
Pytorch-RNN&LSTM
RNN
RNN 은 딥러닝에서 사용하는 Recurrent Neural Network으로서 시계열 데이터를 다룰때 사용하는 신경망 이다.
대표적인 예와 그에 해당하는 이론에 대한 내용은 아래 링크를 참조하자.
필요한 라이브러리 import
1
2
3
4
5
6
# 단순한 문자 RNN을 만들어보겠습니다.
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
HyperParameter 설정
- n_hidden: 신경망 Node수
- lr: Learning Rate
- epochs: 반복 횟수
1
2
3
4
5
# 하이퍼파라미터 설정
n_hidden = 35
lr = 0.01
epochs = 1000
Input Data생성 및 Vocab 설정
- InputData: string
- Vocab: chars
1
2
3
4
5
6
7
8
9
# 사용하는 문자는 영어 소문자 및 몇가지 특수문자로 제한했습니다.
# alphabet(0-25), space(26), ... , start(0), end(1)
string = "hello pytorch. how long can a rnn cell remember? show me your limit!"
chars = "abcdefghijklmnopqrstuvwxyz ?!.,:;01"
# 문자들을 리스트로 바꾸고 이의 길이(=문자의 개수)를 저장해놓습니다.
char_list = [i for i in chars]
n_letters = len(char_list)
Encoder
문자를 그대로 쓰지않고 one-hot 벡터로 바꿔서 연산에 사용
Start = [0 0 0 … 1 0]
a = [1 0 0 … 0 0]
b = [0 1 0 … 0 0]
c = [0 0 1 … 0 0]
…
end = [0 0 0 … 0 1]
최종적인 Output은 start + 문장 + end로서 구성된다.
One-hot Vector는 Encoder에서 Input String을 변환해서 RNN Model의 Input으로 들어갈 수 있게 One-hot Vecotr로 변환하는 역할을 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 문자열을 one-hot 벡터의 스택으로 만드는 함수
# abc -> [[1 0 0 … 0 0],
# [0 1 0 … 0 0],
# [0 0 1 … 0 0]]
def string_to_onehot(string):
# 먼저 시작 토큰과 끝 토큰을 만들어줍니다.
start = np.zeros(shape=n_letters ,dtype=int)
end = np.zeros(shape=n_letters ,dtype=int)
start[-2] = 1
end[-1] = 1
# 여기서부터는 문자열의 문자들을 차례대로 받아서 진행합니다.
for i in string:
# 먼저 문자가 몇번째 문자인지 찾습니다.
# a:0, b:1, c:2,...
idx = char_list.index(i)
# 0으로만 구성된 배열을 만들어줍니다.
# [0 0 0 … 0 0]
zero = np.zeros(shape=n_letters ,dtype=int)
# 해당 문자 인데스만 1로 바꿔줍니다.
# b: [0 1 0 … 0 0]
zero[idx]=1
# start와 새로 생긴 zero를 붙이고 이를 start에 할당합니다.
# 이게 반복되면 start에는 문자를 one-hot 벡터로 바꾼 배열들이 점점 쌓여가게 됩니다.
start = np.vstack([start,zero])
# 문자열이 다 끝나면 쌓아온 start와 end를 붙여줍니다.
output = np.vstack([start,end])
return output
Decoder
onehot_to_word는 Decoder에서 RNN Model의 output을 Output String 으로 바꿔주는 역할을 한다.
이러한 변환을 통하여 Model의 Output과 실제 Target과의 차이를 구할 수 있다.
1
2
3
4
5
6
7
8
9
# One-hot 벡터를 문자로 바꿔주는 함수
# [1 0 0 ... 0 0] -> a
# https://pytorch.org/docs/stable/tensors.html?highlight=numpy#torch.Tensor.numpy
def onehot_to_word(onehot_1):
# 텐서를 입력으로 받아 넘파이 배열로 바꿔줍니다.
onehot = torch.Tensor.numpy(onehot_1)
# one-hot 벡터의 최대값(=1) 위치 인덱스로 문자를 찾습니다.
return char_list[onehot.argmax()]
RNN Model
실직적인 RNN Model을 구성하는 Code이다.
기존 Neural Network와 달리 RNN에서 중요한 점을 살펴보면 다음과 같다.
combined = torch.cat((input, hidden), 1): Input으로 들어가는 것은 기존의 Input 뿐만이 아니라 이전 Hidden Layer의 결과또한 들어가게 된다.return output, hidden: Input으로서 HiddenLayer의 값또한 들어가게 되므로 Return값이 output과 HiddenLayer의 output 2가지 이다.init_hidden(self): 처음 HiddenLayer의 output값이 없으므로 초기화를 시켜주는 작업이 필요하다.- ActivationFunction: ReLu
참고사항: troch.cat Parameter
torch.cat(tensors, dim=0, out=None)
- tensors: Input Tensor
- dim: Tensor의 차원을 합친뒤 Output으로 내보낼 Tensor의 차원
- out: return 값은 Tensor로서 특정 Tensor에 대입하고할 때 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# RNN with 1 hidden layer
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.act_fn = nn.Tanh()
def forward(self, input, hidden):
# 입력과 hidden state를 cat함수로 붙여줍니다.
combined = torch.cat((input, hidden), 1)
# 붙인 값을 i2h 및 i2o에 통과시켜 hidden state는 업데이트, 결과값은 계산해줍니다.
hidden = self.act_fn(self.i2h(combined))
output = self.i2o(combined)
return output, hidden
# 아직 입력이 없을때(t=0)의 hidden state를 초기화해줍니다.
def init_hidden(self):
return torch.zeros(1, self.hidden_size)
rnn = RNN(n_letters, n_hidden, n_letters)
Loss Function & Optimizer Define
- LossFunction: MSE
- Optimizer: Adam
1
2
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(rnn.parameters(), lr=lr)
Train
앞에서 선언한 Model을 Train하는 과정이다. Char_RNN을 목표로하고 있으므로 Target Data는 Input Data에서 Index가 하나씩 추가되어진 형태이다.
RNN의 Input으로 들어가기 위하여 문자열을 One-Hot-Vector로서 변환하는 과정이 필요하고 Model에 들어가기 위해서는 Tensor형태이여야 하므로 type을 torch.FloadTensor()로서 정의한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# train
# 문자열을 onehot 벡터로 만들고 이를 토치 텐서로 바꿔줍니다.
# 또한 데이터타입도 학습에 맞게 바꿔줍니다.
one_hot = torch.from_numpy(string_to_onehot(string)).type_as(torch.FloatTensor())
for i in range(epochs):
optimizer.zero_grad()
# 학습에 앞서 hidden state를 초기화해줍니다.
hidden = rnn.init_hidden()
# 문자열 전체에 대한 손실을 구하기 위해 total_loss라는 변수를 만들어줍니다.
total_loss = 0
for j in range(one_hot.size()[0]-1):
# 입력은 앞에 글자
# pyotrch 에서 p y t o r c
input_ = one_hot[j:j+1,:]
# 목표값은 뒤에 글자
# pytorch 에서 y t o r c h
target = one_hot[j+1]
output, hidden = rnn.forward(input_, hidden)
loss = loss_func(output.view(-1),target.view(-1))
total_loss += loss
total_loss.backward()
optimizer.step()
if i % 10 == 0:
print(total_loss)
tensor(2.4497, grad_fn=<AddBackward0>)
tensor(1.0887, grad_fn=<AddBackward0>)
tensor(0.6670, grad_fn=<AddBackward0>)
...
tensor(0.0032, grad_fn=<AddBackward0>)
tensor(0.0021, grad_fn=<AddBackward0>)
tensor(0.0016, grad_fn=<AddBackward0>)
Test
Train된 Model을 확인한다. start는 맨처음 선언한 One-hot-Vecotr의 첫번째로서 선언하게 된다. Output을 확인하기 위하여 One-hot-Vecotr => String으로 바꾸어서 확인한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# test
# hidden state 는 처음 한번만 초기화해줍니다.
start = torch.zeros(1,n_letters)
start[:,-2] = 1
with torch.no_grad():
hidden = rnn.init_hidden()
# 처음 입력으로 start token을 전달해줍니다.
input_ = start
# output string에 문자들을 계속 붙여줍니다.
output_string = ""
# 원래는 end token이 나올때 까지 반복하는게 맞으나 끝나지 않아서 string의 길이로 정했습니다.
for i in range(len(string)):
output, hidden = rnn.forward(input_, hidden)
# 결과값을 문자로 바꿔서 output_string에 붙여줍니다.
output_string += onehot_to_word(output.data)
# 또한 이번의 결과값이 다음의 입력값이 됩니다.
input_ = output
print(output_string)
hello pytorch. h yrlrememno crnmeonmelrn ng cn noe ieiemyoe ynmlonon
Batch 처리(RNN, LSTM)
RNN과 LSTM의 성능차이를 확인하기 위하여 Batch처리를 하여 Character Recurrent Neural Network를 2가지의 Model로서 구성하고 확인해본다.
최종적인 Model은 세익스피어 문체를 모방하는 Model을 작성하는 것이 목표이다.
Dataset
2가지의 Model에서 사용하기 위한 DataSet을 구축하는 단계이다.
Data Download
1
2
3
4
5
6
7
8
9
!rm -r data
import os
try:
os.mkdir("./data")
except:
pass
!wget https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/tinyshakespeare/input.txt -P ./data
--2019-09-23 08:46:35-- https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/tinyshakespeare/input.txt
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.228.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.228.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1115394 (1.1M) [text/plain]
Saving to: ‘./data/input.txt’
input.txt 100%[===================>] 1.06M 4.34MB/s in 0.2s
2019-09-23 08:46:35 (4.34 MB/s) - ‘./data/input.txt’ saved [1115394/1115394]
1
!pip3 install unidecode
Collecting unidecode
Using cached https://files.pythonhosted.org/packages/d0/42/d9edfed04228bacea2d824904cae367ee9efd05e6cce7ceaaedd0b0ad964/Unidecode-1.1.1-py2.py3-none-any.whl
Installing collected packages: unidecode
Successfully installed unidecode-1.1.1
1. Settings
1) 필요한 라이브러리들을 불러온다
1
2
3
4
5
6
7
import torch
import torch.nn as nn
import unidecode
import string
import random
import re
import time, math
2) HyperParameter설정
1
2
3
4
5
6
7
8
9
10
11
12
num_epochs = 2000
print_every = 100
plot_every = 10
# chunk에 대한 설명은 아래 함수정의하면서 하겠습니다.
chunk_len = 200
hidden_size = 100
batch_size = 1
num_layers = 1
embedding_size = 70
lr = 0.002
2. Data preprocessing
1) Prepare characters
출력 가능한 모든 문자의 길이를 알아내는 작업이다.
이것이 One-hot-vector로 단어를 변환할때의 Dimension의 크기가 된다.(Vocab size를 알아내는 것과 같다.)
1
2
3
4
5
6
7
# import 했던 string에서 출력가능한 문자들을 다 불러옵니다.
all_characters = string.printable
# 출력가능한 문자들의 개수를 저장해놓습니다.
n_characters = len(all_characters)
print(all_characters)
print('num_chars = ', n_characters)
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
num_chars = 100
2) Get text Data
Data로서 사용할 File의 Character의 개수를 알아온다.
1
2
3
4
5
# 앞서 다운받은 텍스트 파일을 열어줍니다.
file = unidecode.unidecode(open('./data/input.txt').read())
file_len = len(file)
print('file_len =', file_len)
file_len = 1115394
3) Random chunk
Train과 Test로서 사용할 Data를 일정한 Character의 개수로서 자르는 작업을 한다.
rnadon.randint(start,end)
start ~ end-1 사이의 Random한 숫자 출력
즉 Data의 Size를 고려하여서 end = file_len - chunk_len으로서 선언
1
2
3
4
5
6
7
def random_chunk():
# (시작지점 < 텍스트파일 전체길이 - 불러오는 텍스트의 길이)가 되도록 시작점과 끝점을 정합니다.
start_index = random.randint(0, file_len - chunk_len)
end_index = start_index + chunk_len + 1
return file[start_index:end_index]
print(random_chunk())
sir, ere long I'll visit you again.
CLAUDIO:
Most holy sir, I thank you.
ISABELLA:
My business is a word or two with Claudio.
Provost:
And very welcome. Look, signior, here's your sister.
DUKE VINC
4) Character to tensor
문자열을 받았을때 Tensor로서 바꿔주는 역할을 한다.
1
2
3
4
5
6
7
8
# 문자열을 받았을때 이를 인덱스의 배열로 바꿔주는 함수입니다.
def char_tensor(string):
tensor = torch.zeros(len(string)).long()
for c in range(len(string)):
tensor[c] = all_characters.index(string[c])
return tensor
print(char_tensor('ABCdef'))
tensor([36, 37, 38, 13, 14, 15])
5) Chunk into input & label
Parameter로서 받은 문자열을 Input Data와 Target Data로서 분류하는 작업이다.
ex)
- Parameter: pytorch
- Input: pytorc
- Target: ytorch
1
2
3
4
5
def random_training_set():
chunk = random_chunk()
inp = char_tensor(chunk[:-1])
target = char_tensor(chunk[1:])
return inp, target
아래의 Model에서는 하나의 Character를 입력받아 다음 Character를 출력하는 Model이다.
이러한 Model에 Chunk_size만큼 Character를 Input으로서 사용하겠다는 의미는 Batch처리를 하겠다는 의미와도 같다.
RNN Model
1)Model 선언
Model에 Input으로 들어가는 Value는 앞에서 Char_RNN에서 했던 One-hot-vector방식이 아닌 Embdeeing을 통하여 이루워 진다.
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None)
- num_embedding: Embedding 의 Size(Vocab size)
- embedding_dim: 각각의 Embedding Vector의 Size
- padding_idx: Output의 Vector의 크기를 맞추기 위하여 사용
- max_norm: Embedding Vector안의 요소가 일정크기 이상이면 새롭게 Normalization을 실시
- norm_type: p_norm or max_norm 을하여 모든 요소의 값을 0 ~ 1값으로 바꾸기 위하여 사용
torch.nn.RNN(*args, **kwargs)
\(h_t = tanh(W_{ih}x_t + b_{ih} + W_{hh}h_{t+1} + b_{hh})\)
- input_size: Input Size
- output_size: Output Size
- num_layers: Number of layers
- nonlinearity: tanh or relu(Default: tanh)
- bias: True or False
- batch_first: 만약 True로 설정하면 Input Data = (batch, seq, feature)로서 설정해야 한다.
- dropout: Dropout설정
- bidirectrional: 양방향 RNN으로 설정하지(Default: False)
참조: Pytorch 정식 사이트
또한 위에서 Chunk_size로서 Batch_size를 정하고 Batch_size만큼 Input이 들어오게 된다. 따라서 Encoder와 Decoder에 들어오는 Data의 Size를 -1을 통하여 각각의 Size에 맞게 변환 후 사용해야 한다.
- input.view(1,-1): Input은 Character하나이므로 (1,-1)로서 Shape 변환
- out.view(batch_size,-1): Output은 들어온 Batch_Size만큼 변환하여 결과 수행
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class RNN(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, output_size, num_layers=1):
super(RNN, self).__init__()
self.input_size = input_size
self.embedding_size = embedding_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.encoder = nn.Embedding(self.input_size, self.embedding_size)
self.rnn = nn.RNN(self.embedding_size,self.hidden_size,self.num_layers)
self.decoder = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden):
out = self.encoder(input.view(1,-1))
out,hidden = self.rnn(out,hidden)
out = self.decoder(out.view(batch_size,-1))
return out,hidden
def init_hidden(self):
hidden = torch.zeros(self.num_layers, batch_size, self.hidden_size)
return hidden
model = RNN(n_characters, embedding_size, hidden_size, n_characters, num_layers)
2) Model에 미리 선언한 Parameter 대입
1
2
3
4
5
model = RNN(input_size=n_characters,
embedding_size=embedding_size,
hidden_size=hidden_size,
output_size=n_characters,
num_layers=2)
3) Define Loss Function & Optimizer
- LossFunction: CrossEntropy
- Optimizer: Adam
1
2
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_func = nn.CrossEntropyLoss()
4) Test Function
중간중간 결과 확인을 위한 Function
아래 두가지의 Parameter를 살펴보게 되면 2가지의 과정을 거치게 된다.
최종적인 목적을 말하게 되면 항상 같은 문장이 생성되는 것이 아닌 매번 달라지는 문장을 생성하는 것이 목표이다.
이러한 확률적인 방법은 각각의 단어에 나올 확률을 기반으로 이루워진다.
output_dist = output.data.view(-1).div(0.8).exp()
위의 Code는 확률적인 문장 생성을 위한 Code이다.
0.8로서 나눔으로 인하여 문장의 확률을 조금 Normalization하는 효과가 있다.
torch.multinomial(output_dist, 1)[0]
위의 결과로 얻어진 확률분포를 통하여 확률적으로 단어를 선택하게 하는 Code이다.
EX) out_dist = [0.2, 0.8]이면 첫번째 단어가 나올확률은 20%, 두번째 단어가 나올 확률은 80%로서 단어를 선택하는 방법이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 임의의 문자(start_str)로 시작하는 길이 200짜리 모방 글을 생성하는 코드입니다.
def test():
start_str = "b"
inp = char_tensor(start_str)
hidden = model.init_hidden()
x = inp
print(start_str,end="")
for i in range(200):
output,hidden = model(x,hidden)
output_dist = output.data.view(-1).div(0.8).exp()
top_i = torch.multinomial(output_dist, 1)[0]
predicted_char = all_characters[top_i]
print(predicted_char,end="")
x = char_tensor(predicted_char)
5) Train
Mini_Batch처리를 하고있으므로 실질적인 Loss는 Batch_Size인 Chunk_len으로서 나눈 것 이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
acc_list = []
for i in range(num_epochs):
# 랜덤한 텍스트 덩어리를 샘플링하고 이를 인덱스 텐서로 변환합니다.
inp,label = random_training_set()
hidden = model.init_hidden()
loss = torch.tensor([0]).type(torch.FloatTensor)
optimizer.zero_grad()
for j in range(chunk_len-1):
x = inp[j]
y_ = label[j].unsqueeze(0).type(torch.LongTensor)
y,hidden = model(x,hidden)
loss += loss_func(y,y_)
loss.backward()
optimizer.step()
if i % 100 == 0:
print("\n",loss/chunk_len,"\n")
acc_list.append(loss/chunk_len)
test()
print("\n","="*100)
tensor([4.5817], grad_fn=<DivBackward0>)
*bSl 8RX{dj3\b['*jb3@<'Dhj6)5Uw4)mebp!A9*kZLeRiE_b0I.J8ot4 tPLg(hxH2*GwrmQph\?kNiYU_ >g
G(wjFyV@Vg&X.z|%
====================================================================================================
tensor([2.4368], grad_fn=<DivBackward0>)
...
tensor([1.6637], grad_fn=<DivBackward0>)
boor my be bryiet'd surpreed.
PAUS:
O glair to a demery in quils?
DHKINCA:
The wive hower by this she not the cothe bock, the come.
BUCKIS:
The conceadents with apfitiner, what with him a known?
NO
====================================================================================================
LSTM
LSTM 은 딥러닝에서 사용하는 Long Short Term Memory Model으로서 RNN의 Long Term Dependency를 해결한 Model이다. 대표적인 예와 알아두면 좋은 추가적인 이론은 아래 링크를 참조하자.
1) Model
위의 RNN과 거의 같고, 달라진 부분은 nn.RNN을 nn.LSTM으로 바꾼것 뿐이다.
torch.nn.LSTM(*args, **kwargs)
- σ(시그모이드): 0 ~ 1의 범위를 가지게 출력형태를 바꿔주며 데이터를 얼마만큼 통과시킬지를 정하는 비율
- tanh(하이퍼 볼릭 탄젠트): -1 ~ 1의 범위를 가지게 출력형태를 바꿔주며 실질적인 정보의 비율
- Output gate: \(o = \sigma (W_{xh_o}x_t +W_{hh_o}h_{t-1} + b_{h_o})\): 다음 시간의 Hidden Layer에서 얼만큼 중요한가를 나타내는 상수
- Forget gate: \(f_t = \sigma (W_{xh_f}x_t +W_{hh_f}h_{t-1} + b_{h_f})\): 과거 정보를 잊기 위한 게이트(0 ~ 1사이의 값을 가지는 Scalar로서 얼만큼 잊을지 비율로서 표현)
- \(g\): \(tanh(W_{xh_g}x_t +W_{hh_g}h_{t-1} + b_{h_g})\): tanh를 사용하여 현재 LSTM Layer에서의 실질적인 정보의 비율
- Input gate: \(i_t = \sigma (W_{xh_i}x_t +W_{hh_i}h_{t-1} + b_{h_i})\): 현재 정보를 기억하기 위한 게이트(0 ~ 1사이의 값을 가지는 Scalar로서 얼만큼 기억할 비율로서 표현)
- \(c_t\): 기억 셀로서 과거로부터 시각 t까지에 필요한 모든 정보가 저장된 Cell, \(c_t = f \odot c_{t-1} + g \odot i\)
- \(h_t\): \(o \odot tanh(c_t)\): Hidden Layer의 출력 o가 Sigmoid의 Output으로서 상수이므로 \(\odot\) 사용
nn.RNN과 Parameter는 같으나 return값이 Hidden과 Cell이 출력된다는 것 이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class RNN(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, output_size, num_layers=1):
super(RNN, self).__init__()
self.input_size = input_size
self.embedding_size = embedding_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.encoder = nn.Embedding(self.input_size, self.embedding_size)
self.rnn = nn.LSTM(self.embedding_size,self.hidden_size,self.num_layers)
self.decoder = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, cell):
out = self.encoder(input.view(1,-1))
out,(hidden,cell) = self.rnn(out,(hidden,cell))
out = self.decoder(out.view(batch_size,-1))
return out,hidden,cell
def init_hidden(self):
hidden = torch.zeros(self.num_layers,batch_size,self.hidden_size)
cell = torch.zeros(self.num_layers,batch_size,self.hidden_size)
return hidden,cell
model = RNN(n_characters, embedding_size, hidden_size, n_characters, num_layers)
2) Model에 미리 선언한 Parameter 대입
1
2
3
4
5
model = RNN(input_size=n_characters,
embedding_size=embedding_size,
hidden_size=hidden_size,
output_size=n_characters,
num_layers=2)
3) Define Loss Function & Optimizer
1
2
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_func = nn.CrossEntropyLoss()
4) Test Function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def test():
start_str = "b"
inp = char_tensor(start_str)
hidden,cell = model.init_hidden()
x = inp
print(start_str,end="")
for i in range(200):
output,hidden,cell = model(x,hidden,cell)
output_dist = output.data.view(-1).div(0.8).exp()
top_i = torch.multinomial(output_dist, 1)[0]
predicted_char = all_characters[top_i]
print(predicted_char,end="")
x = char_tensor(predicted_char)
5) Train
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
acc_list2 = []
for i in range(num_epochs):
inp,label = random_training_set()
hidden,cell = model.init_hidden()
loss = torch.tensor([0]).type(torch.FloatTensor)
optimizer.zero_grad()
for j in range(chunk_len-1):
x = inp[j]
y_ = label[j].unsqueeze(0).type(torch.LongTensor)
y,hidden,cell = model(x,hidden,cell)
loss += loss_func(y,y_)
loss.backward()
optimizer.step()
if i % 100 == 0:
print("\n",loss/chunk_len,"\n")
acc_list2.append(loss/chunk_len)
test()
print("\n\n")
tensor([4.5899], grad_fn=<DivBackward0>)
bTx
vova%>]K/3Y'I.I7<S(DSMf{cyF^
& $H'hH)d9Po'BskFs^?%Un 9C(L9@D-sm%\Ss/C)$-:IpC@_-g$G]"9]v;5l2ze*cn[3vjiuU[}c0$`G^5`RC
\Z>hmF}ur\s6`r6}V&Cj[N6`oL|_Qxl?9ae%v/MUids>EVS5?=Hy-
A[1Cq>H#e~8&"5fM<wu]2'e"w^T
tensor([3.0494], grad_fn=<DivBackward0>)
...
tensor([1.9526], grad_fn=<DivBackward0>)
bhighs it fir wistorn the sway on to wight; the rowas the lamar sook and my my ene shich the grome,
The slaid and staso
And fare, mans,
Then or you shes mut have dest preshes nost but and she tried the
RNN vs LSTM Loss 시각화
1
2
3
4
5
6
7
8
9
10
11
import matplotlib.pyplot as plt
# 그래프 그리기
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o',label='RNN')
plt.plot(x, acc_list2, marker='s',label='LSTM')
plt.legend()
plt.xlabel('Epoch * 100')
plt.ylabel('Loss')
plt.ylim(0, 5)
plt.show()
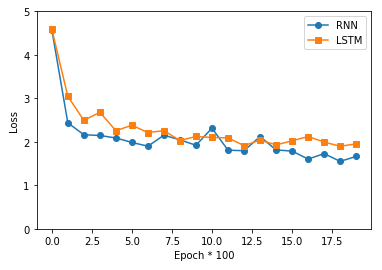
간단한 Model구현으로서 서로 Loss차이가 거의 없는 것을 확인할 수 있다.
오히려 RNN이 더욱 좋은 Model로서 Trainning된 것을 확인할 수 있다
참조: 원본코드
참조: 파이토치 첫걸음
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment