
SSD(Concept)
SSD
논문: SSD: Single Shot MultiBox Detector

(1) Abstract
We present a method for detecting objects in images using a single deep neural network.
Our approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location.
해당 Paper의 Abstract에서 가장 중요하다고 생각되는 부분이다.
YOLOv1(Only Concept)과 마찬가지로 기존의 사용하던 Two Stage Method가 아니라 One Stage Method(a single neural network) 를 사용하여 빠르게 Object Detection이 가능하다.
SSD의 작동방식은 다음과 같다고 설명하고 있다. Feature map location을 통하여 다른 비율과 크기로서 Default Box를 생성하고, 생성된 Default Box를 통하여 Bounding Box를 생성한다고 한다.
(2) Introduction
초반에는 YOLO와 같이 One Stage Method로서 속도가 빠르다는 것을 중점적으로 설명하고 있다.
SSD는 YOLO와 같은 방식에서 다음과 같이 개량을 하여서 속도가 빠르고 더 높은 Accuracy를 보여주는 방법이라고 소개하고 있다.
Our improvements include using a small convolutional filter to predict object categories and offsets in bounding box locations, using separate predictors (filters) for different aspect ratio detections, and applying these filters to multiple feature maps from the later stages of a network in order to perform detection at multiple scales.
With these modifications—especially using multiple layers for prediction at different scaleswe can achieve high-accuracy using relatively low resolution input, further increasing detection speed.
While these contributions may seem small independently, we note that the resulting system improves accuracy on real-time detection for PASCAL VOC from 63.4% mAP for YOLO to 74.3% mAP for our SSD.
위에서 PASCAL VOC방법으로서 Accuracy측정시 대략 10%정도 향상된 것을 보여주었다.
사용한 방법은 다음과 같다고 설명하고 있다.
- Small Convolutional Filter를 Object Categoris를 예측하는 곳과, Bounding Box Locations의 offsets에 사용한다.
- 다양한 Ratio(종횡비) 를 특정하기 위해서 Predictors(Filter)를 사용한다.
- 다양한 Scale에 적용하기 위하여 Filter는 Model의 결과로서 나온 Multiple Feature map에 적용된다.
위의 대한 자세한 내용은 실제 Model을 살펴볼 때 자세히 알아보자.
(3) The Single Shot Detector (SSD)
SSD의 결과와 과정을 다음과 같이 그림으로서 나타내고 있다.

위의 사진에 대한 자세한 내용은 아래 Model과 어떻게 Training하는지 알아보면서 자세히 알아보자.
(3-1) Model
논문에서는 SSD의 Model을 YOLO와 비교하여 다음과 같이 나타내고 있다.

중요한 점은 Model의 Input으로서 YOLO보다 더 작은 Size의 Input Image를 사용한다. 즉, 더 저해상도의 Image에서도 Object Detection을 수행한다는 것을 보여주고 있다.
또한 해당 Model에 대하여 대략적으로 다음과 같이 설명하였다.
The early network layers are based on a standard architecture used for high quality image classification (truncated before any classification layers), which we will call the base network2.
We then add auxiliary structure to the network to produce detections with the following key features:
기본적으로 YOLO와 같이 Image를 Classification하는 PreTraining된 Model(VGG16)을 Base로 사용하고 Object Detection을 하기위하여 몇몇 보조적인 기법을 사용하였다고 한다.
Multi-scale feature maps for detection
Object Detection은 다양한 Size의 Object를 검출하여야 한다.
(3-1) Model의 사진을 보아도 고양이와 강아지의 Size는 매우 다른 것을 알 수 있다.
이러한 해결방법으로서 SSD는 마지막 Layer에서 나온 FeatureMap으로서 Bounding Box를 설정하는 것이 아니라 다양한(Size가 다른) Feature Map을 생성하고 Object를 검출하도록 설계하였다.(StyleTransfer와 같이 Image의 큰 부분과 Detail한 부분까지 확인하겠다는 의미이다.)
이러한 방식은 Resampling이 없애면서도 정확도 높은 결과를 도출하게 되었다.(아래 그림을 살펴보게 되면 논문에서는 6개의 Scale이 다른 Feature Map을 사용한다.)

Convolutional predictors for detection
Introduction에서 Small Convolutional Filter를 사용하여 Object Category와 Bounding Box의 Location의 offsets을 예측하는데 사용한다고 하였다.
위의 사진을 살펴보게 되면 Prediction하는 최종적인 Layer에는 Conv: 3x3x(kx(Classes+4)) 를 수행하는 것을 확인할 수 있다.
이러한 작은 Convolutioal Filter를 사용하여 ObjectDetection하는데 사용하는 것 이다.
Default boxes and aspect ratios
Convolutional predictors for detection에서 왜 Convolutio Filter의 Size를 3x3x(kx(Classes+4))로서 정의하였는지 설명한다. 먼저, 정확한 식의 이해를 위해서 Default Boxes와 Aspect Rations에 대하여 이해하여야 한다.
먼저, (1) Abstract에서 Default Box 생성 -> Bounding Box생성이라고 말을 하였다.
YOLO의 경우 Bounding Box의 예측은 위하여 (x,y,w,h)로서 정의하였다.
SSD에서는 Faster R-CNN에서 사용한 Anchor Box와 같은 것을 Default Box라고 정의하였다.
이러한 Default Box란 Aspect Ratio를 모아둔 것 이다.
Aspect Ratio이란 Bounding Box가 가질만한 크기를 몇 가지만 추려서 정답은 이안에 있다 라고 추정하는 것 이다.
즉, 3x3x(kx(Classes+4))에서 각각의 Parameter는 다음과 같다.
- Classes: Classify할 Category개수
- 4: (x,y,w,h)
- k: Default Box의 개수
- 3x3: Convolution을 위한 Filter
하나의 예시를 들어보자.
위의 6개의 Multi-scale feature maps에서 첫번째의 경우를 생각하면 다음과 같이 나타낼 수 있다.
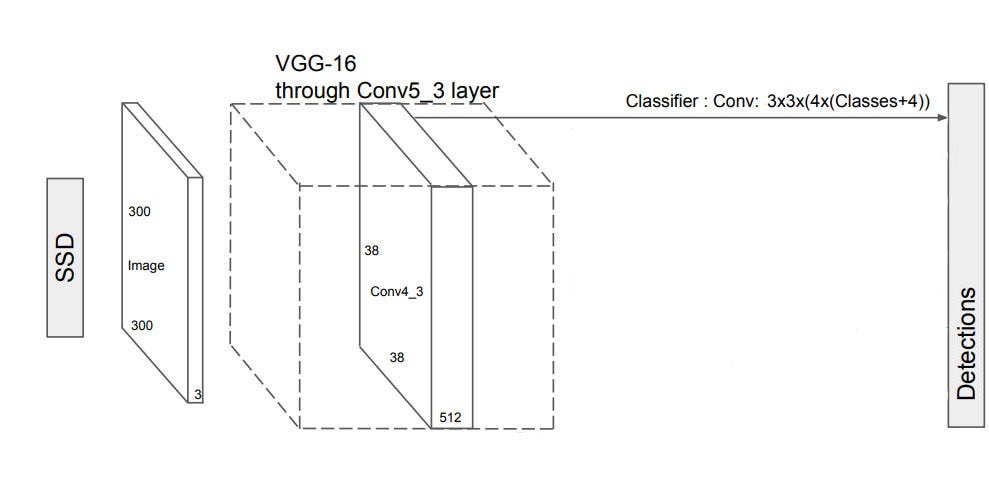
사진 출처: mc.ai
위에서 Convolution의 식은 3x3(4x(Classes+4))이다. 즉, Default Box안의 Aspect Ratio를 4개라고 미리 정의해둔 것 이다.
이러한 결과는 다음과 같이 나타낼 수 있다.
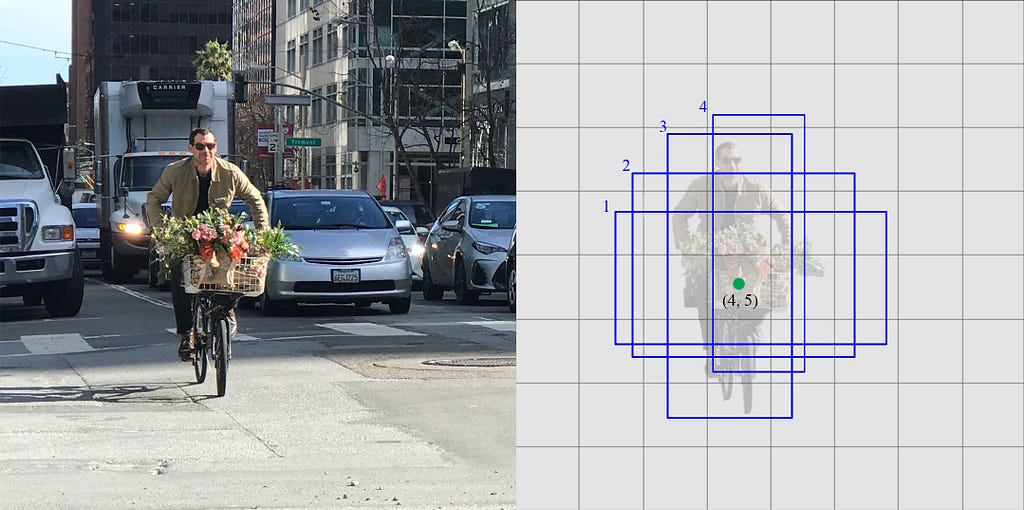
사진 출처: mc.ai
위와 같이 생긴 Default Box를 사용하여 Class까지 예측한 Predicted Box는 다음과 같이 생성된다.
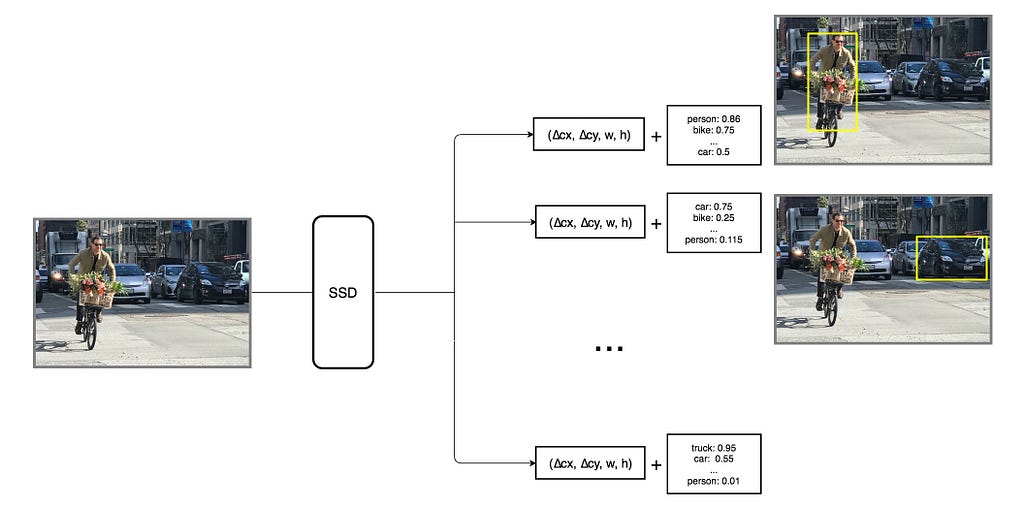
사진 출처: mc.ai
위의 과정으로 인하여 Output Tensor의 크기를 확인하면 다음과 같다.
$$(38*38*512) \longrightarrow^{4*3*3*512*(20+4)}_{} (38*38*4*(20+4)) \text{, Num of Categories=20}$$
솔직히 개인적으로는 위의 사진과, 설명만으로는 어떻게 Default Box를 생성하는지 이해가 되지 않았다.
나중에 Python Code로서 직접 Default Box를 생성하는 과정이 따로 있다.
따라서 지금 이해가 되지 않더라면 뒤의 Code과정에서 정확히 어떻게 생성하는지 알아보자.
(3-2) Trainning
Trainning에 앞서 자주 사용하게 될 용어를 정리하고 시작하자.
- Ground Truth Box: 예측해야할 Label Box(Class, Box위치가 정해져 있음)
- Default Box: 미리 Scale과 Aspect Ratio로서 Object의 크기를 예측해둔 Box
- Predicted Box: Default Box로서 Location, Box안의 Object의 Class를 Model에서 예측한 값
즉, 최종적으로는 Ground Truth Box와 Predicted Box의 차이로서 Loss를 구하고 Backpropagation을 진행하게 된다.
Matching strategy
Object Detection은 크게 2가지를 예측해야 한다.
- Location of Box
- Class of Box
즉, Box의 위치와 Box안의 Object의 Class를 판단하는 것이 최종적인 목표이다.
Matching Strategy는 첫번째인 Location of Box를 판단하는 과정이다.
Ground Truth Box와 Default Box의 IOU가 일정 threshold(해당 논문에서는 0.5)이상의 값을 가진 Box를 Matching한다. IOU는 jaccard overlap를 통하여 계산한다.
참고 사항(jaccard overlap)
$$J(A,B) = \frac{|A \cap B|}{|A \cup B|} = \frac{|A \cap B|}{|A|+|B|-|A \cap B|}$$
위의 식을 적용하면 Ground Truth Box안의 Pixel은 1이라두고 아닌것은 0이라 둔 뒤 Default Box와 계산하여 IOU의 값을 얻을 수 있다.
최종적인 Matching Strategy의 결과를 그림으로 나타내면 다음과 같다.
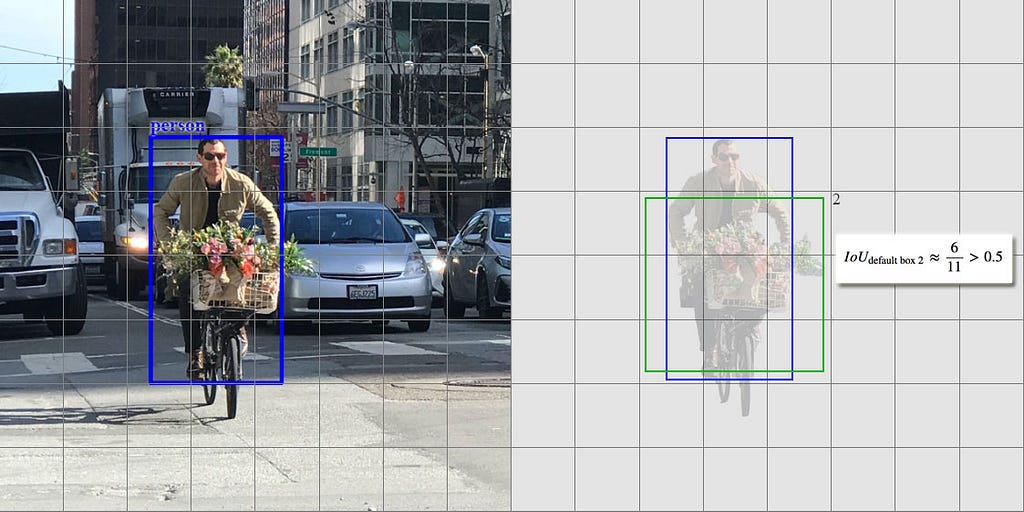
사진 출처: mc.ai
LossFunction에 대해 알아보기 전에 사용하는 변수들이 많으므로 먼저 정리를 하고 시작하자.
- \(l\): Predicted Box
- \(g\): Ground Truth Box
- \(d\): Default Box
- \(i\): Default Box 개수
- \(j\): Ground Truth Box 개수
- \(x_{ij}^p\): Class p에 대하여 Default Box와 Ground Truth Box의 IOU가 특정 Threshold값을 넘는지 판단(Matching strategy을 통하여). 넘으면 1, 아니면 0
- \(c_i\): Transfer Learning을 통하여 기존 Classify Model에서 Class를 예측한 값
- \(Pos\): Positive 즉, \(x_{ij}^p\)가 1인 Default Box
- \(Neg\): Negative 즉, \(x_{ij}^p\)가 0인 Default Box
- \(N\): Pos의 개수
- \(cx,cy\): Box의 중심 x,y의 좌표
- \(w, h\): Box의 width, height
위의 변수를 적용시켜 Predicted Box를 살펴보면 다음과 같다.
사진 출처: mc.ai
$$(38*38*512) \longrightarrow^{4*3*3*512*(20+4)}_{} (38*38*4*(20+4)) \text{, Num of Categories=20}$$
$$\therefore l = 38*38*N*(c_i+(cx,cy,w,h))\text{ , }i = 20(Class(19) + Background(1))$$
Training objective
위에서도 언급하였듯이 Loss Function을 구하기 위해서는 Location of Box와 Class of Box의 두개의 LossFunction이 필요하다.
해당 논문에서는 Location of Box에 대한 LossFunction을 localization loss(\(L_{loc}(x,l,g)\)), Class of Box에 대한 LossFunction을 confidence loss(\(L_{conf}(x,c)\))로서 표현하였다.
Localization Loss
$$L_{loc}(x,l,g) = \sum_{i \in Pos}^N \sum_{m \in cx,cy,w,h} x_{ij}^k smooth_{L1}(l_i^m-\hat{g}_j^m)$$
$$\hat{g}_j^{cx}=(g_j^{cx}-d_i^{cx})/d_i^w, \hat{g}_j^{cy}=(g_j^{cy}-d_i^{cy})/d_i^h$$
$$\hat{g}_j^{w} = log(\frac{g_j^w}{d_i^w}), \hat{g}_j^{h} = log(\frac{g_j^h}{d_i^h})$$
$$ x_{ij}^p= \begin{cases} 1, & \mbox{if } IOU > 0.5 \mbox{ between default box i and ground true box j on class p} \\ 0, & \mbox{otherwise} \end{cases} $$
위의 식은 Localization of Box의 LossFunction이다.
위의 식의 과정을 정리하면 다음과 같다.
- Matching strategy을 통하여 \(x_{ij}\)를 구하게 된다.
- 실제 Label과 Default Box를 사용하여 실제 Ground Truth Box에 가까운 \(\hat{g}_j\)를 구하게 된다. Ground Truth Box의 개수는 j개이므로 Multiple Box Location을 구할 수 있다.
- Model의 예측값인 Predicted Box와 2에서 구한 \(\hat{g}_j\)를 Smooth L1식으로서 계산한다.
참고사항(Smooth L1 Loss)
식
$$ Smooth_{L1}= \begin{cases} 0.5x^2, & |x| < 1 \\ |x|-0.5, & \mbox{otherwise} \end{cases} $$

미분
$$ \frac{d}{dx}(Smooth_{L1})= \begin{cases} -1, & x \ge -1 \\ x, & x \ge 1 \\ 1, & 1 < x \end{cases} $$

Smooth L1 Loss에 대한 자세한 내용은 링크를 참조하자.
참조: Smooth L1 Loss
Confidence Loss
$$L_{conf}(x,c) = -\sum_{i \in Pos}^N x_{ij}^p log(\hat{c}_i^p)-\sum_{i \in Neg} log(\hat{c}_i^0) \text{, where } \hat{c}_i^p = \frac{exp(c_i^p)}{\sum_p c_i^p}$$
위의 식은 Class of Box의 LossFunction이다.
위의 식의 과정을 정리하면 다음과 같다.
- Matching strategy을 통하여 Default Box와 Ground Truth Box가 Matching되었다면(Pos) Softmax를 통하여 Classify된 값을 Cross Entropy식에 적용
- Matching strategy을 통하여 Default Box와 Ground Truth Box가 Matching되지않았다면(Neg) Softmax를 통하여 Classify된 값이 Background이면 1, 아니면 0으로서 값을 가지게 CrossEntorpy식에 적용
Final Loss
$$L(x,c,l,g) = \frac{1}{N}(L_{conf}(x,c) + \alpha L_{loc}(x,l,g))$$
위의 Localization Loss와 Confidence Loss를 통하여 최종적인 Loss를 적용한다.
\(\alpha\)의 경우 cross validation에 의해 정의되는 weight term으로서 해당 논문에서는 1로서 정의하였다.
Choosing scales and aspect ratios for default boxes
다양한 Scale과 Ratio의 Default Box를 생성하는 방법이다.
기본적으로 생성하는 방법은 다음과 같다.
Scale of Default Boxes
$$s_k = s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1), k \in [1,m]$$
각각의 Scale은 \(s_{min}=0.2 or 0.1\), \(s_{max}=0.9\)로서 Feature Map의 크기에 따라서 선형적으로 증가시킨다.
Aspect Ratios
$$a_r \in {1,2,3,\frac{1}{2},\frac{1}{3}} (w_k^a = s_k\sqrt{a_r}) (h_k^a = s_k/\sqrt{a_r})$$
$$s_k^{'}=\sqrt{s_k s_{k+1}}\text{, }a_r=1 \text{ 인 경우}$$
Aspect Ratios는 해당논문에서는 위와같이 정의하였다.
Hard negative mining
Image의 대부분의 Pixel에서 Default Box가 배경인것이 많아서 \(x_{ij}^p=0\)인 값이 많았다.
따라서 LossFunction에서 positive:negative의 비율을 High confidence기준으로 1:3으로서 뽑게 하였다.
Data augmentation
Model의 성능을 증가시키기 위하여 다음과 같은 Data Augmentation의 Option을 중 하나를 선택해서 진행하였다고한다.
- Use the original
- Sample a patch with IOU of 0.1, 0.3, 0.5, 0.7 or 0.9
- Randomly sample a patch
(4) Experimental Results
많은 방면에서 SSD가 뛰어나다는 것을 보여주었지만 가장 잘 나타낸 사진은 다음과 같다.
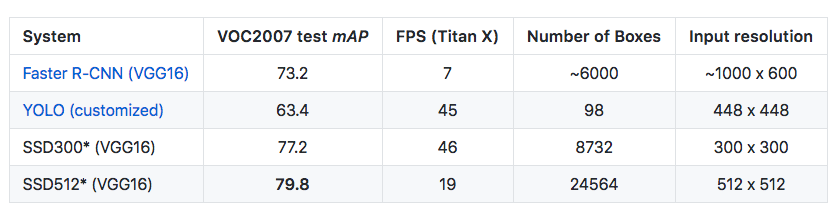
사진 출처: mc.ai
위의 결과에서 중요한 것은 YOLO와 FPS는 비슷하나 Auccuary는 10%나 증가하였다는 것 이다.
또한 YOLO에서 문제가 되었던 Small Object Detection에 대하여 다음과 같은 결과로서 잘 Detection한다는 것을 보여주고 있다.

참조: SSD: Single Shot MultiBox Detector
참조: taeu 블로그
참조: junjiwon1031 블로그
참조: mc.ai
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment