
Paper06. Latent Representation Learning for Alzheimer’s Disease Diagnosis With Incomplete Multi-Modality Neuroimaging and Genetic Data
Latent Representation Learning for Alzheimer’s Disease Diagnosis With Incomplete Multi-Modality Neuroimaging and Genetic Data
Latent Representation Learning for Alzheimer’s Disease Diagnosis With Incomplete Multi-Modality Neuroimaging and Genetic Data (https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8698846)
Abstract
The fusion of complementary information contained in multi-modality data [e.g., magnetic resonance imaging (MRI), positron emission tomography (PET), and genetic data] has advanced the progress of automated Alzheimer’s disease (AD) diagnosis.
However, multi-modality based AD diagnostic models are often hindered by the missing data, i.e., not all the subjects have complete multi-modality data. One simple solution used by many previous studies is to discard samples with missing modalities.
However, this significantly reduces the number of training samples, thus leading to a sub-optimal classification model. Furthermore, when building the classification model, most existing methods simply concatenate features from different modalities into a single feature vector without considering their underlying associations.
As features from different modalities are often closely related (e.g., MRI and PET features are extracted from the same brain region), utilizing their inter-modality associations may improve the robustness of the diagnostic model. To this end, we propose a novel latent representation learning method for multi-modality based AD diagnosis.
Specifically, we use all the available samples (including samples with incomplete modality data) to learn a latent representation space. Within this space, we not only use samples with complete multi-modality data to learn a common latent representation, but also use samples with incomplete multi-modality data to learn independent modality-specific latent representations. We then project the latent representations to the label
해당 Paper에서 중요하다고 생각하는 부분은 2가지 이다.
- Not all the subjects have complete multi-modality data. One simple solution used by many previous studies is to discard samples with missing modalities. However, this significantly reduces the number of training samples, thus leading to a sub-optimal classification model. => 모든 Experiment를 가진 Sample은 적다. 가장 쉬운 Multimodal Model을 만들기 위한 방법은 한개의 Experiment라도 받지않은 Sample은 제거하는 것 이다. 하지만, 이렇게 Sample을 제외하게 되면, 남는 Sample은 별로 없다.
- As features from different modalities are often closely related … utilizing their inter-modality associations may improve the robustness of the diagnostic model. => 이전 Paper에서도 1의 문제는 해결하였다. 하지만, Feature Extractor에서 단순한 Feature Concat으로서 Model을 구성하였다. 이는 Modality끼리의 Association을 고려하지 못 하는 것 이고, 이러한 결과로서 Modality(SNP)를 추가하여도, 성능 효과는 미비하거나 오히려 Model의 Performance는 떨어지는 결과를 보이곤 했다.
해당 Paper에서는 위의 2가지의 문제를 모두 해결하는 Model을 주장하고 있다. => Complete Data로서는 Modality끼리의 Association을 나타내는 Feature Space로서 Mapping하고, Incomplete Data로서는 각각의 Modality의 Specific한 Feature Space로서 Mapping함으로써 위의 문제 2개를 해결하게 되었다.
Introduction
In automated AD diagnosis studies using multi-modality data, the feature dimension is usually very high (e.g., tens of thousands) while the number of training samples is limited, i.e., it is a typical small-sample-size problem.
Although various feature selection and dimension reduction methods have been proposed, there are still two challenges with automatic AD diagnosis systems using multi-modality neuroimaging (i.e., MRI and PET) and genetic data (i.e., SNP).
The first challenge is that it is difficult to exploit the inherent association among multi-modality data.
The second challenge in multi-modality based AD diagnosis system is the missing data issue, i.e., not all the samples have complete multi-modality data.
Specifically, we assume there exists a latent space for multi-modality data, to which each modality can be projected. The projection from different modalities to this common latent space is expected to model the association among different modalities.
To make full use of all available samples for learning a more reliable prediction model, we utilize samples with complete multi-modality data to learn the common latent feature representation, and utilize samples with incomplete multi-modality data to learn an independent (i.e., modality-specific) latent feature representation for each modality. Furthermore, the learned latent representations are projected to the corresponding label space for AD diagnosis.
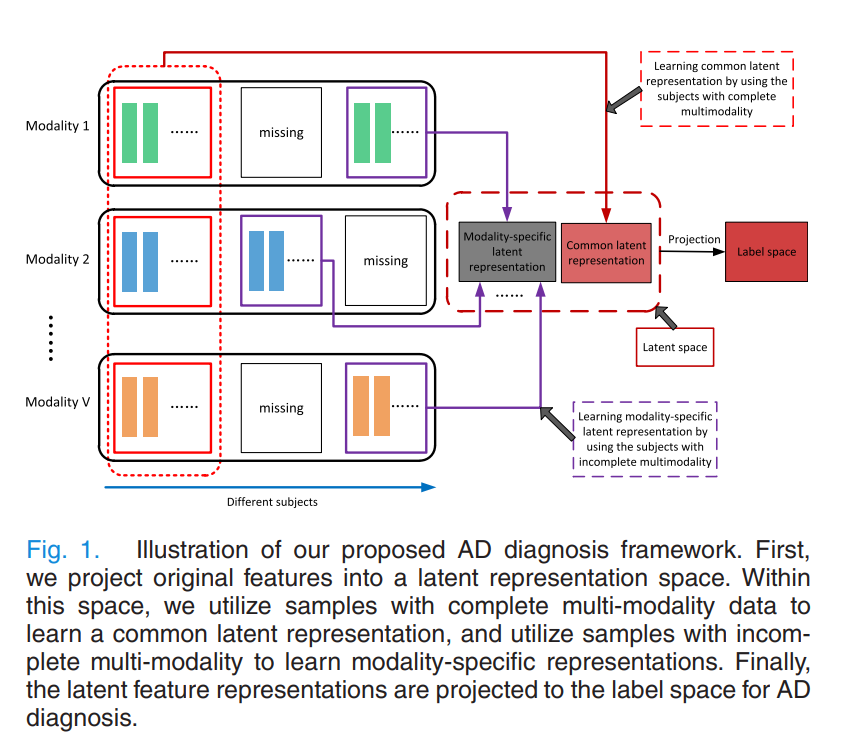
Intorduction에서는 Previous Study의 Probelm을 지적하고 있다.
Multimodality Model에서 Challenge는 크게 2가지로 좁힐 수 있다. 1) 다양한 Modality끼리의 Association을 고려하기 힘들다. 2) 모든 Sample이 Incomplte Data형태이다.
1번째 문제인 Multimodality의 Association을 고려하는 Model은 많이 존재하게 된다. 대표적으로는 CCA, ICA등이 존재하게 된다. 하지만 이러한 Multimodal Fusion Model은 Complete Data로만 가능하므로, Model의 Classification성능은 떨어질 수 밖에 없다.
2번째 문제인 Incomplete Data형태를 다루는 형태방법은 Data imputation techniques으로서 Incomlete Data -> Complete Data로 만들어서 Prediction하는 Model을 많이 있다. 대표적으로는 KNN혹은 Matrix Factoriztion이 존재하게 된다. 하지만, 이러한 Model들은 결국 Prediction하는 것 이므로 필연적으로 Noisy가 발생되어 Classification Model의 Performance를 낮추는 형태가 된다.
해당 Paper에서는 많은 Data를 사용하기 위하여 Incomplete Data까지 모두 사용함과 동시에 Modality끼리의 Association까지 고려하는 Model을 위의 그림과 같이 설명하고 있다. Incomplete Data로서는 각각의 Modality를 나타내는 Modality-specific latent representation으로서 Mapping하게 Training하게 되고, Complete Data로서는 Common latent representation으로서 Mapping되게 Training된다.
Appendix
MultiModality의 Interaction을 구하기 위해서는 AutoEncoder나 Extreme Learning Machine으로서 구현하여도, 결국 마지막 Output을 Label로 하여야 Interaction을 구할 수 있다.
단순히, 다양한 Modality를 Concat하여, Input(X) = Output(X)로서 Training하게 되면, 단순히, X를 잘 Reconstruction할 수 있는 Hidden Space로서 Training되겠지만, Input(X) != Output(Y)로서 구성하게 되면, Hidden Space는 Output으로서 잘 Mapping될 수 있도록 Training될 것 이며, 이것은 서로 다른 Modality의 Interaction을 구할 수 있는 것 이다.
해당 Paper에서는 이러한 다양한 Modality가 Label Space에 Mapping될 수 있도록, Common latenet representation을 Trainning하였다.
Data & Preprocessing
Subject
- ADNI1
- PET: 360
- MRI, SNP: 737
- AD: 171
- MCI: 362
- sMCI: 205
- pMCI: 157
- NC: 204
Preprocessing
MRI, PET => 93 ROI with GM tissue volume of each ROI in the labeled image
- AC-PC(Anteroir commissure-posterior commisure) correction using MIPAV software
- Intensity inhomogeneity correction using the N3 algorithm
- Brain extraction using a robust skull-stripping algorithm
- Cerebellum removal
- Tissues segmentation using the FAST algorithm in the FSL package to obtain three main tissues (i.e., white matter (WM), gray matter (GM), and cerebrospinal fluid
- Registration to a template using the HAMMER algorithm
- ROI labels projection from the template image to the subject image
SNP
- According to the AlzGene database,3 only SNPs belonging to the top AD gene candidates were selected.
- The selected SNPs were imputed to estimate the missing genotypes, and Illumina annotation information was used to select a subset of SNPs
Appendix
A large scale multivariate parallel ICA method reveals novel imaging–genetic relationships for Alzheimer’s disease in the ADNI cohort(https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3312985/) Paper에서는 SMRI와 SNP 2개의 Modality의 Correlation을 P-ICA로서 구하였다.
다른 많은 Paper에서도 SMRI 1개의 Modality를 사용하는 경우, Freesurfer를 사용하게 된다.
하지만, 위와 같이 PET, SMRI를 동시에 사용하는 경우 위와 같은 다양한 Preprocess과정을 거치게 되어서 93 ROI가 Output이 되도록 Preprocessing을 진행하게 되며, PET과 SMRI의 ROI는 동일한 부분으로서 Interaction을 기대하게 된다.
Methodology
Notation
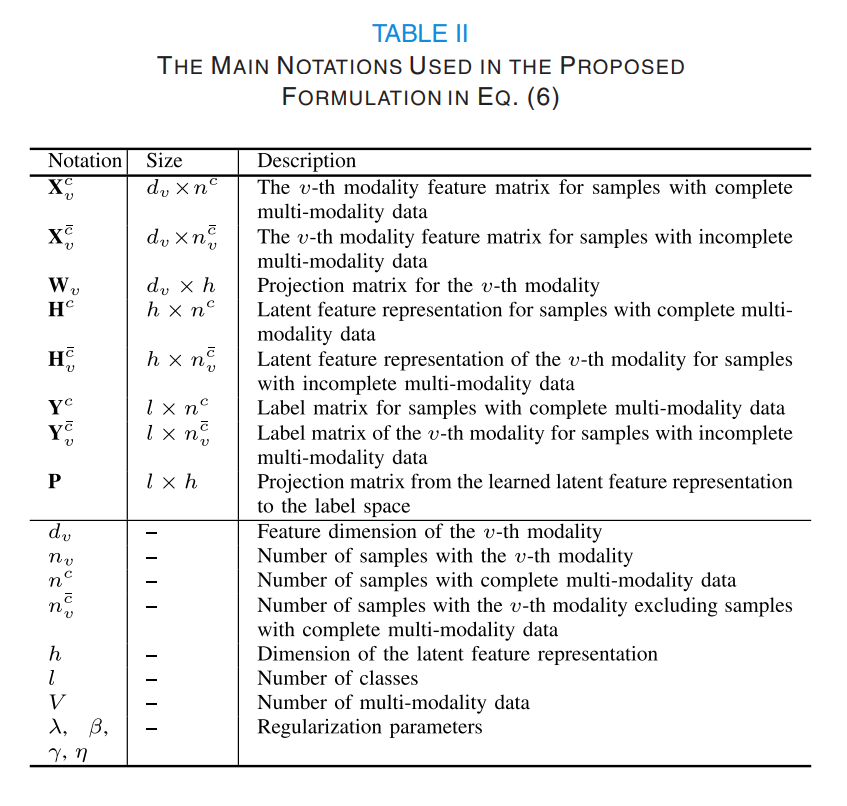
Complete Data Model Formulation
$$\begin{equation} \min_{w_v, e_v, H, P} \frac{1}{2} \|PH-Y\|_F^2 + \lambda \sum_{v=1}^V tr(W_v^T X_v L_v(W_v^T X_v)^T) \\ +\beta \sum_{v=1}^V \| W_v \|_{2,1} + \gamma \sum_{v=1}^V \|E_v\|_1 + \frac{\eta}{2}\|P\|_F^2 \\ \text{s.t. } W_v^T X_v = H+E_v, \forall v \in {1,2, ..., v} \end{equation}$$
$$\begin{equation} L_v = D_v - S_v \text{: Laplacian Matrix} \\ D_v \text{: Diagonal Matrix with its i-th diagonal element denonting the sum of i-th row in }S_v \\ S_v \text{: Similarity matrix for v-th modality, whose (i,j)-th element is given as } exp(-\|X_{v,:i}-X_{v,:j}\|_2^2/\sigma) \\ \sigma=1\text{: Set in this paper} \end{equation}$$
Explain Term
- \(\frac{1}{2} \|PH-Y\|_F^2\): Classification Model의 Loss를 Minimize
- H(Latenet Space) = Common latent representation
- P: Projection Matrix(Weight) form the learned latent feature space(H) to Label Sapce(Y)
- Y: Label Space
- \(\sum_{v=1}^V \| W_v \|_{2,1}, \frac{\eta}{2}\|P\|_F^2\): Weight Regularization
- \(\gamma \sum_{v=1}^V \|E_v\|_1\): Each Modality Classification Model의 Loss를 Minimize
- \(\lambda \sum_{v=1}^V tr(W_v^T X_v L_v(W_v^T X_v)^T)\): Laplacian regularization term, which is added to ensure that similar inputs have similar latent feature representations.
Incomplete Data Model Formulation
위의 Formulation은 Complete Data인 경우의 Model이다. 이를 Incomplete Data Model Formulation으로서 바꾸면 다음과 같다.
$$\begin{equation} \min_{w_v, e_v, H, P} \frac{1}{2} \|P[H^c, H_1^{\bar{c}}, ... , H_v^{\bar{c}}]-[Y^c, Y_1^{\bar{c}}, ... , Y_v^{\bar{c}}]\|_F^2 + \lambda \sum_{v=1}^V tr(W_v^T[X_v^c, X_v^{\bar{c}}] L_v(W_v^T [X_v^c, X_v^{\bar{c}}])^T) \\ +\beta \sum_{v=1}^V \| W_v \|_{2,1} + \gamma \sum_{v=1}^V \|E_v\|_1 + \frac{\eta}{2}\|P\|_F^2 \\ \text{s.t. } W_v^T [X_v^c, X_v^{\bar{c}}] = [H^c, H_v^{\bar{c}}]+E_v, \forall v \in {1,2, ..., v} \end{equation}$$
$$\begin{equation} n_v = n^c + n_v^{\bar{c}} \text{: Total number of samples in v-modality} \\ n^c \text{: The number of complete multi-modality data} \\ \end{equation}$$
Optimization and Model Prediction
Augmented Lagrange Multiplier(ALM)사용 나중에 공부하고 확인 => Supplement에 수식 참조
Appendix. Laplacian regularization term
Laplacian Regularization은 Graph Theory에서 많이 사용된다. Graph Theory에서 사용되는 예시를 살펴보면 다음과 같다.
- L = D-W: Unnormalization Graph Laplacian
- W: Adjacency Matrix
- D: Diagonal Matrix (Sum of W’s row)
Example)
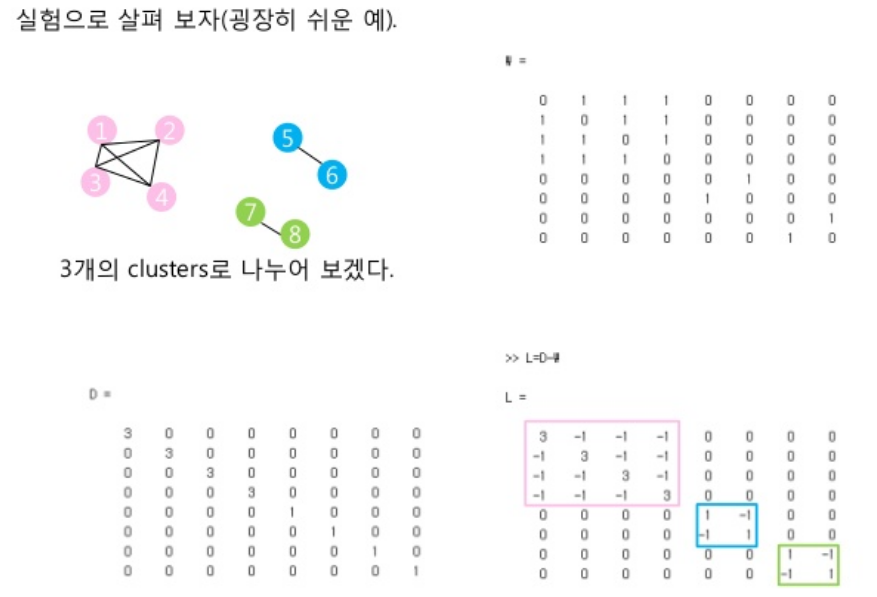
참조: Slideshare
위에 Laplacian Regularization Term(Complete data model formulation) \(\lambda \sum_{v=1}^V tr(W_v^T X_v L_v(W_v^T X_v)^T)\)에서 Laplacian Matrix(\(L_v\))를 제외하게 되면, 간단한 Matrix Norm이다. 하지만, Laplacian Matrix를 Original Matrix(X)와 Correlation정도를 나타냄으로서 하나의 Filter처럼 역할을 하여서 Input과 Latent feature representations(\(W_v^T X_v\))와 Similar해 질 것이다. 여기서 Similar라는 표현은 Input과 Latent feature representation값이 비슷한 것이 아니라, 각각의 Element끼리의 Correlation이 비슷하게 유지될 것 이다.
Experiment
Setup
- Baseline: Experiement using only the original features without performing any feature selection
- Classification: SVM by LIBSVM toolbox(except iMSF, MSC)
- 10 Cross Validation * 50 => Avoid possible bian in dataset partitioning during cross-validation
Classification Results Using Complete Multi-Modality Data
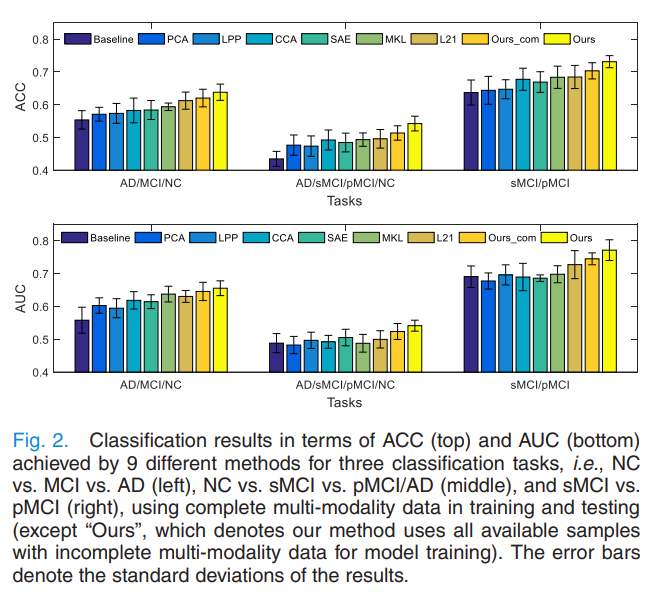 Problem 1. Not all the subjects have complete multi-modality data. One simple solution used by many previous studies is to discard samples with missing modalities. However, this significantly reduces the number of training samples, thus leading to a sub-optimal classification model.
Problem 1. Not all the subjects have complete multi-modality data. One simple solution used by many previous studies is to discard samples with missing modalities. However, this significantly reduces the number of training samples, thus leading to a sub-optimal classification model.
- Ours_com: Our proposed method that uses the samples with only comlete multi-modality data to train a model
- Ours: Proposed method that uses all available samples (including the samples with incomplete multi-modalities)
기존의 다른 방법이였던, Feature Reduction or Feature Selection을 통하여 Model을 Trainning하였을 때 뿐만 아니라, Association을 나타낼 수 있는 Model보다도 성능이 잘 나왔다. 더 주목해야 하는 결과는 Ours_com 보다 Ours가 Performance도 높으면서 가장 좋은 성능을 보여주고 있다. 즉, Paper Probelm1에서 주장하였던 Incomplete Dataset을 사용하여 Classfication Model의 Performance향상을 보여주었다.
Classification Results using Incomplete Multi-Modality Data
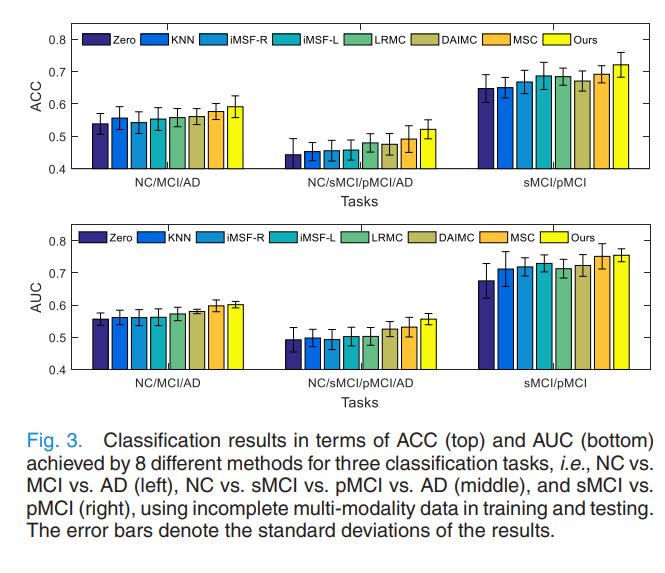 Problem 2. As features from different modalities are often closely related … utilizing their inter-modality associations may improve the robustness of the diagnostic model.
Problem 2. As features from different modalities are often closely related … utilizing their inter-modality associations may improve the robustness of the diagnostic model.
Probelm2에서는 Data imputation techniques로서 Missing Data를 Prediction할 수 있으나, 결국 Noisy가 발생한다고 주장하였다. 따라서 해당 Paper는 incomplete data는 specific modality latenet space를 Training하는데 사용되고, complete data는 common latenet space를 Training하게 Modeling하여 다른 방법들보다 성능이 향상 된 것을 알 수 있다.
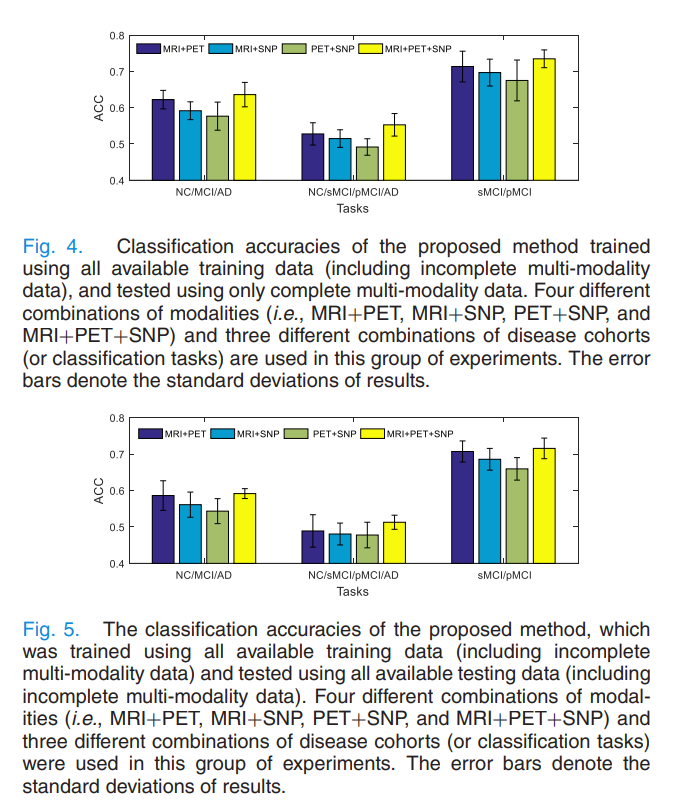
- Fig4. Results with only complete multi-modality testing data
- Fig5. Results with incomplete multi-modality testing data
결과를 살펴보게 되면, PET+MRI를 사용하였을 경우 높은 Performance를 보여주고 SNP Modality를 추가하여도 Model의 성능은 향상되는 것을 살펴볼 수 있다. 즉, 단순한 Concat이 아닌, SNP의 Specific Latent Space와 Interaction Space를 Label Space에 바로 Mapping하게 하여 다른 Modality와의 Interactio을 고려하게 되어 Performance가 향상된 것으로 추정된다.
Result
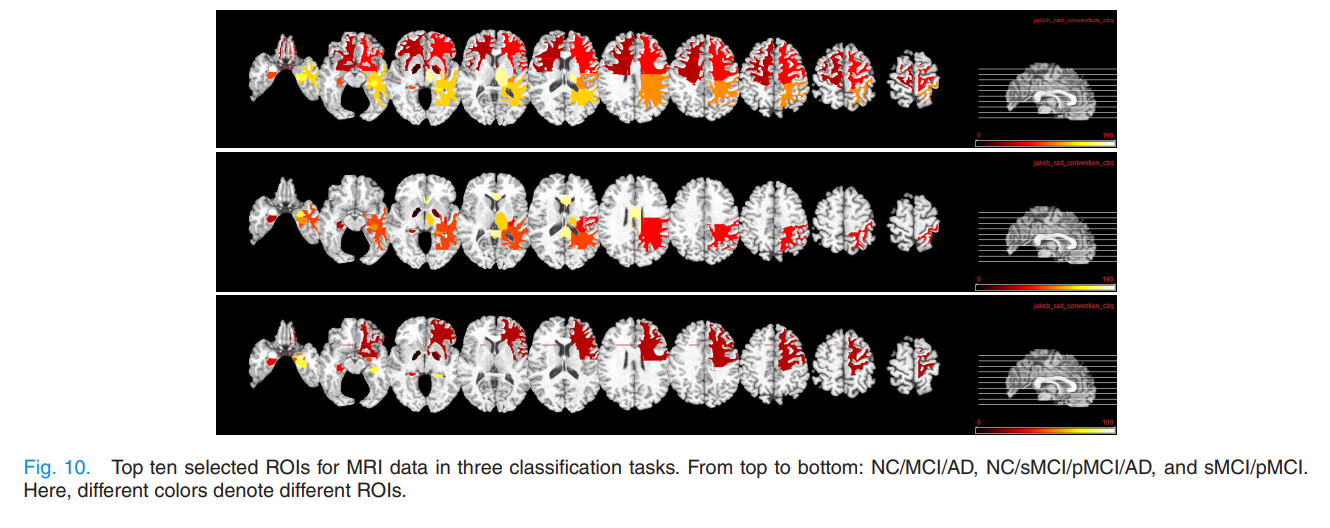
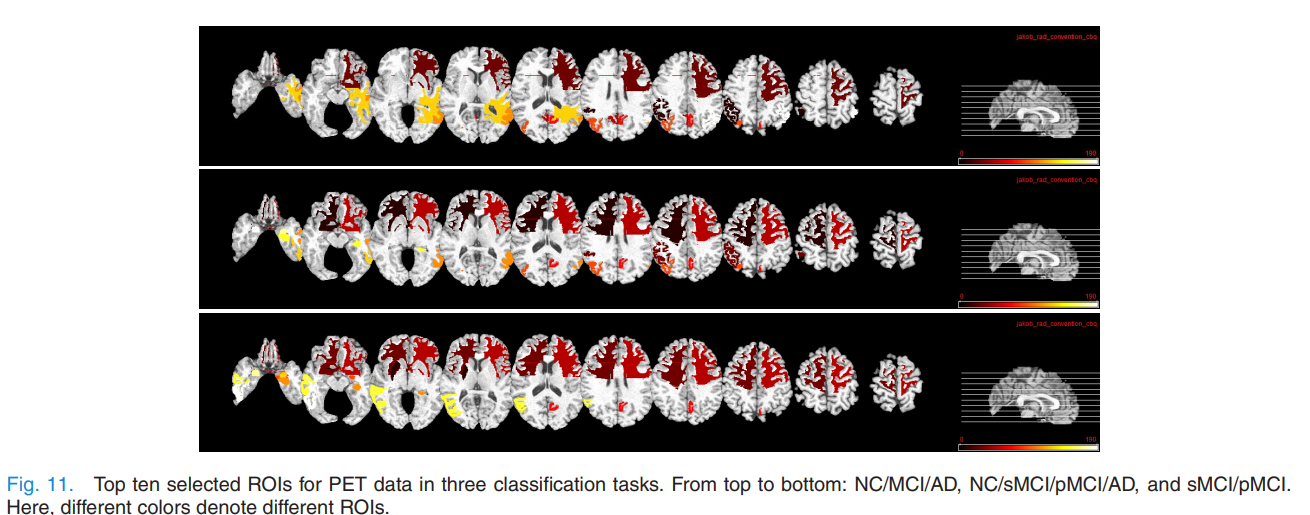
Most Related ROIs and SNPs
Object Function에서 \(\beta \sum_{v=1}^V \| W_v \|_{2,1}\)을 살펴보게 되면, 각각의 Modality Latent Space에 Mapping시키는 Weight에 대하여 L2,1 Normalization을 적용하였다.
따라서 \(W_v\)는 값이 매우 작거나, 0의 값을 가질 것 이다. 이러한 Weight의 크기를 Rank로서 뽑은 Modality의 Feature Top10은 다음과 같다.
PET And MRI
SNP Top5 List
We further report the top five discriminative SNPs that are most frequently identified by our method, which include rs429358, rs10740220, rs2298525, rs7073924, and rs11655156.
- rs429358: APOE
- rs10740220: CTNNA3
- rs2298525: SORL1
- rs7073924: rs7073924
- rs10740220: CTNNA3
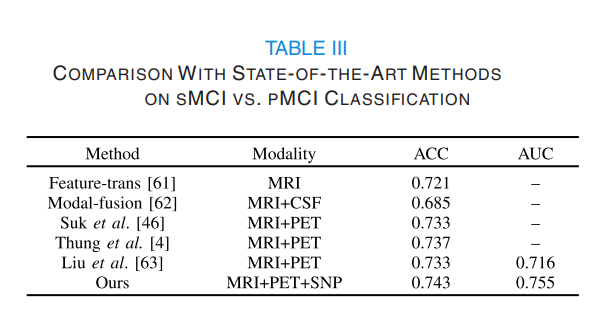
Comparison with state of the art methods on sMCI vs pMCI Classification
Limitation
- Linear Combination이므로 Complex한 Brain Pattern을 잘 찾아내지는 못할 것 이다. => Non-Linear한 Model로서 구성하게 되면 훨씬 향상 될 것이다.
- Deep Learning FrameWork를 사용하여 Incomplete multi-modality data를 사용하는 방법을 찾으면 더 Performance가 향상 될 것 이다. (단순히 Modality Specific latent representation을 Training하는 것이 아닌)
참조: Latent Representation Learning for Alzheimer’s Disease Diagnosis With Incomplete Multi-Modality Neuroimaging and Genetic Data
코드에 문제가 있거나 궁금한 점이 있으면 wjddyd66@naver.com으로 Mail을 남겨주세요.
Leave a comment