
Paper22. Deep Single-Image Portrait Relighting
Deep Single-Image Portrait Relighting
출처: Deep Single-Image Portrait Relighting
코드: shhoper GitHub
Supplementary: Supplementary Material
Dataset: DPR Dataset
Appendix. 용어 정리
비전쪽은 많이 다루지 않아서 생소한 단어가 많았기 때문에 개인적으로 논문에서 많이 사용하나, 잘 모르겠는 용어를 정리하였습니다. 저처럼 Vision쪽 중 특히, Rendering쪽을 전문으로 하지 않으신 분들은 먼저 용어를 정리하고 읽으시면 도움이 많이 될 것 같습니다.
- Portrait Image: portrait image는 초상화 Image라는 의미로서 현재 논문에서는 사람 얼굴과 목을 포함한 Image에 대하여 중점적으로 다루고 있다.
- Face geometry: Face geometry는 face의 surface를 3D로서 잘 reconstructiong하는 것 이다. 예시는 아래 그림과 같다.

출처: A Statistical Model for Synthesis of Detailed Facial Geometry - Spherical harmonic (SH) lighting: 해당용어는 real-time rendering분야에서 많이 사용되는 용어로서 아래 그림과 같이 해당 Image의 전반적인 Lighting을 구모양으로서 표현하는 방식이다.

출처: Deep Single-Image Portrait Relighting Paper - Normal Image and Shading Image and Relit Image:
- Normal Image는 Rendering분야에서는 Input의 Image에서 색을 제외하고, 얼굴의 Face Geometry 으로서 Face의 Surface를 나타내는 Image를 의미한다.
- Shading은 이러한 Normal Image에 색을 어떻게 입힐 것인지에 대한 정보이다. 즉, Shading과정에서 Lighting의 영향을 많이 받는 것을 알 수 있다. 예시는 아래 그림과 같다.
- Relit Image은 Normal Image와 Shading을 활용하여 다시 Reconstruction된 Image를 의미한다.
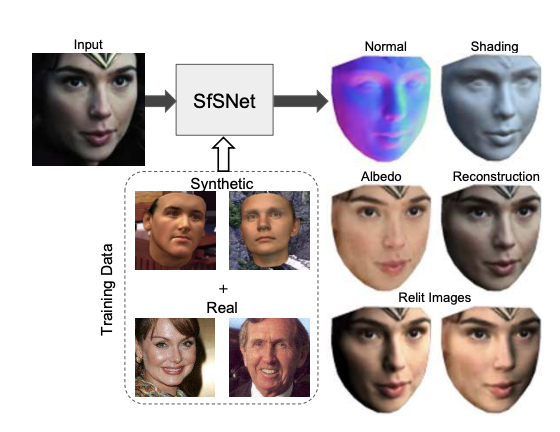
출처: SfSNet: Learning Shape, Reflectance and Illuminance of Faces ‘in the wild’ Paper
- Hourglass Model: Hourglass Model이라는 것은 Reconstruction을 하는 Model에서 residual unit을 사용하는 Model입니다. 해당 과정을 거치게 되면, Hidden Layer를 거치기 전의 Information을 활용할 수 있으므로, Unet과 같은 많은 정보를 사용할 수 있는 장점이 존재하게 됩니다. 예시는 아래 그림과 같습니다.
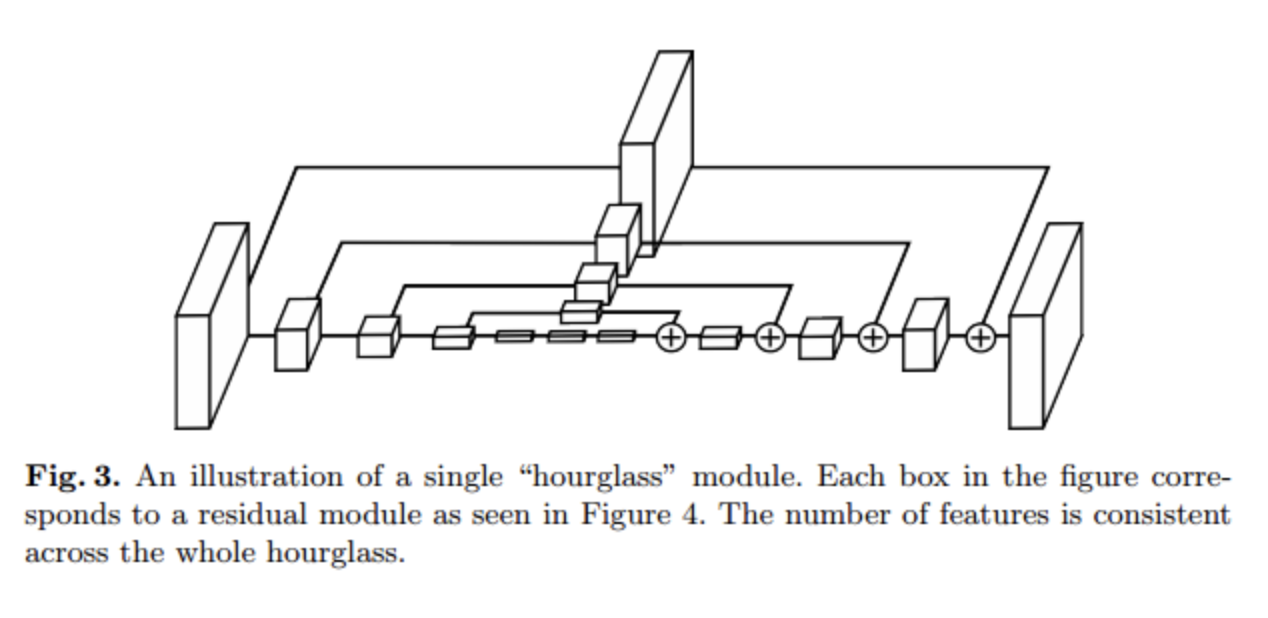
출처: deep-learning-study Blog
Abstract
Conventional physically-based methods for relighting portrait images need to solve an inverse rendering problem, estimating face geometry, reflectance and lighting. However, the inaccurate estimation of face components can cause strong artifacts in relighting, leading to unsatisfactory results. In this work, we apply a physically-based portrait relighting method to generate a large scale, high quality, “in the wild” portrait relighting dataset (DPR). A deep Convolutional Neural Network (CNN) is then trained using this dataset to generate a relit portrait image by using a source image and a target lighting as input. The training procedure regularizes the generated results, removing the artifacts caused by physically-based relighting methods. A GAN loss is further applied to improve the quality of the relit portrait image. Our trained network can relight portrait images with resolutions as high as 1024 × 1024. We evaluate the proposed method on the proposed DPR datset, Flickr portrait dataset and Multi-PIE dataset both qualitatively and quantitatively. Our experiments demonstrate that the proposed method achieves state-of-the-art results. Please refer to https://zhhoper.github.io/dpr.html for dataset and code.
해당 논문을 선택한 이유는 Introduction에 잘 나와있다. 현재 Face를 Change하는 DeepFake기반의 Model을 사용할 때, Target과 Source의 Light의 영향을 많이 받는 것을 알 수 있다. 이러한 Light의 효과를 고려하여 변환하기 위한 방법 중 하나로서 해당 논문을 선택하고 읽어보았다.
현재 논문에서 Focus를 맞추고 있는 것은, Source Image를 Target Image로서 변환하는 과정에서 Relighting에 대한 방법에 대해 초점을 맞춘 논문이다. 또한 중요한 점은 이러한 Relighting문제를 해결함과 동시에 1024x1024 Image에 적용할 수 있는 Hight-quality를 보장할 수 있다는 것 이다.
Introduction
The goal of this work is to design an automatic singleimage portrait relighting algorithm, which takes a portrait image and a target lighting as input and generates a new portrait image under the target lighting condition.
해당 논문의 Contribution은 Single portrait image에 대해서 source image와 target image간의 사이에서 relight를 잘 할 수 있는 Algorithm을 제안하는 것 이다.
이전 논문들의 문제로 삼은 것은 inaccuracte estimation of face geometry와 face reconstruction에서 문제가 발생한다는 것 이다. 이러한 문제점은 결국에 relighting을 잘 수행하지 못하여 발생하는 문제 이고, 결과적으로는 reconstruction의 결과또한 잘 안나오게 된다는 것 이다.
해당 논문은 이러한 문제를 해결하기 위하여 base가 되는 architecture를 source image로부터 새로운 target image를 생성할 수 있는 GAN (Generative Adversial Networks)로서 잡게 되었고, 이를 훈련하기 위하여 많은 양의 DPR (Deep Portrait Relighting Dataset)을 활용하였다.
해당 모델을 구현하기 위하여 논문저자들이 가장 중요하게 생각하는 것은 Source Image와 Target Image에서 Light라는 요소를 어떻게 추출할 것 인가 이다. 해당 문제를 해결하게 되면, Soucr -> Target으로 변화할 때 Light의 요소를 Target에 맞게 바꾸면 되는 간단한 문제로서 해결되기 때문이다. 해당 문제를 해결하기 위하여 해당 논문 저자들은 다음과 같은 2개의 논문을 활용하여 새로운 방법을 제시하였다고 한다. (2개의 논문은 rendering분야에서 유명한 2문제 인것 같으나 전공하고 있는 분야가 아니여서 읽지 못하였습니다.)
- Portrait Image에 적용하기 위하여 사람의 얼굴에서 Face를 선택하여 어떻게 3D로서 나타낼 것 인가? 이다. 이러한 문제점을 해결하기 위한 논문으로서 Face Alignment in Full Pose Range: A 3D Total Solution 이 언급되었다.
- 1의 결과에서 얻은 Image에서 Light의 요소를 어떻게 뽑을지에 대한 문제이다. 이러한 문제를 해결하기 위한 논문으로서 SfSNet: Learning Shape, Reflectance and Illuminance of Faces ‘in the wild’이 언급되었다.
이러한 2가지 논문을 활용하여 Image에서 Normal과 Shading으로서 분리하는 것을 알 수 있다. 즉, 내가 이해한 이 논문의 PipeLine의 과정은 다음과 같다.
- Input Image를 Normal Image와 Lighting (SH Lighting)요소를 추출한다.
- Target Image로서 변환하기 위하여 Normal Image와 Target Lighting을 Input으로서 사용한다. 이러한 과정에서 Target Lighting을 활용하여 Shading을 실시하게 되므로, 자연스러운 변화를 야기한 Target(relitimage) 수 있다.
해당 과정의 결과는 아래 그림과 같다.

출처: Deep Single-Image Portrait Relighting Paper
Model을 Concept과 Training과정에서 중요하게 살펴봐야 하는 것은 2가지로서 요약할 수 있다. Hourglass Model
We observe that the skip connections in the hourglass network prevent the bottleneck layer from learning meaningful facial information. Therefore, we propose a simple skip training strategy to enforce facial information in the bottleneck layer, which improves the quality of the generated images.
해당 논문에서는 Hourglass Model의 Architecture를 사용하였다. 사용한 이유는 위에서 언급한 것과 같이, Hourglass Model로서 Skip connection구조를 사용하게 되면 meaningful facial information을 훈련할 수 있기 떄문이다.
Low quality image training -> High quality image training
Our network is first trained on 512 × 512 images and then fine tuned on 1024 × 1024 images. To the best of our knowledge, our proposed method can generate relit images at the highest resolution among all deep learning-based algorithms.
해당 논문에서는 512x512로서 상대적으로 저화질의 Image를 먼저 학습하고, 1024x1024의 Image로서 Fine Tuning한 것을 알 수 있다. 이러한 훈련 방식은 저화질의 Image로서 Image의 대략적인 정보를 잘 뽑아내는 상태에서, 고화질의 Image를 Fine Tuning하여 세부적인 feature를 뽑을수 있게 되어, High quality로서 Model훈련이 가능하다는 것 이다. (이러한 Training방법은 많이 사용되는데, 주로 같은 Image를 2개의 Quality로서 학습하는 조건이 붙게 되는데, 현재 논문에서의 Dataset은 자세히 봐야지 알 수 있을 것 같다.)
Deep Portrait Relighting Dataset
- Dataset Link: Google Drive
- Data Preparation Code: zhhoper GitHub
개인적으로 생각하는 해당 논문에서 큰 Contribution중 하나인, High resolution하면서 데이터의 수가 많은 DPR (Deep Protrait Relighting) Dataset을 어떻게 만들었는지에 대한 부분이다. 해당 Dataset을 만드는 과정은 다음과 같다.
- 30,000의 1024x1024 face image를 CeleA dataset(CelebA-HQ)로부터 획득한다.
- Portrait Relighting에 적용하기 위하여, Face의 Lendmark를 착고 실패한 Image를 제외하고 총 27,627의 Image를 사용한다.
- 각각의 Image에 5개의 Light condition을 적용하여 결과적으로 27,627x5 = 138,135개의 Image를 DPR Image로서 사용하게 된다.
Ratio Image-based Face Relighting
전문 분야가 아니여서, 이해한 그대로를 적었습니다….
먼저 실제 Image를 다음과 같이 나타낸다고 가정해보자.
$$I = R\odot f(N, L)$$
- \(I\): Real Image
- \(R\): Reflectance (반사율)
- \(N\): Normal Image
- \(L\): Lighting
- \(f(\cdot)\): Lambertian shading function: 반사율 중 하나의 종류로서, 관찰자가 바라보는 각도와 관계없이 같은 겉보기 밝기를 갖는다.
- \(\odot\): element-wise product
위의 식을 살펴보게 되면, 실제 얻을 수 있는 아무런 특징이 없는 Normal Image에 Light와 반사율을 고려하게 되면, 실제 우리가 보게되는 Image로서 표현된다는 것 이다. 해당 논문에서는 다른 Lighting(\(L^*\))의 상황에서의 Image(\(I^*\))은 다음과 같이 나타내었다.
$$I^* = R\odot f(N, L^*)$$
$$= \frac{R\odot f(N, L^*)}{R\odot f(N, L)}(R\odot f(N, L))$$
$$= \frac{f(N, L^*)}{f(N, L)}I$$
위의 식으로서 알수 있는 사실은, 실제 Image에서 Lighting이 다른 상황의 Image(Target Image)를 구하기 위해서는 다음과 같은 Input이 필요하다.
- Source Image(\(I\))
- Source Lighting(\(L\))
- Target Lighting(\(L^*\))
- Source Normal Image(\(N\))
ARAP-Based Normal Refinement
위에서 알수 있듯이 제일 중요한 것은 Source Normal Image(N)을 구할 수 있어야 된다는 것 이다. 기존의 많이 사용하는 3DMM은 variations of face geometry에 대한 한계점이 존재하기 때문에, 해당 논문에서는 3DMM기반으로서 ARAP-Based Normal Refinement방법으로서 Normal Estimation을 수행하게 되었다. ARAP-Based Normal Refinement의 과정은 아래 그림과 같다.
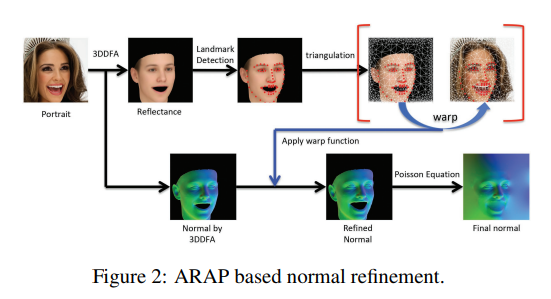
- 3DDFA를 통하여 Reflectance와 Normal을 추출한다.
- Reflectance Image에서 68개의 facial landmarks를 찾는다.
- Image경계를 따라 고르게 198개의 Anchor Point로서 찾는다
- Delauny Triangulation을 사용하여 Reflection Image에 triangle mesh를 만든다.
- 2~4의 과정을 Original Image에도 적용하고 4의 결과와 Wrapping하여 보정을 실시한다.
- Normal Imager과 5의 결과물을 Wrapping하게 된다.
- 마지막으로 Possition Equation을 통하여 Final Normal Image를 얻는다.
위의 과정으로 Normal Image를 얻었을때의 결과는 아래 그림과 같다.
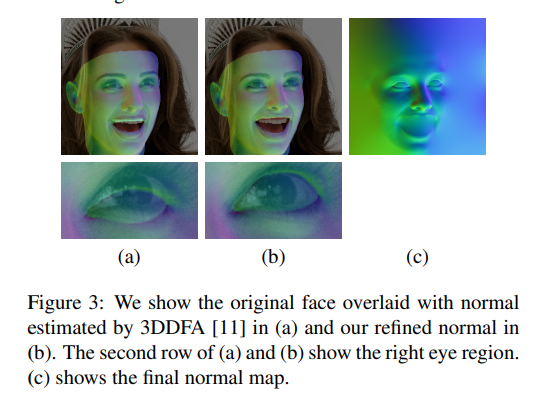
실제 결과를 살펴보게 되면, 얻고자 하는 Normal Image에 Original Image을 사용하여 보정하였기 때문에, 3DFFA의 Normal Image보다 정교하게 Mapping된 것을 알 수 있다.
Relighting Images
현재 가지고 있는 Original Image(\(I\))에서 ARAP-Based Normal Refinement를 통하여 Normal Image(\(N\))을 얻었으므로 우리는 Source Light(\(L\))과 Target Light(\(L^*\))만 있으면, Light Condition에 따라서 Image를 변화할 수 있다는 것을 알 수 있다.
위의 과정은 SfSNet: Learning Shape, Reflectance and Illuminance of Faces ‘in the wild’을 통하여 얻어내었다. 해당 PipeLine의 결과는 아래와 같다.

Method
Input Image가 Light Condition에 따라서 새로운 Image를 만드는 식은 아래와 같다.
$$I^* = \frac{f(N, L^*)}{f(N, L)}I$$
위의 식에서 우리는 ARAP-Based Normal Refinement을 통하여 \(N\)을 얻을 수 있었고, SfSet을 통하여 \(L^*, L\)을 얻을 수 있으므로, Target Image(\(I^*\))를 얻을 수 있다.
해당 논문에서는 Deep Learning Based Model로서 N과 f를 아래 그림과 같은 Architecture로서 구성하게 되었다.
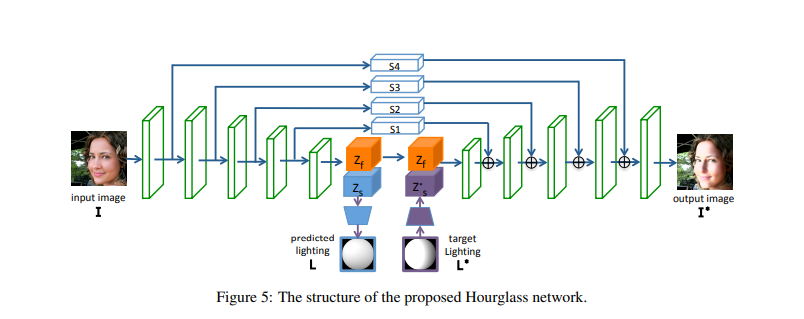
위의 Network Architecture를 살펴보게 되면, ARAP-Based Networ Architecture인 것을 알 수 있다.
해당 Model을 학습하기 위해서는 크게 3가지의 Loss가 사용된다.
$$L = L_I + L_{\text{GAN}} + \lambda L_F$$
Supervision for Training the Network Loss
1) \(L_I\)
$$L_I = \frac{1}{N_I}(\|I_t - I_t^*\|_1 + \|\nabla I_t - \nabla I_t^*\|_1)+(L_s - L_s^*)^2$$
- \(N_I\): Number of pixels in the image.
- \(I_t\): Target Image
- \(I_t^*\): Generate Target Image
- \(L_s\): Source Light
- \(L_s^*\): Generate Source Light
위의 Loss를 살펴보게 되면 크게 3부분으로서 나눌 수 있다.
- \(\|I_t - I_t^*\|_1\): 실제 Target Image와 생성되는 Target Image간의 차이가 없도록 학습한다.
- \(\|\nabla I_t - \nabla I_t^*\|_1\): Gradient를 고려하게 되므로 Edge를 보존하고 bluring되는 효과를 방지할 수 있다.
- \((L_s - L_s^*)^2\): 생성해야하는 Source Lighting을 잘 생성할 수 있도록 학습한다.
2) \(L_{\text{GAN}}\)
$$L_{\text{GAN}} = \mathbb{E}_I(1-D(I))^2 + \mathbb{E}_{I_s}D(G(I_s, L_t))^2$$
일반적으로 많이 사용하는 GAN Loss입니다. 해당논문에서는 ground truth images또한 Image Trick을 사용하여 생성되는 것 이므로, 부정확한 추정이 이루워졌다고 생각하기 때문에 다음과 같은 Loss를 추가하였다고 했다.
3) \(L_F\)
$$L_F = \frac{1}{N_F}(Z_{f1}-Z_{f2})^2$$
위에서 Image하나에 5가지의 Lighting Condition을 만들어서 Dataset을 만들었다. 따라서 해당 Network에서 추정하는 \(Z_f\)는 Lighting을 제외한 Image이므로, 어떤 Lighting Condition이여도 같은 Image가 나와야 한다. 따라서, 해당 논문에서는 위와 같은 Loss를 추가하였다.
Skip Training
Skip Training에 따른 결과에 대한 그림은 아래와 같다.

오른쪽에서 왼쪽으로 갈수록, Skip Connection을 하나씩 추가하는 형태가 된다. 해당 결과를 살펴보게 되면, Skip Connection을 사용하지 않은 경우에는 매우 Bluring되어서 나오는 것을 알 수 있지만, Skip Connection의 개수를 늘릴수록 Edge가 정확해지고, facial의 information이 많게 선명하게 나오는 것을 알 수 있다.
또한, Skip Connection이 있고 없고에 대한 추가적인 효과는 아래와 같다.
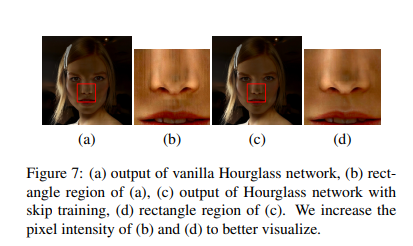
위의 그림을 살펴보게 되면, skip connection을 사용하게 되면, 결과물에 차이가 없어보일 수 있지만, 자세하게 살펴보면 좀 더 자연스럽게 Output을 얻을 수 있는것을 살펴볼 수 있다.
Implementation Details
Model을 Training하는 과정에서 \(L = L_I + L_{\text{GAN}} + \lambda L_F\)을 Epoch에 따라서 어떻게 훈련했는지 자세한 내용이다.
- Model은 총 14epoch로서 학습하고 Optimizer는 Adam을 사용하였다.
- 처음에는 skip connections이 없도록 학습하고 5 epoch이후에 1개의 skip connection을 늘리면서 학습하게 된다.
- 10 epoch전까지는 \(L = L_I + L_{\text{GAN}}\)로서 학습하고, 10번 이후에는 \(\lambda=0.5\)로서 고정하고 학습한다.
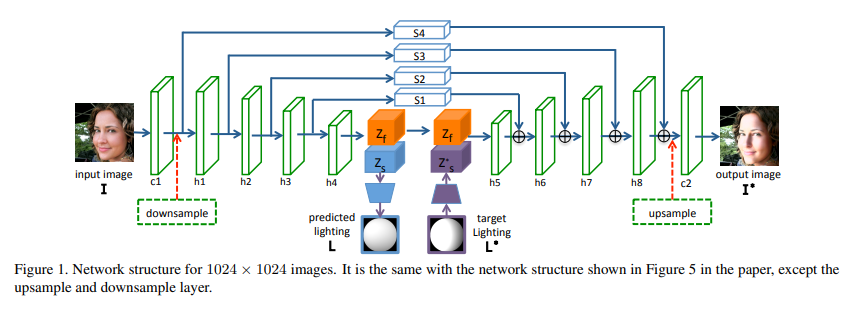
- 먼저 512x512로서 학습하게 되고, 1024x1024로서 FineTuning하는 과정에서는 Upsampling과 Downsampling을 아래와 같이 추가하여 학습하게 된다.
Experiments
해당 논문에서는 크게 2가지로서 Experiments를 나누어서 실험하였다.
- Lighting을 알 수 있는 상황에서 Target Image(\(I_t\))를 얼마나 잘 예측하는가?
- Lighting을 Prediction할 수 있는 Model이므로 Source Image(\(I_s\))만 주어졌을 경우, Target Image(\(I_t\))를 얼마나 잘 예측하는가?
Dataset and Evaluation Metric
DPR Dataset의 개수가 적기 때문에, Multi-PIE Dataset으로서 Experiments를 실험하였다. 해당 Dataset은 Light Condition에 따른 Dataset은 아니므로 7가지 상황에 대하여 Dataset을 구성하였다.
Model Evaluation으로서는 2가지 Metric을 사용하였다.
- \(\text{Si-MSE} = \frac{1}{N_I} \min_{\alpha} (I_t - \alpha * I_t^*)^2\)
- \(\text{Si-L}_2\): SfSNet의 output을 L2로서 비교하였다.
위와 같은 Metric을 사용한 이유는 다음과 같이 이야기 하고 있으나 잘 모르겠습니다.
Since lighting is ambiguous up to a scale (e.g., longer exposure time may lead to a SH with high energy under the same lighting conditions), we proposed to use a scale invariant Mean Squared Error (Si-MSE) [4] to evaluate the error between the generated image I∗t and the ground truth image It. where α is a scalar and NI is the number of pixels in the image. To further check whether the generated image portrays the target lighting, we run SfSNet [22] to extract the lighting Lt and L∗t from It and I∗t respectively, and compute the scale invariant L2 (Si-L2) distance between Lt and L∗t. We choose to use SfSNet [22] since it is proven to work well at predicting consistent lighting for face images under the same lighting condition.
Ablation Study
각각의 Loss를 확인하여 위하여 각 Loss를 하나씩 추가하면서, 결과를 확인하였다.
해당 결과는 아래와 같다.

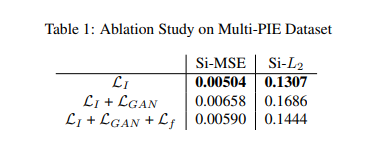
먼저 Table 1을 살펴보게 되면, \(L_I\)만 사용하였을 경우에 Loss가 제일 낮은 것을 알 수 있다. 하지만, Figure를 살펴보게 되면 nose부분에서 \(L_{\text{GAN}}\)을 추가하여야지 자연스럽게 결과가 나오는 것을 알 수 있다. 결과적으로 GAN Loss를 사용하게 되면, ‘실제’ Image에 더 가까워 지는데 방해가 될 수 있으나, Visualization에서는 더욱더 자연스럽게 Output을 뽑아내는 것을 알 수 있다. 또한, \(L_f\)를 추가하게 되면, Visualization이 자연스러운 상황에서 Si-MSE와 Si-L2의 Loss를 줄일 수 있는 것을 알 수 있다.
즉, 해당 Loss를 3개를 모두 사용하여서 학습하게 되면, good balance between accuracy and quality of the generated images를 유지할 수 있다는 결과이다. (Image생성과 얼만큼 잘 생성했는지에 대한 Model에서는 절대적인 Accuracy가 중요한 것이 아니라, 정략적으로는 표현하지 못하는 Visualization상에서 자연스러운 것도 중요한 것을 알 수 있다.)
Comparison with State-of-the-art Methods

해당 결과를 살펴보게 되면, Fornal face images뿐만 아니라, non-frontal face images또한 Lighting Condition에 따라 사진을 잘 Generation하는 것을 살펴볼 수 있다. 또한, 각각의 SOTA method에 따른 단점에 대하여 적어두었는데 직접 논문에서 살펴보는 것이 좋을 것 같습니다.
Conclusion
해당 논문은 Project를 진행하기 위하여 처음 보는 분야의 논문이였다. 아직 많이 부족하지만, 새로운 것을 많이 알 수 있는 논문이였다.
- 많이 사용하는 FineTuning을 저화질고 고화질로서 나누어 학습하게 되어, 자연스러운 결과를 얻을 수 있다.
- Epoch마다, Training Stragery를 세워서 다르게 학습하여, 효과적인 결과를 얻었다.
- 많이 사용하는 Skip Connection을 사용하였지만, 2와 결합하여 좀 더 학습이 잘 되는 결과를 얻을 수 있었다.
- Dataset이 부족하여도, 다른 논문들을 활용하여 Dataset을 만들게 되었고, 그 방법들과 비교하였다.
- ARAP-Based Deep Learning기법으로서, 기존의 방법에서 Deep Learning방법으로 바꾸는 자세한 내용을 설명한 논문이였다.
Leave a comment