
Tensorflow-RNN
RNN
RNN 은 딥러닝 자연어 처리 사용하는 인공신경망(Artificial Neural Network)이다.
RNN에 해당하는 이론에 대한 내용은 아래 링크를 참조하자.
위의 내용에서 이번 Post에서는 Tensorflow를 활용하여 RNN를 구현해보자
Tensorflow API(임베딩(Embedding))
Embedding이란 Machine Learning Algorithm에서 자연어 처리 문제를 다룰 떄 널리 사용되는 기법이다.
Embedding의 과정은 아래의 Tensorflow API로서 구현될 수 있다.
Embedding Tensorflow API
1
tf.nn.embedding_lookup(params, ids, name=None)
- params: 임베딩을 적용할 임베딩 핼영 텐서
- ids: 스칼라형태의 One-hot-Encoding으로 표현된 임베딩을 적용할 인풋 데이터
- name: 연산의 이름 (optional)
Embedding 구현
텐서플로와 numpy 라이브러리를 임포트
1
2
import tensorflow as tf
import numpy as np
원본 데이터의 전체 단어 개수(One-hot-Encoding 표현의 차원)와 축소 할 임베딩 차원을 정의
1
2
vocab_size = 100 # One-hot-encoding 된 vocab 크기
embedding_size = 25 # 임베딩된 vocab 크기
스칼라 형태의 One-hot-Encoding 인풋 데이터를 받기 위한 플레이스홀더를 정의
1
inputs = tf.placeholder(tf.int32, shape=[None])
임베딩 행렬은 선언하고 tf.nn.embedding_lookup API를 이용해서 임베딩을 수행
1
2
embedding = tf.Variable(tf.random_normal([vocab_size, embedding_size]), dtype=tf.float32)
embedded_inputs = tf.nn.embedding_lookup(embedding, inputs)
세션을 열고 변수들을 초기화
1
2
sess = tf.Session()
sess.run(tf.global_variables_initializer())
샘플 인풋 데이터를 정의하고, 임베딩을 수행해서 변형 결과를 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
input_data = np.array([7])
print("Embedding 전 인풋 데이터: ")
print(sess.run(tf.one_hot(input_data,vocab_size)))
print(tf.one_hot(input_data,vocab_size).shape)
print('Embedding 결과: ')
print(sess.run([embedded_inputs],feed_dict={inputs:input_data}))
print(sess.run([embedded_inputs],feed_dict={inputs:input_data})[0].shape)
input_data = np.array([7,11,67,42,21])
print("Embedding 전 인풋 데이터: ")
print(sess.run(tf.one_hot(input_data,vocab_size)))
print(tf.one_hot(input_data,vocab_size).shape)
print('Embedding 결과: ')
print(sess.run([embedded_inputs],feed_dict={inputs:input_data}))
print(sess.run([embedded_inputs],feed_dict={inputs:input_data})[0].shape)
Embedding 전 인풋 데이터:
[[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0.]]
(1, 100)
Embedding 결과:
[array([[-0.51674426, 0.00487127, 0.84068084, 0.9302916 , -1.8013382 ,
0.36010912, -0.6714361 , -1.1757022 , 0.5983085 , -1.510787 ,
-1.3008538 , 0.7145155 , 0.11995181, 1.5791241 , 1.8553414 ,
-0.27274016, 0.06851366, 0.28717 , 0.8271994 , 0.2263984 ,
-0.24412726, 0.4041885 , -1.751218 , -0.35375005, -0.5199548 ]],
dtype=float32)]
(1, 25)
Embedding 전 인풋 데이터:
[[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
...
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0.]]
(5, 100)
Embedding 결과:
[array([[-0.51674426, 0.00487127, 0.84068084, 0.9302916 , -1.8013382 ,
0.36010912, -0.6714361 , -1.1757022 , 0.5983085 , -1.510787 ,
-1.3008538 , 0.7145155 , 0.11995181, 1.5791241 , 1.8553414 ,
-0.27274016, 0.06851366, 0.28717 , 0.8271994 , 0.2263984 ,
...
1.6010855 , -0.19003063, -1.2525078 , 0.39467615, -1.9226099 ,
0.1577744 , 0.62687063, 0.7255562 , 0.49477506, 1.6029706 ]],
dtype=float32)]
(5, 25)
RNN 구현(Char-RNN)
Char-RNN은 하나의 글자를 RNN의 입력값으로 받고, RNN은 다음에 올 글자를 예측하는 문제이다.
이를 위해서 RNN의 타겟 데이터를 인풋 문장에서 한 글자씩 뒤로 민 형태로 구성하면 된다.
Char-RNN의 출력값 형태는 학습에 사용하는 전체문자 집합에 대한 SOftmax 출력값이 된다.
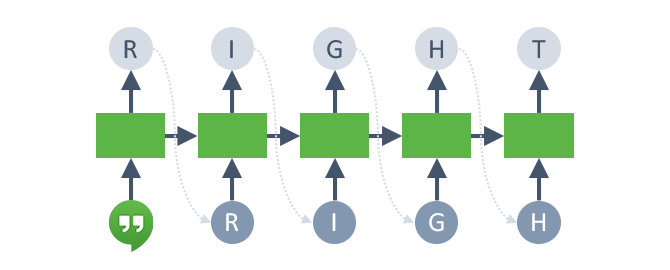
먼저 Data 전처리를 위한 과정인 utils.py를 살펴보자
utils.py
필요한 라이브러리를 임포트
1
2
3
4
5
import codecs
import os
import collections
from six.moves import cPickle
import numpy as np
TextLoader 클래스를선언
init: 생성자
- data_dir: 데이터 경로
- batch_size: 배치 크기
- seq_length: 시계열 데이터 길이 = Input Data로 받아들일 수 있는 길이라고 생각하면 된다.
기존에 전처리가 진행된 파일(vocab.pkl, data.npy)이 존재하면 불러오고 없으면 전처리 수행하여 vocab.pkl, data.npy 파일 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class TextLoader():
def __init__(self, data_dir, batch_size, seq_length, encoding='utf-8'):
self.data_dir = data_dir
self.batch_size = batch_size
self.seq_length = seq_length
self.encoding = encoding
input_file = os.path.join(data_dir, "input.txt")
vocab_file = os.path.join(data_dir, "vocab.pkl")
tensor_file = os.path.join(data_dir, "data.npy")
# 전처리된 파일들("vocab.pkl", "data.npy")이 이미 존재하면 이를 불러오고 없으면 데이터 전처리를 진행합니다.
if not (os.path.exists(vocab_file) and os.path.exists(tensor_file)):
print("reading text file")
self.preprocess(input_file, vocab_file, tensor_file)
else:
print("loading preprocessed files")
self.load_preprocessed(vocab_file, tensor_file)
# 배치를 생성하고 배치 포인터를 배치의 시작지점으로 리셋합니다.
self.create_batches()
self.reset_batch_pointer()
데이터 전처리를 진행하는 preprocess method 정의
input.txt 파일을 읽어 전체 문제들에 대하여 vocab Dictionary를 만들고, 텍스트 데이터를 id 형태로 바꿔서 data.npy파일로 저장한다.
- collection.Count() => 각각의 요소가 몇개 인지 파악
- .items() => Key, Value를 쌍으로 가져온다.
- zip()=> 동일한 개수로 이루어진 자료형을 묶어 주는 역할
여기서의 id는 단어별 반복 횟수라고 생각할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 데이터 전처리를 진행합니다.
def preprocess(self, input_file, vocab_file, tensor_file):
with codecs.open(input_file, "r", encoding=self.encoding) as f:
data = f.read()
# 데이터에서 문자(character)별 등장횟수를 셉니다.
counter = collections.Counter(data)
count_pairs = sorted(counter.items(), key=lambda x: -x[1])
self.chars, _ = zip(*count_pairs) # 전체 문자들(Chracters)
self.vocab_size = len(self.chars) # 전체 문자(단어) 개수
self.vocab = dict(zip(self.chars, range(len(self.chars)))) # 단어들을 (charcter, id) 형태의 dictionary로 만듭니다.
# vocab dictionary를 "vocab.pkl" 파일로 저장합니다.
with open(vocab_file, 'wb') as f:
cPickle.dump(self.chars, f)
# 데이터의 각각의 character들을 id로 변경합니다.
self.tensor = np.array(list(map(self.vocab.get, data)))
# id로 변경한 데이터를 "data.npy" binary numpy 파일로 저장합니다.
np.save(tensor_file, self.tensor)
Vocab File
[(' ',
'e',
't',
'o',
'a',
...
'Q',
'Z',
'X',
'3',
'&',
'$')]
data File
array([50, 9, 7, ..., 26, 10, 11])
미리 전처리된 vocab.pkl 파일이 존재하면 해당 파일들을 읽어서 변수에 할당
1
2
3
4
5
6
7
8
# 전처리한 데이터가 파일로 저장되어 있다면 파일로부터 전처리된 정보들을 읽어옵니다.
def load_preprocessed(self, vocab_file, tensor_file):
with open(vocab_file, 'rb') as f:
self.chars = cPickle.load(f)
self.vocab_size = len(self.chars)
self.vocab = dict(zip(self.chars, range(len(self.chars))))
self.tensor = np.load(tensor_file)
self.num_batches = int(self.tensor.size / (self.batch_size * self.seq_length))
데이터를 배치 단위로 묶고, 인풋 데이터를 한 글자씩 뒤로 민 형태로 타겟 데이터를 구성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 전체 데이터를 배치 단위로 묶습니다.
def create_batches(self):
self.num_batches = int(self.tensor.size / (self.batch_size * self.seq_length))
# 데이터 양이 너무 적어서 1개의 배치도 만들수없을 경우, 에러 메세지를 출력합니다.
if self.num_batches == 0:
assert False, "Not enough data. Make seq_length and batch_size small."
# 배치에 필요한 정수만큼의 데이터만을 불러옵니다. e.g. 1115394 -> 1115000
self.tensor = self.tensor[:self.num_batches * self.batch_size * self.seq_length]
xdata = self.tensor
ydata = np.copy(self.tensor)
# 타겟 데이터는 인풋 데이터를 한칸 뒤로 민 형태로 구성합니다.
ydata[:-1] = xdata[1:]
ydata[-1] = xdata[0]
# batch_size 크기의 배치를 num_batches 개수 만큼 생성합니다.
self.x_batches = np.split(xdata.reshape(self.batch_size, -1),
self.num_batches, 1)
self.y_batches = np.split(ydata.reshape(self.batch_size, -1),
self.num_batches, 1)
다음 배치를 불러오는 next_batch 함수와 배치의 인덱스를 1번째 배치로 리셋하는 reset_batch_pointer 함수를 정의
1
2
3
4
5
6
7
8
9
# 다음 배치롤 불러오고 배치 포인터를 1만큼 증가시킵니다.
def next_batch(self):
x, y = self.x_batches[self.pointer], self.y_batches[self.pointer]
self.pointer += 1
return x, y
# 배치의 시작점을 데이터의 시작지점으로 리셋합니다.
def reset_batch_pointer(self):
self.pointer = 0
Char-RNN
유틸리티 함수를 모아놓은 utils 모듈에서 학습 데이터를 읽고 전처리 하기 위한 TextLoader 클래스를 임포트
1
from utils import TextLoader
학습에 필요한 설정값들을 지정
RNN의 경우 시계열 데이터를 다루기 때문에 시계열 길이를 나타내는 차원 seq_length 추가
1
2
3
4
5
6
7
8
9
10
# 학습에 필요한 설정값들을 지정합니다.
data_dir = 'data/tinyshakespeare'
#data_dir = 'data/linux'
batch_size = 50 # Training : 50, Sampling : 1
seq_length = 50 # Training : 50, Sampling : 1
hidden_size = 128 # 히든 레이어의 노드 개수
learning_rate = 0.002
num_epochs = 2
num_hidden_layers = 2
grad_clip = 5 # Gradient Clipping에 사용할 임계값
TextLoader 클래스를 이용해서 학습 데이터를 불러온다.
학습 데이터에 포함된 모든 단어들을 포함한 List인 Chars 와 id를 부여해 Dictionary 형태로 만든 vocab을 선언
1
2
3
4
5
6
# TextLoader를 이용해서 데이터를 불러옵니다.
data_loader = TextLoader(data_dir, batch_size, seq_length)
# 학습데이터에 포함된 모든 단어들을 나타내는 변수인 chars와 chars에 id를 부여해 dict 형태로 만든 vocab을 선언합니다.
chars = data_loader.chars
vocab = data_loader.vocab
vocab_size = data_loader.vocab_size # 전체 단어개수
인풋 데이터와 타겟 데이터, 초기 상태값을 입력 받기 위한 플레이스 홀더 선언
batch_size와 Input Data의 크기인 seq_length로 나중에 치환하기 위하여 None으로서 선언
1
2
3
4
# 인풋데이터와 타겟데이터, 배치 사이즈를 입력받기 위한 플레이스홀더를 설정합니다.
input_data = tf.placeholder(tf.int32, shape=[None, None]) # input_data : [batch_size, seq_length])
target_data = tf.placeholder(tf.int32, shape=[None, None]) # target_data : [batch_size, seq_length])
state_batch_size = tf.placeholder(tf.int32, shape=[]) # Training : 50, Sampling : 1
Hidden_Layer의 크기는 RNN 마지막 은닉층 출력값을 vocab_size만큼의 소프트맥스 행렬로 변환하기 위한 변수들 설정
1
2
3
4
# RNN의 마지막 히든레이어의 출력을 소프트맥스 출력값으로 변환해주기 위한 변수들을 선언합니다.
# hidden_size -> vocab_size
softmax_w = tf.Variable(tf.random_normal(shape=[hidden_size, vocab_size]), dtype=tf.float32)
softmax_b = tf.Variable(tf.random_normal(shape=[vocab_size]), dtype=tf.float32)
vocab_size 크기의 인풋 데이터를 hidden_size 크기로 임베딩을 수행
인풋 데이터의 임베딩된 형태인 inputs 변수를 RNN의 입력값으로 사용
1
2
3
4
# 인풋데이터를 변환하기 위한 Embedding Matrix를 선언합니다.
# vocab_size(One-Hot Encoding 차원) -> hidden_size (Embedded 차원)
embedding = tf.Variable(tf.random_normal(shape=[vocab_size, hidden_size]), dtype=tf.float32)
inputs = tf.nn.embedding_lookup(embedding, input_data)
즉 현재 RNN의 구조를 보게 되면
Input(batch_size, seq_length) => One-hot-Encoding(vocab size) => Embedding(hidden_size)
=> Hidden Layer(Hidden Size, Num_Hidden_Size(2))
=> Softmax Layer(Hidden Size -> Vocab Size)
가 반복된다는 것을 알 수 있다.
Num_Hidden_Size(2)는 CNN처럼 문장에서 Feature의 개수 라고 생각할 수 있다.
Softmax 에서 차원이 늘어나는 이유는 전체 Voacb 중에서 일부를 사용하기 때문이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# 초기 state 값을 0으로 초기화합니다.
initial_state = cell.zero_state(state_batch_size, tf.float32)
# 학습을 위한 tf.nn.dynamic_rnn을 선언합니다.
# outputs : [batch_size, seq_length, hidden_size]
outputs, final_state = tf.nn.dynamic_rnn(cell, inputs, initial_state=initial_state, dtype=tf.float32)
# ouputs을 [batch_size * seq_length, hidden_size] 형태로 변환합니다.
output = tf.reshape(outputs, [-1, hidden_size])
# 최종 출력값을 설정합니다.
# logits : [batch_size * seq_length, vocab_size]
logits = tf.matmul(output, softmax_w) + softmax_b
probs = tf.nn.softmax(logits)
- Loss: Softmax_with_loss
- Optimizer: AdamOptimizer
1
2
3
4
5
6
7
8
9
# Cross Entropy 손실 함수를 정의합니다.
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=target_data))
# 옵티마이저를 선언하고 옵티마이저에 Gradient Clipping을 적용합니다.
# grad_clip(=5)보다 큰 Gradient를 5로 Clipping합니다.
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, tvars), grad_clip)
optimizer = tf.train.AdamOptimizer(learning_rate)
train_step = optimizer.apply_gradients(zip(grads, tvars))
세션을 열고 학습을 진행한다.
여기서는 아까 과정에서 얘기한
Input(batch_size, seq_length) => One-hot-Encoding(vocab size)
을 통하여 현재 InputData를 Embedding 하기 위한 전처리 과정을 진행하는 것을 알 수 있다.
학습이 끝나면, 학습된 파라미터를 이용해서 새로운 문장을 생성하기 위한 샘플링을 진행하게 되는 것을 알 수 있다.
각각의 샘플링 타입의 특징을 살펴보면 argmax를 취해 정확히 다음에 올 글자를 예측할 수 있지만, 특정 알파벳 이후에는 항상 똑같은 특정 알파벳이 뽑혀서 생성되는 문장의 자유도가 떨어지는 것을 확인 할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
# 세션을 열고 학습을 진행합니다.
with tf.Session() as sess:
# 변수들에 초기값을 할당합니다.
sess.run(tf.global_variables_initializer())
for e in range(num_epochs):
data_loader.reset_batch_pointer()
# 초기 상태값을 초기화합니다.
state = sess.run(initial_state, feed_dict={state_batch_size : batch_size})
for b in range(data_loader.num_batches):
# x, y 데이터를 불러옵니다.
x, y = data_loader.next_batch()
# y에 one_hot 인코딩을 적용합니다.
y = tf.one_hot(y, vocab_size) # y : [batch_size, seq_length, vocab_size]
y = tf.reshape(y, [-1, vocab_size]) # y : [batch_size * seq_length, vocab_size]
y = y.eval()
# feed-dict에 사용할 값들과 LSTM 초기 cell state(feed_dict[c])값과 hidden layer 출력값(feed_dict[h])을 지정합니다.
feed_dict = {input_data : x, target_data: y, state_batch_size : batch_size}
for i, (c, h) in enumerate(initial_state):
feed_dict[c] = state[i].c
feed_dict[h] = state[i].h
# 파라미터를 한스텝 업데이트합니다.
_, loss_print, state = sess.run([train_step, loss, final_state], feed_dict=feed_dict)
print("{}(학습한 배치개수)/{}(학습할 배치개수), 반복(epoch): {}, 손실함수(loss): {:.3f}".format(
e * data_loader.num_batches + b,
num_epochs * data_loader.num_batches,
(e+1),
loss_print))
print("트레이닝이 끝났습니다!")
# 샘플링을 시작합니다.
print("샘플링을 시작합니다!")
num_sampling = 4000 # 생성할 글자(Character)의 개수를 지정합니다.
prime = u' ' # 시작 글자를 ' '(공백)으로 지정합니다.
sampling_type = 1 # 샘플링 타입을 설정합니다.
state = sess.run(cell.zero_state(1, tf.float32)) # RNN의 최초 state값을 0으로 초기화합니다.
# Random Sampling을 위한 weighted_pick 함수를 정의합니다.
def weighted_pick(weights):
t = np.cumsum(weights)
s = np.sum(weights)
return(int(np.searchsorted(t, np.random.rand(1)*s)))
ret = prime # 샘플링 결과를 리턴받을 ret 변수에 첫번째 글자를 할당합니다.
char = prime # Char-RNN의 첫번째 인풋을 지정합니다.
for n in range(num_sampling):
x = np.zeros((1, 1))
x[0, 0] = vocab[char]
# RNN을 한스텝 실행하고 모델이 예측한 Softmax 행렬을 리턴으로 받습니다.
feed_dict = {input_data: x, state_batch_size : 1, initial_state: state}
[probs_result, state] = sess.run([probs, final_state], feed_dict=feed_dict)
# 불필요한 차원을 제거합니다.
# probs_result : (1,65) -> p : (65)
p = np.squeeze(probs_result)
# 샘플링 타입에 따라 3가지 종류 중 하나로 샘플링 합니다.
# sampling_type : 0 -> 다음 글자를 예측할때 항상 argmax를 사용
# sampling_type : 1(defualt) -> 다음 글자를 예측할때 항상 random sampling을 사용
# sampling_type : 2 -> 다음 글자를 예측할때 이전 글자가 ' '(공백)이면 random sampling, 그렇지 않을 경우 argmax를 사용
if sampling_type == 0:
sample = np.argmax(p)
elif sampling_type == 2:
if char == ' ':
sample = weighted_pick(p)
else:
sample = np.argmax(p)
else:
sample = weighted_pick(p)
pred = chars[sample]
ret += pred # 샘플링 결과에 현재 스텝에서 예측한 글자를 추가합니다. (예를들어 pred=L일 경우, ret = HEL -> HELL)
char = pred # 예측한 글자를 다음 RNN의 인풋으로 사용합니다.
print("샘플링 결과:")
print(ret)
결과
샘플링 결과:
s
샘플링 결과:
sl
샘플링 결과:
sla
샘플링 결과:
slaw
샘플링 결과:
slawb
샘플링 결과:
slawbl
...
slawbles
Which are our mornione habkehford, here bushwind!
Bad you nexcetio blood!
Gvold him severcous at so, but that fellow'd,
exeched, gold ofter. Tho sate of each her thile,
What have I am will our made me longd?
TRANIO:
Come, dolder, his not dow, how impil;
Marsay, not the partia on the tranchidy.
And for deed, among thyself; and alcors for age
Gracenit asmose overdician he should bound
Moy't towelf, and that let thy live
Onued that to a cruched to our had, if each,
Be by my se'er! you never burhed, slecteds;
This your Iracher?
BAAPTISTA:
Let to me her. There is an agains no soundly.
I made diughts' be glace to no leation.
Is millour's have now. Let of us go suse, he
mow comfortt, I have her sound son him,
And, kiss as thing your falpers for if scarched:
Moraful sown hechard viration to humble courtses;
Now seil that did five hath and pather!
TRANIO:
Think Warrwase him: he shall York. Why, I will that
me I dost be that these what imasted this camas?
Whatchese is my ludes, but my he.
GLOUCESTER:
Provost, for you have some fell the have with you?
DEWBARAS:
Have with thank whath this a father's aispectu,
For you be eccoming ave for me glattles
To bush: he extray'd that upon he curt appish: go
Thy coltness; with this hurd she trick on this clome
That buck of us the enchast, it.
Thell! Boyond the sudate a fair thoughtsor, look'd
Spake whith good for the ssurdure too 'tworn!
I than thy courtchiof soldeon mell, me a
As stitors, I am ming him, brother's
he will cut be pritone with me.
BIANCAS:
What have is the been him: he did intummand procke!
For she will be are before him.
downor! why, sir?
Pesscautiage! me.
LUCIO:
He is nature prombs, as thou hast thy first,
Have seed high a earsench, made perfectuse:
We islack before; stard tongue it, is,
And mercheived, and I must naturm come
Coya, destremble come he princase,
I mean thy shaw that for I, let are being,
And me not sakfittimes in be soon: Farew!
Thou done both firathel, as then in them from home: conses;
And as I die hath that he princer'd Ustress,
Which in the blood to stir; but thou wert ge answina hard and well?
BUCKINGHAM:
All this sich me, have all, then?
Whither.
NLORET:
Even our wish! say, since a bidle. I plocewing but?
NORTHUMBERLAND:
VICINIIUS:
Nay, paiment theyo well but me sweer, I
have she's a heaven of the fair's o
Thear him, lawisticle Gaunt as both:
But bid the blood propittle the forson a creasord.
What plecaused Say where come of Lord you
Courportly with have all hence, to hwigh,
Sight, us with tronfior will peence me, by a proft:
Unle-for say artworn him sweath practory,
But I chapes take tyrabouts, come paidly. you
diel ere guesty of they wishally: falcy, and he see!
How it else head and stray set like of herd.
VINCENTIO:
Good by frear in time, let be world.
CATESVIOL:
Why, prilost, if reached, and phat mort, to for: Antis,
Bacest, no heads, sir in they or thank'd.
Now a wo a do.
Secans:
Be hire forench her virstorty-wast of muse prace,
Of mighting not strangs sterof of his manss
When her in her for not fear heavy conscured
Is cannot gentleman?
CAPUSE:
No warranch my! then, old me name a deas?
ABAPTISTA:
You, sir, but to't this mispectled, both the pails.
CAMILLO:
Away, and not cortain's; and in the eaturdous new
Do her here body father a prayer so a readous;
Then offices and breedy: ond the leady.
I cannot get a banessore be princes women,
I cannot no mighness be of?
DUKE VINCENTIO:
Where Mrachant to them, and moot
Cablead? I barest execused you, slaw me! distrief!
In Luachord, goen and you dead.
KING LIENE BIHARTHAM
BAVIAN:
Tim, that raib mistred me abanied: I, at hath cape
My condects that the oft your hone!
Lood no lookn'ds hourt! I, a doness more the quwers: need,
And cannot prayer: I nor likess that wife,
And Cawair and blood--
Canto: n
참조:원본코드
참조:텐서플로로 배우는 딥러닝
문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment