature Sampling을 실시한다.
- 2에서 선택한 Parameter를 ANN 1 Hidden Layer으로 사용하고 Hidden Layer를 쌓고 Model의 성능을 Prediction한다.
- 2와 같이 성능에 대하여 Temperature Sampling을 실시한다.
- 실제 Surrogate Model에 대하여 성능을 확인하고 Prediction과 실제 Model의 성능을 비교한다.
- 3~5 과정을 L Layer를 쌓을 때 까지 반복하여 최종적으로 성능이 좋은 Architecture를 Select한다.
이러한 Search Algorithm은 Surrogate가 핵심이고, 해당 Paper에서는 LSTM을 사용하지만, Bayesian Network로서 구성하는 경우도 있다. 또한 위와 같은 결과를 위해서는 ANN Classifier의 Training또한 필요하나 Epoch = 3 ~ 5만큼 적게 하여도 Model의 Architecture를 Search하는데 무리가 없다. Temperature Sampling을 실시하는 이유는 Local Minumum을 avoid하기 위해서 이다.
Result: AV-MNIST
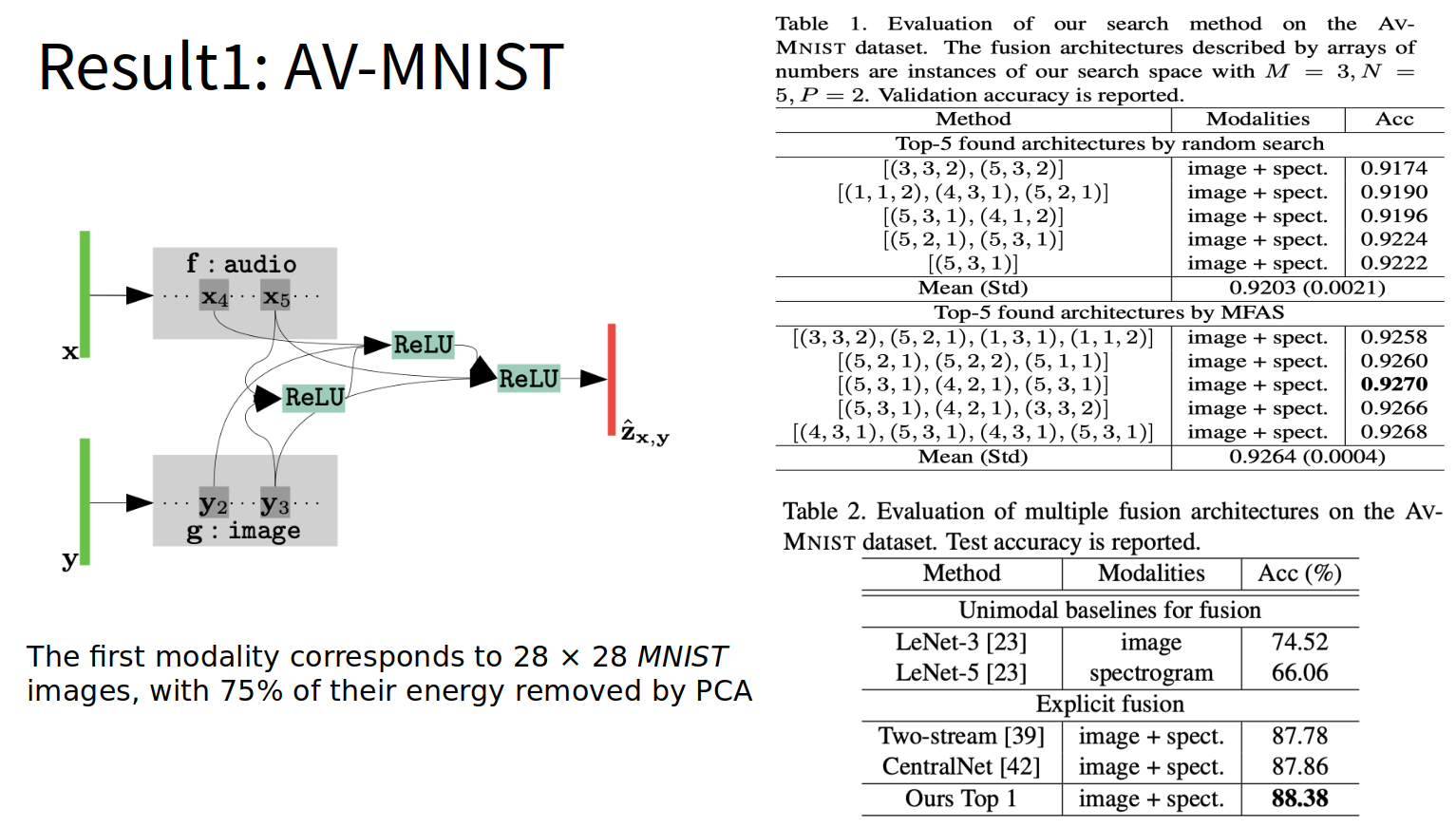
실제 AV-MNIST결과를 살펴보게 되면 위와 같은 Architecture에 대한 성능을 보여주고 있다. 위와 같이 Search Algorithm으로서 Architecture에 대한 후보를 설정하고 Epoch를 3 => 충분한 수로 올려서 결과를 확인하였을 경우 성능이 우수한 것을 살펴볼 수 있다.
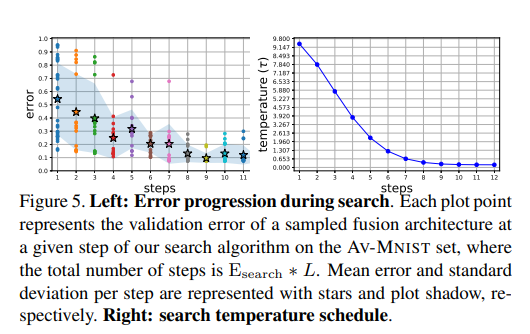
또한, Search Algorithm을 진행함에 따라서 Error도 줄고, Temperature Sampling의 후보도 줄어드는 것을 확인할 수 있다.
Appendix1. Surrogate
Surrogate를 LSTM으로서 간단히 구성하면 다음과 같다.
- Num Hidden: 100
- Number Input Feats: 5
- Size Embedding: 100
Number Input Feats를 5로서 정의한 이유는 해당 Model을 현재 Task에 적용할 때, Modality를 3개(pet, smri, snp)를 사용하고 ANN Classifier의 Activation Function을 선택 또한, ANN Classifier의 Output의 Hidden Layer의 갯수를 Surrogate로서 Search하기 위해서 이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
class SimpleRecurrentSurrogate(nn.Module):
# number_input_feats => Hidden layer of the CSF, PET, SMRI Auto Encoder ELM
def __init__(self, num_hidden=100, number_input_feats=5, size_ebedding=100):
super(SimpleRecurrentSurrogate, self).__init__()
self.num_hidden = num_hidden
# input embedding
self.embedding = nn.Sequential(nn.Linear(number_input_feats, size_ebedding),
nn.Sigmoid())
# the LSTM
self.lstm = nn.LSTM(size_ebedding, num_hidden)
# The linear layer that maps from hidden state space to output space
self.hid2val = nn.Linear(num_hidden, 1)
self.nonlinearity = nn.Sigmoid()
for m in self.modules():
if isinstance(m, nn.Linear):
m.weight.data.uniform_(-0.1, 0.1)
m.bias.data.fill_(1.8)
def forward(self, sequence_of_operations):
# (seq_len, batch, input_size):
embeds = []
for s in sequence_of_operations:
embeds.append(self.embedding(s))
embeds = torch.stack(embeds, dim=0)
lstm_out, hidden = self.lstm(embeds)
val_space = self.hid2val(lstm_out[-1])
val_space = self.nonlinearity(val_space)
return val_space
def eval_model(self, sequence_of_operations_np, device):
# the user will give this data sample as numpy array (int) with size len_seq x input_size
npseq = np.expand_dims(sequence_of_operations_np, 1)
sequence_of_operations = torch.from_numpy(npseq).float().to(device)
res = self.forward(sequence_of_operations)
res = res.cpu().data.numpy()
return res[0, 0]
Appendix2. ANN Classifier
- e_pet: Modality 1’s Feature Extractor(PreTraining)
- e_smri: Modality 2’s Feature Extractor(PreTraining)
- e_snp: Modality 3’s Feature Extractor(PreTraining)
- conf[3]: activation function => Sigmoid or ReLU or Tanh
- conf[4]: Num of Hidden ANN => (10, 20, 30, 40, 50, 100, 150, 200)
ANN Classifier는 alphas를 통하여 미리 ANN Classifier의 Input과 Output의 Size를 미리 지정하고, create_fc_layers를 통하여 Activation Function까지 포함하는 ANN Classifier를 만들게 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
# Input => Feature Extractor => Fusion Layer => Classification
class Searchable_ANN(nn.Module):
def __init__(self, args, conf, fe, device, cv):
super(Searchable_ANN, self).__init__()
# conf[0] => pet hidden layer
# conf[1] => smri hidden layer
# conf[2] => snp hidden layer
# conf[3] => activation function
# conf[4] => Num of Hidden ANN
self.conf = conf
self.args = args
self.device = device
# Pre-Train Feature Extractor
self.e_pet = fe[0]
self.e_smri = fe[1]
self.e_snp = fe[2][cv]
self.hid_num_list = [10, 20, 30, 40, 50, 100, 150, 200]
# Define Input Size
pet_input_size = []
for p in self.e_pet.parameters():
pet_input_size.append(p.shape[0])
smri_input_size = []
for p in self.e_smri.parameters():
smri_input_size.append(p.shape[0])
snp_input_size = []
for p in self.e_snp.parameters():
snp_input_size.append(p.shape[0]*3)
self.alphas = [(pet_input_size[conf[0]], smri_input_size[conf[1]], snp_input_size[conf[2]]) for conf in self.conf]
# Define Fuse Layer
self.fusion_layers = self._create_fc_layers()
# Classification => NL or MCI / NL or AD
self.central_classifier = nn.Sequential(nn.Linear(self.hid_num_list[self.conf[len(self.conf)-1][4]], 1), nn.Sigmoid())
# tensor_tuple => CSF, PET, SMRI
def forward(self, dataset):
pet, smri, snp = dataset[0], dataset[1], dataset[2]
pet = torch.tensor(pet, dtype=torch.float32).to(self.device)
smri = torch.tensor(smri, dtype=torch.float32).to(self.device)
snp = torch.tensor(snp, dtype=torch.float32).to(self.device)
# Pet Feature
pet_features = [self.e_pet.call_hidden_layer(pet, 0), self.e_pet.call_hidden_layer(pet, 1),
self.e_pet.call_hidden_layer(pet, 2)]
pet_features = [pet_features[idx] for idx in self.conf[:, 0]]
# SMRI Feature
smri_features = [self.e_smri.call_hidden_layer(smri, 0), self.e_smri.call_hidden_layer(smri, 1),
self.e_smri.call_hidden_layer(smri, 2)]
smri_features = [smri_features[idx] for idx in self.conf[:, 1]]
# SNP Feature
snp_features = [self.e_snp.call_hidden_layer(snp, 0), self.e_snp.call_hidden_layer(snp, 1),
self.e_snp.call_hidden_layer(snp, 2)]
snp_features = [snp_features[idx] for idx in self.conf[:, 2]]
# Fusion Feature
for fusion_idx, conf in enumerate(self.conf):
pet_feat = pet_features[fusion_idx]
smri_feat = smri_features[fusion_idx]
snp_feat = snp_features[fusion_idx]
if fusion_idx == 0:
fused = torch.cat((pet_feat, smri_feat, snp_feat), 1)
out = self.fusion_layers[fusion_idx](fused)
else:
fused = torch.cat((pet_feat, smri_feat, snp_feat, out), 1)
out = self.fusion_layers[fusion_idx](fused)
# Dropout with Classification
dropout_layer = nn.Dropout(p=0.3)
out = dropout_layer(out)
out = self.central_classifier(out)
return out
def central_params(self):
central_parameters = [
{'params': self.fusion_layers.parameters()},
{'params': self.central_classifier.parameters()}
]
return central_parameters
def _create_fc_layers(self):
fusion_layers = []
for i, conf in enumerate(self.conf):
in_size = sum(self.alphas[i])
# args.inner_representation_size => ANN Output Size
if i > 0:
in_size += self.hid_num_list[self.conf[i-1][4]]
out_size = self.hid_num_list[conf[4]]
# Activation Function
if conf[3] == 0:
nl = nn.Sigmoid()
elif conf[3] == 1:
nl = nn.ReLU()
elif conf[3] == 2:
nl = nn.Tanh()
op = nn.Sequential(nn.Linear(in_size, out_size), nl)
fusion_layers.append(op)
return nn.ModuleList(fusion_layers)
참조: 원본코드(juanmanpr Github)
참조: MFAS: Multimodal Fusion Architecture Search
참조: Efficient Progressive Neural Architecture
Search
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment